WavThruVec_pytorch
1.0.0
Implementasi tidak resmi Wavtruvec berdasarkan Pytorch.
Makalah Asli adalah Wavthruvec: Representasi Pidato Laten sebagai Fitur Menengah untuk Sintesis Bicara Saraf
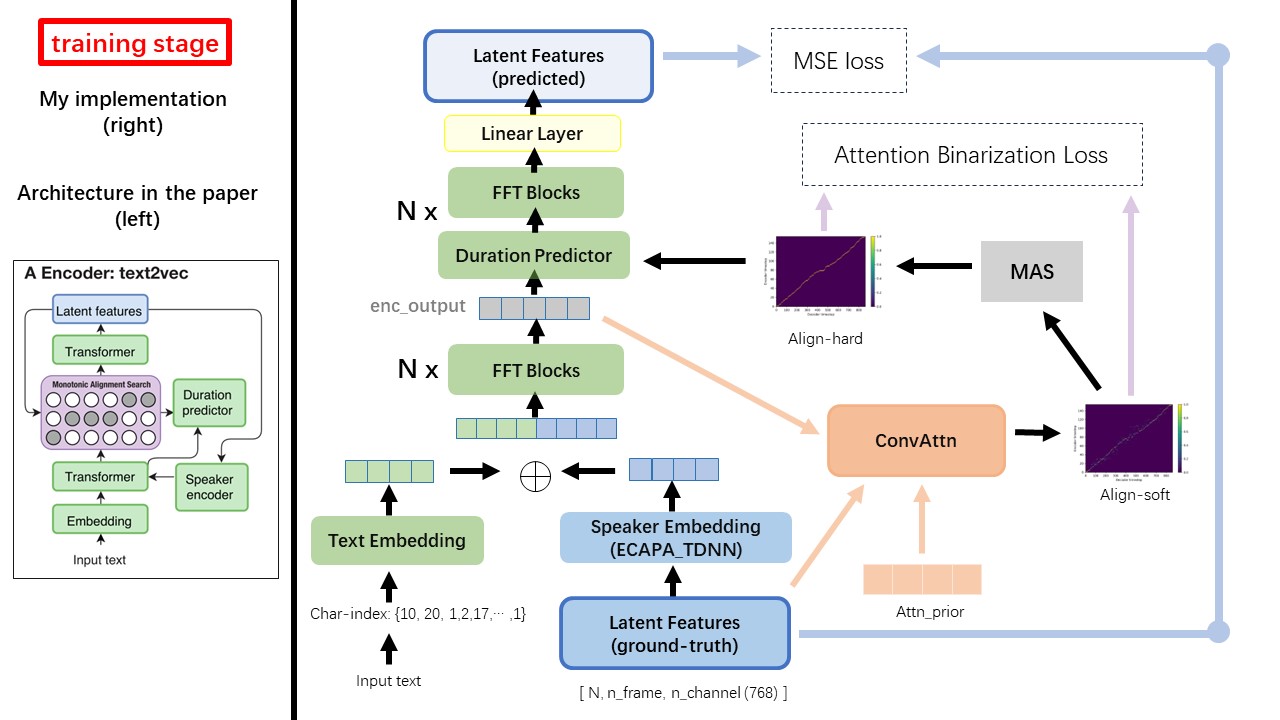
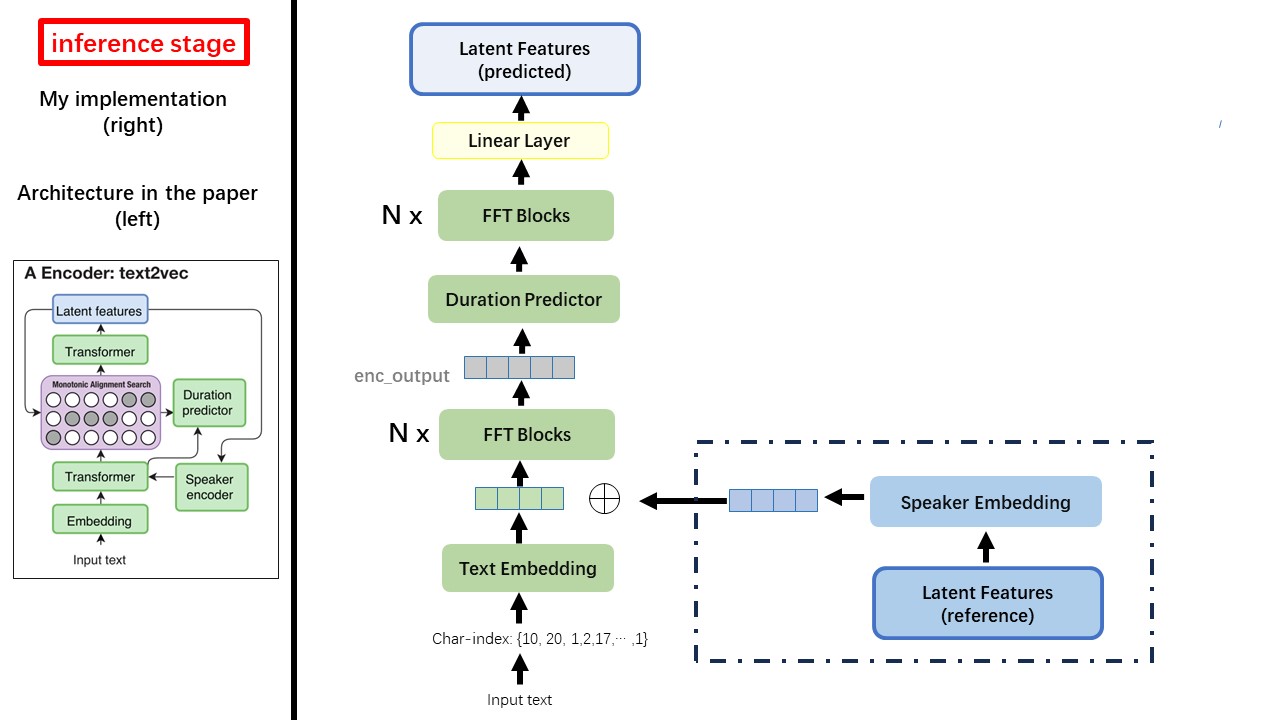
Model Text2Vec sebagian besar mengikuti arsitektur FastSpeech (XCMYZ). Saya memodifikasi model, terutama berdasarkan RAD-TTS (NVIDIA). Dan saya menambahkan ECAPA_TDNN sebagai encoder speaker, untuk kondisi multi-speaker.
Untuk detail lain yang tidak disebutkan di koran, saya juga mengikuti RAD-TTS.
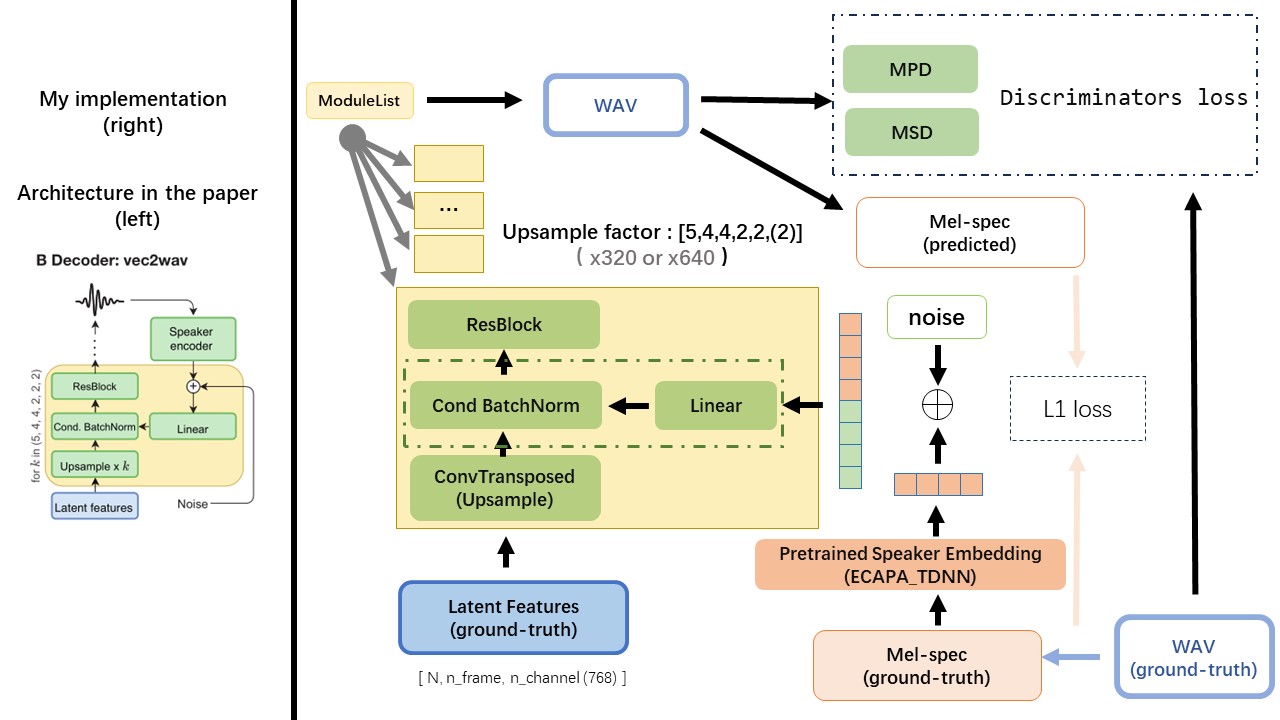
VEC2WAV sebagian besar didasarkan pada Hifi-Gan, dan memperkenalkan normalisasi batch bersyarat untuk mengkondisikan jaringan pada penyematan speaker. Urutan laju upsample adalah (5,4,4,2,2) sehingga faktor upampling adalah
Jangan gunakan metode normalisasi teks atau fonemisasi berbasis aturan, tetapi pakan karakter mentah dan bertransformasi menjadi input teks sebagai input.
Gunakan output WAV2VEC 2.0 sebagai fitur WAV (bukan Spectrogram MEL), dengan dtype 'float32' dan bentuk (batch_size, n_frame, n_channel) .
CATATAN: N_CHANNEL = 768 atau 1024, itu tergantung pada versi mana dari model pretrain WAV2VEC 2.0 yang Anda gunakan, karena tencentGamemate menyediakan fairseq-versi (768) dan versi huggingface (1024). Dua versi ini memiliki bentuk output yang berbeda.
Dari repositori ini wav2vec2.0 (pretrain pidato Cina), dan juga dapat ditemukan di huggingface
Salah satu perbedaan terbesar antara Wavtruvec dan FastSpeech adalah modul pencarian Alignment Monotonic (MAS) (lihat alignment.py ).
Di FastSpeech, input pelatihan termasuk penyelarasan yang memaksa guru untuk bingkai MEL dan token teks. Secara khusus, ini melibatkan penggunaan MFA untuk menghasilkan duration bingkai MEL untuk setiap token teks sebelum pelatihan.
Saat berada di Wavtruvec, duration dihasilkan menggunakan MAS dari RAD-TTS, dan dimasukkan ke dalam panjang regulator (durasi prediktor).
Menurut pencarian penyelarasan monotonik dan implementasi RAD-TTS, ketika Anda melatih model, align-prior file akan dihasilkan di bawah './data/align_prior' direktori, dengan format nama file {n_token}_{n_feat}_prior.pth .
Aishell3
Siapkan_data.py:
Sebagai contoh, persiapan_data.py hanya ambil beberapa speaker dan beberapa file WAV.
Kontrain WAVTHUVEC 2 Komponen: Text2Vec (Encoder) dan Vec2Wav (Decoder), dan mereka berlatih secara mandiri
Dengan demikian, saya menempatkannya di dua Dirs terpisah dan menggunakan konfigurasi pelatihan yang berbeda untuk masing -masing.
Pencari Tensorboard disimpan di direktori run/{log_seed}/tb_logs . Misalkan log_seed=1 , Anda dapat menggunakan perintah ini untuk melayani papan tensor di localhost Anda.
tensorboard --logdir run/1/tb_logs
Pos pemeriksaan model disimpan di direktori run/{log_seed}/model_new .
Misalkan Anda menyimpan pos pemeriksaan setiap 10000 iterasi, dan sekarang Anda memiliki pos pemeriksaan checkpoint_10000.pth.tar . Jika Anda perlu memulai kembali pelatihan pada step 10000 , maka gunakan perintah ini.
python ./text2vec/train.py --restore_step 10000


