WavThruVec_pytorch
1.0.0
Uma implementação não oficial de Wavthruvec baseada em Pytorch.
O artigo original é Wavthruvec: representação latente da fala como características intermediárias para a síntese de fala neural
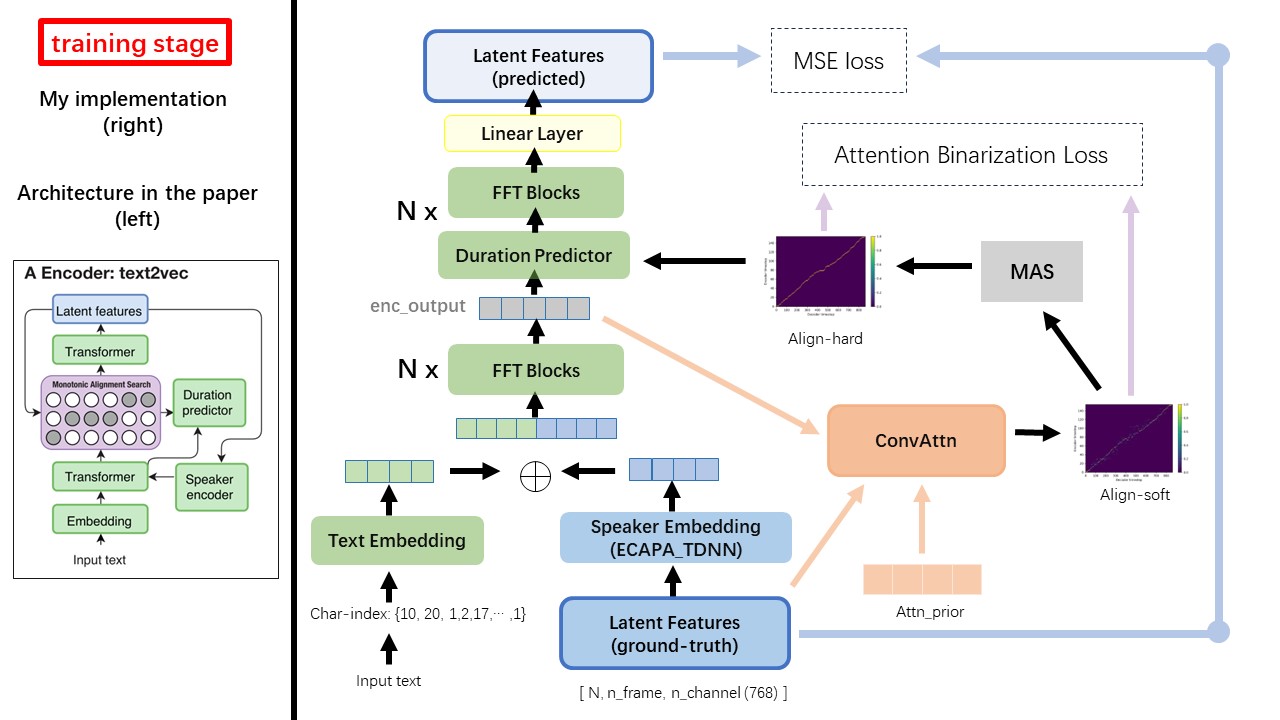
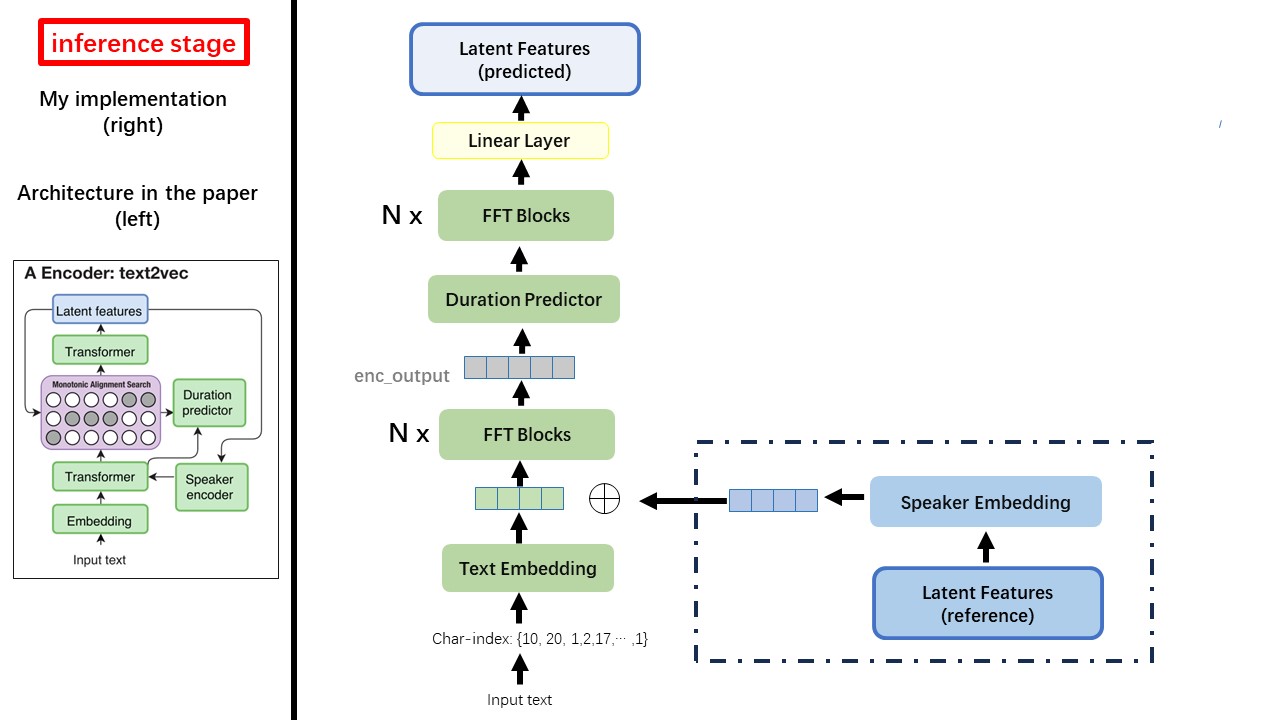
O modelo Text2Vec segue principalmente a arquitetura FastSpeech (XCMYZ). Modifiquei o modelo, principalmente com base no RAD-TTS (NVIDIA's). E adiciono um ECAPA_TDNN como codificador de alto-falante, para uma condição de vários falantes.
Para outros detalhes não mencionados no artigo, também sigo os RAD-TTS.
O VEC2WAV é baseado principalmente no HIFI-GAN e introduz a normalização do lote condicional para condicionar a rede na incorporação do alto-falante. A sequência das taxas de UPSOMSOM é (5,4,4,2,2), de modo que o fator de amostragem é
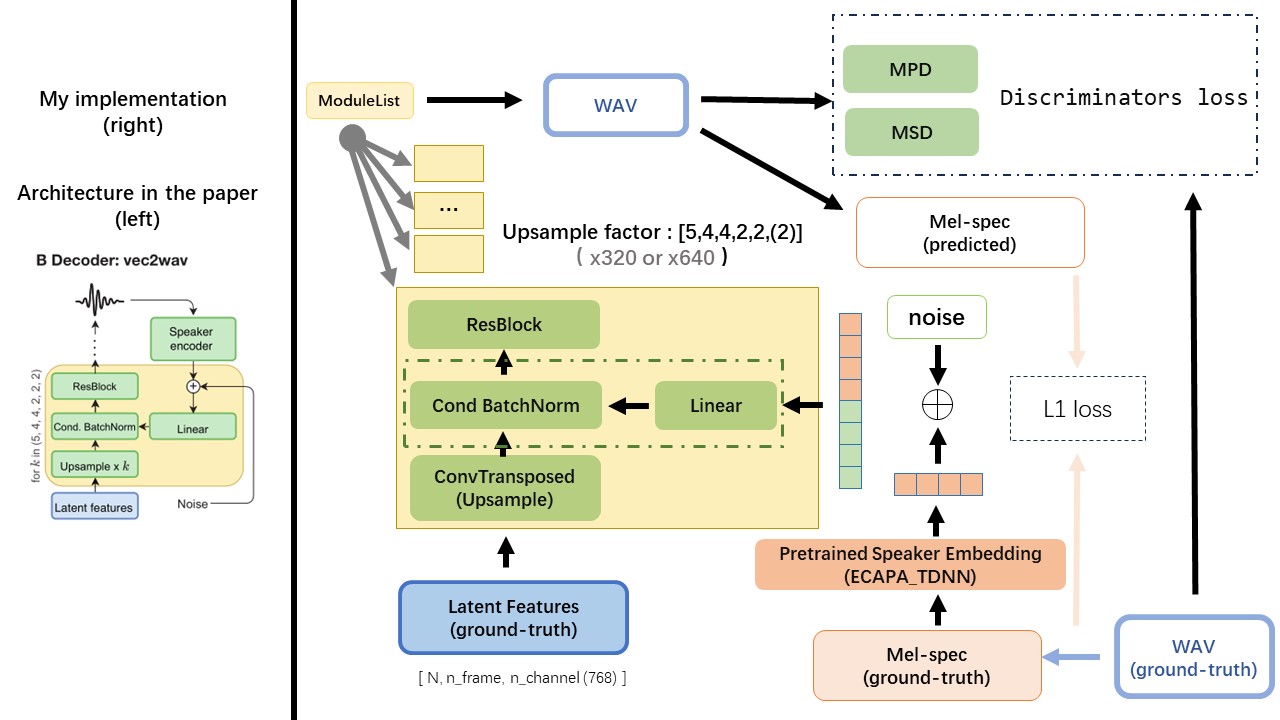
Não use nenhum método de normalização de texto baseado em regras ou fonemização, mas alimente o caractere bruto e transforme-o em incorporação de texto como entradas.
Use a saída do WAV2VEC 2.0 como o recurso do WAV (em vez do espectrograma MEL), com um dtype de 'float32' e uma forma de (batch_size, n_frame, n_channel) .
Nota: n_Channel = 768 ou 1024, depende de qual versão do modelo pré-terenciado WAV2VEC 2.0 você está usando, porque o tencentgamemate fornece Fairseq-Version (768) e HuggingFace-Versão (1024). Essas duas versões têm uma forma de saída diferente.
A partir deste repositório wav2vec2.0 (discurso chinês pré -atreta), e também pode ser encontrado no huggingface
Uma das maiores diferenças entre Wavthruvec e FastSpeech é o módulo Monotonic Alignment Search (MAS) (consulte o alignment.py ).
No FastSpeech, os insumos de treinamento incluem o alinhamento de forças de professores para quadros MEL e tokens de texto. Especificamente, envolve o uso de MFA para gerar a duration dos quadros MEL para cada token de texto antes do treinamento.
Enquanto estiver em Wavthruvec, a duration é gerada usando o MAS a partir do RAD-TTS e é alimentada no regulador de comprimento (DurationPredictor).
De acordo com a Pesquisa de Alinhamento Monotônico e a implementação do RAD-TTS, ao treinar o modelo, os arquivos alinhados serão gerados em './data/align_prior' diretório, com o formato de nome do arquivo de {n_token}_{n_feat}_prior.pth .
Aishell3
O prepare_data.py:
Como exemplo, prepare_data.py pegue apenas alguns alto -falantes e alguns arquivos WAV.
Wavthruvec contém 2 componentes: text2vec (codificador) e vec2wav (decodificador), e eles treinam independentemente
Assim, eu os coloquei em dois diretores separados e usei diferentes configurações de treinamento para cada uma.
Os loggers do Tensorboard são armazenados no diretório run/{log_seed}/tb_logs . Suponha que log_seed=1 , você pode usar este comando para servir o Tensorboard em sua localhost.
tensorboard --logdir run/1/tb_logs
Os pontos de verificação do modelo são salvos no diretório run/{log_seed}/model_new .
Suponha que você economize pontos de verificação a cada 10000 iterações e agora você tem um ponto de verificação checkpoint_10000.pth.tar . Se você precisar reiniciar o treinamento na step 10000 , use este comando.
python ./text2vec/train.py --restore_step 10000


