WavThruVec_pytorch
1.0.0
Pytorchに基づくWavthruvecの非公式の実装。
元の論文は、神経音声合成の中間特徴としての潜在音声表現です。
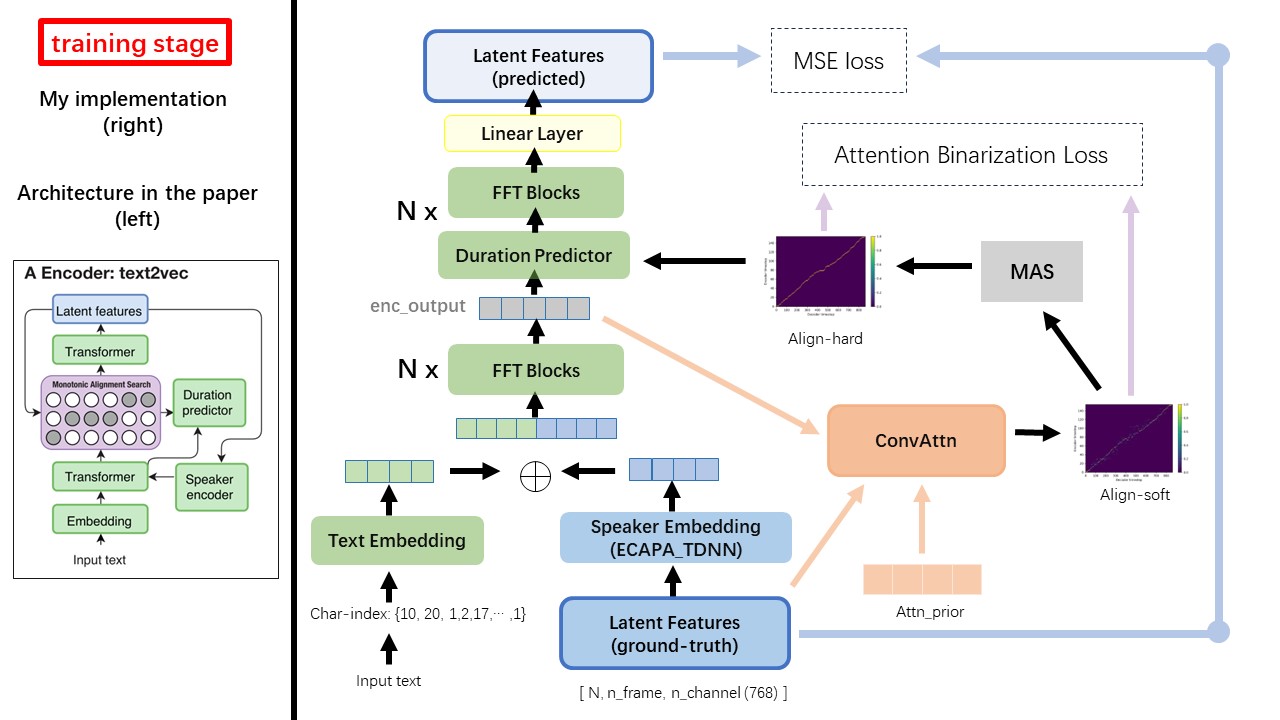
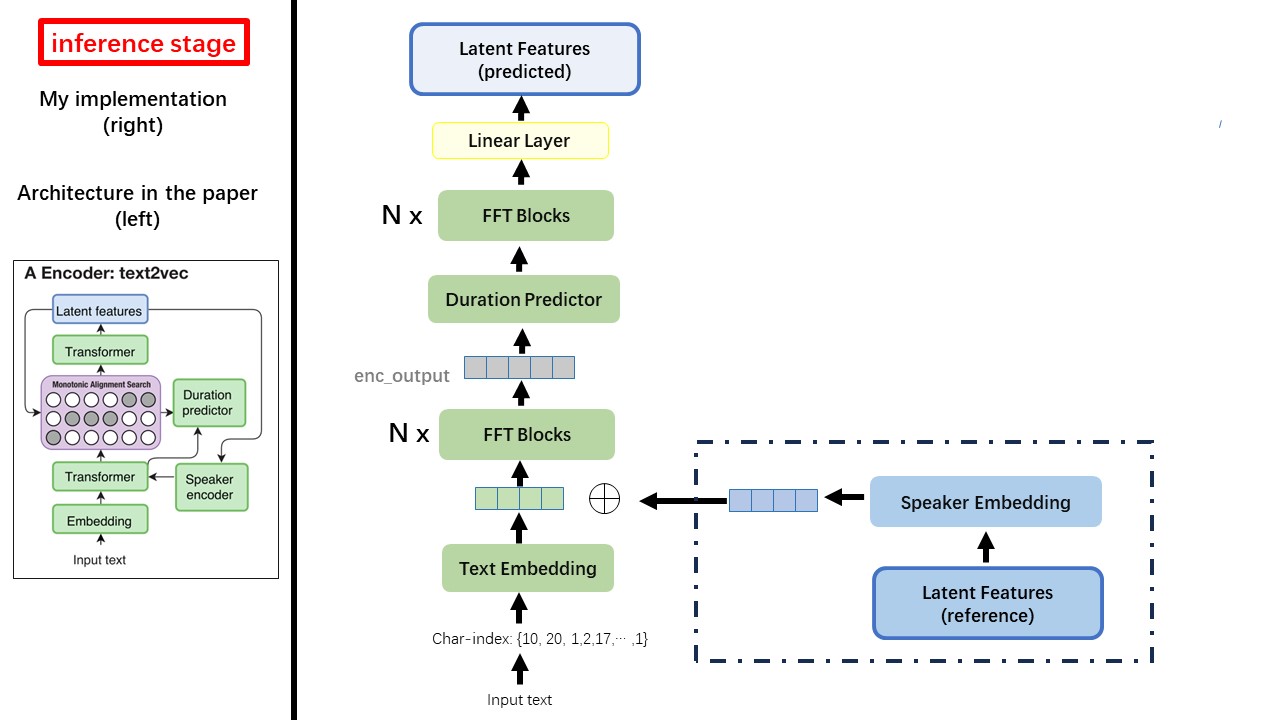
Text2Vecモデルは、主にFastSpeech(XCMYZ)アーキテクチャに従います。主にRad-TT(Nvidiaの)に基づいて、モデルを変更しました。また、マルチスピーカー条件のために、スピーカーエンコーダーとしてECAPA_TDNNを追加します。
論文で言及されていないその他の詳細については、Rad-TTSにも従います。
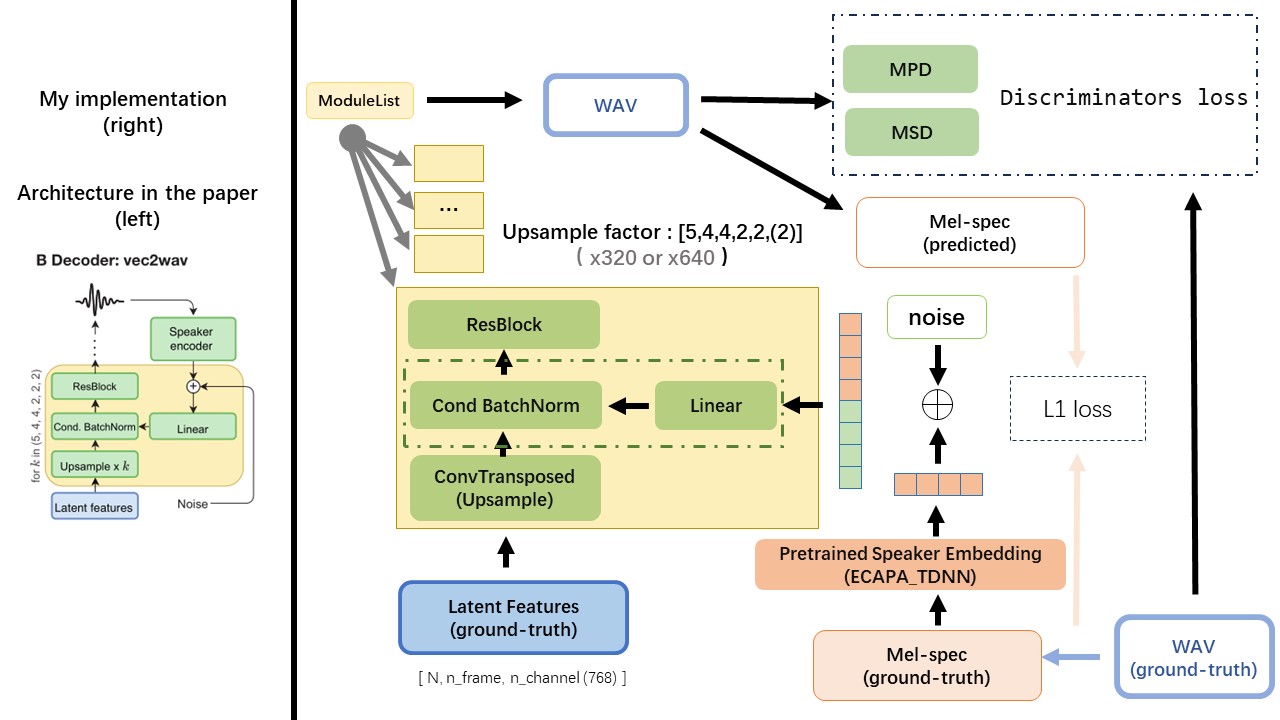
VEC2WAVは主にHIFI-GANに基づいており、条件付きバッチ正規化を導入して、スピーカーの埋め込み上のネットワークを条件付けます。アップサンプルレートシーケンスは(5,4,4,2,2)であるため、アップサンプリング係数は
ルールベースのテキストの正規化や音素化方法を使用しないでください。生の文字を供給し、入力としてテキスト埋め込みに変換してください。
WAV2VEC 2.0の出力を使用して(MEL Spectrogramの代わりに)WAVの機能として、 'float32'のdtypeと(batch_size, n_frame, n_channel)の形状を使用します。
注:n_channel = 768または1024、TencentgamemateはFairSeq-version(768)とHuggingface-version(1024)を提供するため、使用しているWAV2VEC 2.0の前提型モデルのバージョンに依存します。これらの2つのバージョンの出力形状は異なります。
このリポジトリからwav2vec2.0(中国の音声前)、そしてそれはハグイングフェイスでも見つけることができます
WavthruvecとFastSpeechの最大の違いの1つは、単調アライメント検索(MAS)モジュールです( alignment.pyを参照)。
FastSpeechでは、トレーニング入力には、MELフレームとテキストトークンの教師向けのアライメントが含まれます。具体的には、MFAを使用して、トレーニング前に各テキストトークンのMELフレームのdurationを生成することが含まれます。
WAVTHRUVECでは、 durationはRAD-TTSのMASを使用して生成され、長さのレジュレータ(DurationPredictor)に供給されます。
単調なアライメント検索とRAD-TTS実装によれば、モデルをトレーニングすると、 {n_token}_{n_feat}_prior.pthのファイル名形式を使用して、 './data/align_prior'ディレクトリの下でAlignpriorファイルが生成されます。
aishell3
prepare_data.py:
例として、prepare_data.pyスピーカーといくつかのWAVファイルのみを取得します。
wavthruvecは2つのコンポーネントを呼び起こします:text2vec(encoder)とvec2wav(decoder)、そしてそれらは独立してトレーニングします
したがって、それらを2つの別々の監督に配置し、それぞれに異なるトレーニング構成を使用しました。
テンソルボードロガーはrun/{log_seed}/tb_logsディレクトリに保存されます。 log_seed=1を使用して、このコマンドを使用して、ローカルホストのテンソルボードを提供できます。
tensorboard --logdir run/1/tb_logs
モデルチェックポイントはrun/{log_seed}/model_newディレクトリに保存されます。
10000回の反復ごとにチェックポイントを保存すると、チェックポイントcheckpoint_10000.pth.tarがあるとします。 step 10000でトレーニングを再起動する必要がある場合は、このコマンドを使用してください。
python ./text2vec/train.py --restore_step 10000


