STYLER
v1.0.0
在我們的論文中,我們提出了Styler,這是一種非自動回歸TTS框架,具有樣式因子建模,可同時實現速度,魯棒性,表現性和可控性。
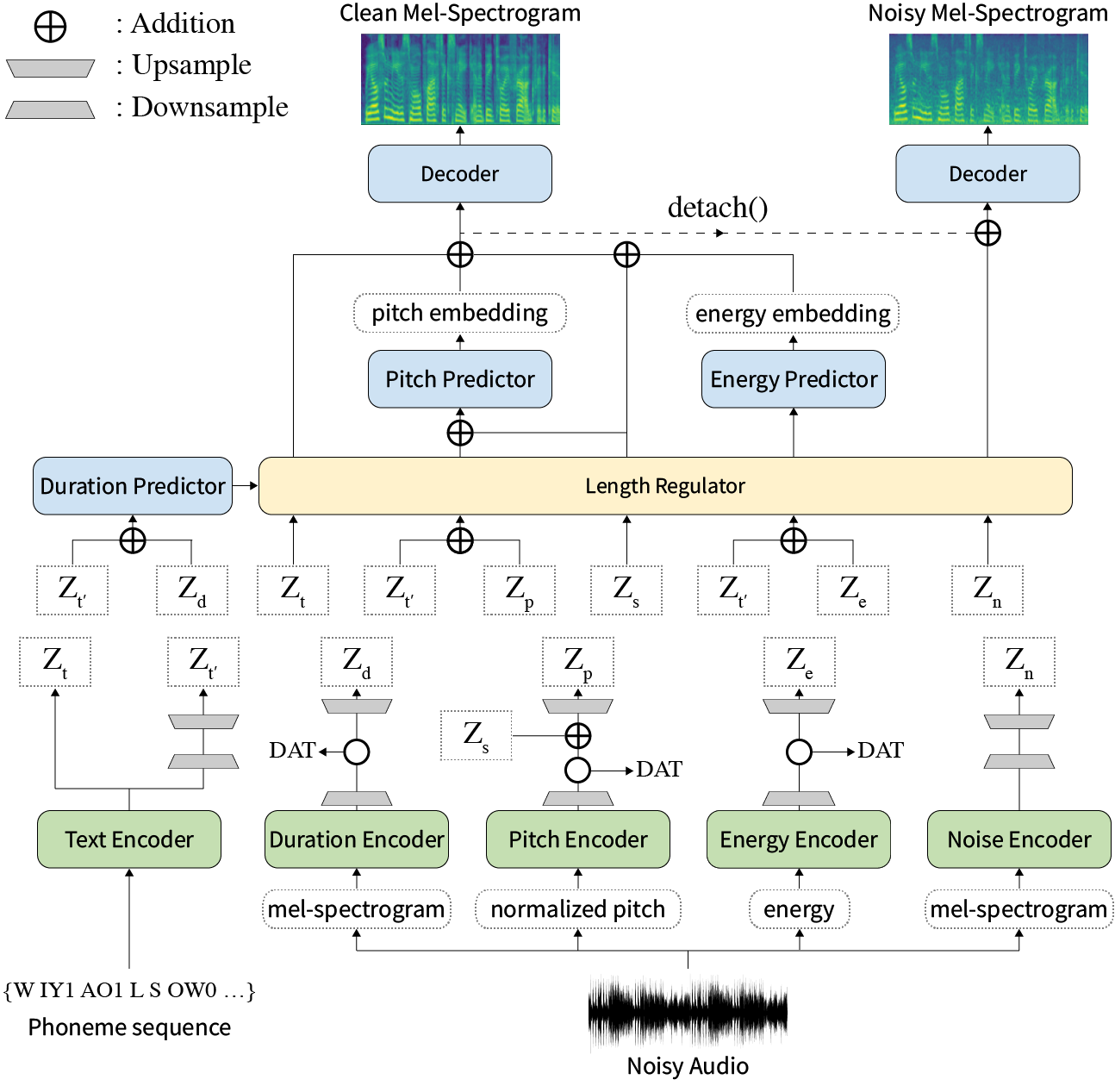
摘要:關於神經文本到語音(TTS)的先前著作已在訓練和推理時間有限的速度,難度綜合條件,表現力和可控性方面的穩健性。儘管幾種方法可以解決一些局限性,但沒有嘗試一次解決所有弱點。在本文中,我們提出了一種具有高速和穩健合成的表現力和可控制的TTS框架。我們的新型音頻文本對齊方法稱為MEL校準器,排除自回歸解碼可以使快速訓練,推理以及對看不見的數據的魯棒合成。此外,在監督下進行解開的樣式因子建模擴大了綜合過程中的可控性,從而導致表達性TT。最重要的是,使用域對抗訓練和殘留解碼的新型噪聲建模管道賦予了噪聲風格的傳遞,使噪聲分解了噪聲,而無需任何其他標籤。各種實驗表明,與自動回歸解碼的表達性TT相比,與閱讀樣式的非自動回報式TTS相比,造型器在速度和魯棒性上更有效。合成樣本和實驗結果通過我們的演示頁面提供,代碼可公開使用。
您可以下載據預貼模型。
請安裝requirements.txt中給出的python依賴項。
pip3 install -r requirements.txtdata/resample.sh 。hparams.py中的hp.data_dir 。hparams.py中的hp.noise_dir 。hifigan/generator_universal.pth.tar.zip在同一目錄中。 首先,下載Recknn SoftMax+三重預讀的Philipperemy DeepSpeaker的揚聲器嵌入模型,如我們的論文所述,並在hp.speaker_embedder_dir中找到它。
其次,通過以下命令下載蒙特利爾強制對準器(MFA)軟件包和驗證的(librispeech)詞典文件。 MFA用於以FastSpeech2的形式獲得話語和音素序列之間的比對。
wget https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner/releases/download/v1.1.0-beta.2/montreal-forced-aligner_linux.tar.gz
tar -zxvf montreal-forced-aligner_linux.tar.gz
wget http://www.openslr.org/resources/11/librispeech-lexicon.txt -O montreal-forced-aligner/pretrained_models/librispeech-lexicon.txt然後,處理所有必要的功能。您將在stat.txt th hp.preprocessed_path/ 。您必鬚根據stat.txt的內容修改hparams.py中的F0和能量參數。
python3 preprocess.py最後,通過將每個話語與WHAM隨機選擇的背景噪聲混合在一起,將嘈雜的數據與乾淨的數據分開獲取!數據集。
python3 preprocess_noisy.py現在您擁有所有先決條件!使用以下命令訓練模型:
python3 train.py在data/中創建sentences.py sentences請注意, sentences可以包含多個文本。
# In 'data/sentences.py',
sentences = [
" Nothing is lost, everything is recycled. "
]參考音頻準備與培訓數據準備相似的過程。可能有兩種參考:乾淨和嘈雜。
首先,將帶有相應文本的干淨音頻放在單個目錄中,然後在hparams.py中修改hp.ref_audio_dir ,然後處理所有必要的功能。請參閱Train Preparation的Clean Data部分。
python3 preprocess_refs.py然後,獲取嘈雜的參考。
python3 preprocess_noisy.py --refs以下命令將hp.ref_audio_dir data/sentences.py中的所有文本組合。
python3 synthesize.py --ckpt CHECKPOINT_PATH或者,您可以在hp.ref_audio_dir中指定單個參考音頻。
python3 synthesize.py --ckpt CHECKPOINT_PATH --ref_name AUDIO_FILENAME另外,還有幾個有用的選項。
--speaker_id將指定揚聲器。指定的說話者的嵌入應在hp.preprocessed_path/spker_embed中。默認值None ,並且在每個輸入音頻的運行時計算說話者嵌入。
--inspection將為您提供其他輸出,以顯示Styler每個編碼器的效果。樣本與我們的演示頁面上的Style Factor Modeling部分相同。
--cont將在我們的演示頁面上生成樣本作為Style Factor Control部分。
python3 synthesize.py --ckpt CHECKPOINT_PATH --cont --r1 AUDIO_FILENAME_1 --r2 AUDIO_FILENAME_1請注意, --cont選項僅處理預處理數據。詳細說明,音頻的名稱應具有與VCTK數據集相同的格式(例如,p323_229),並且預處理的數據必須存在於hp.preprocessed_path中。
張板記錄器存儲在log目錄中。使用
tensorboard --logdir log在您的本地主機上提供張板。以下是在VCTK上以560k步驟進行模型培訓的一些記錄視圖。
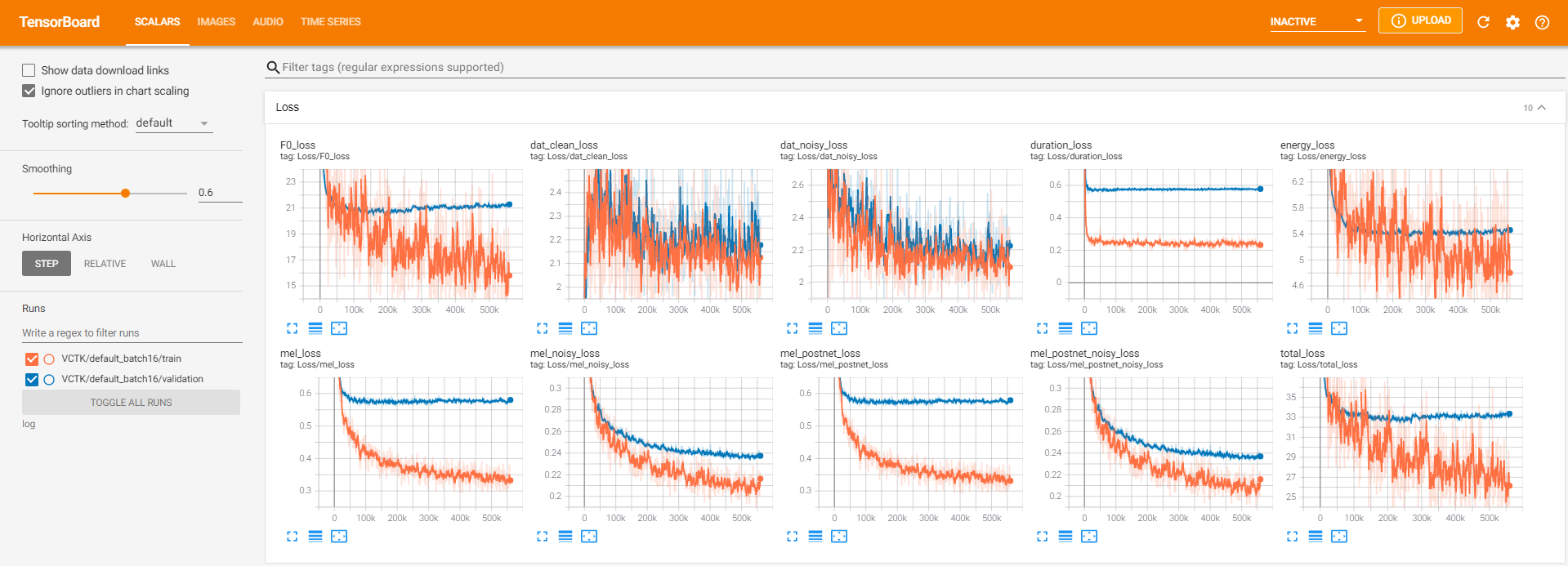
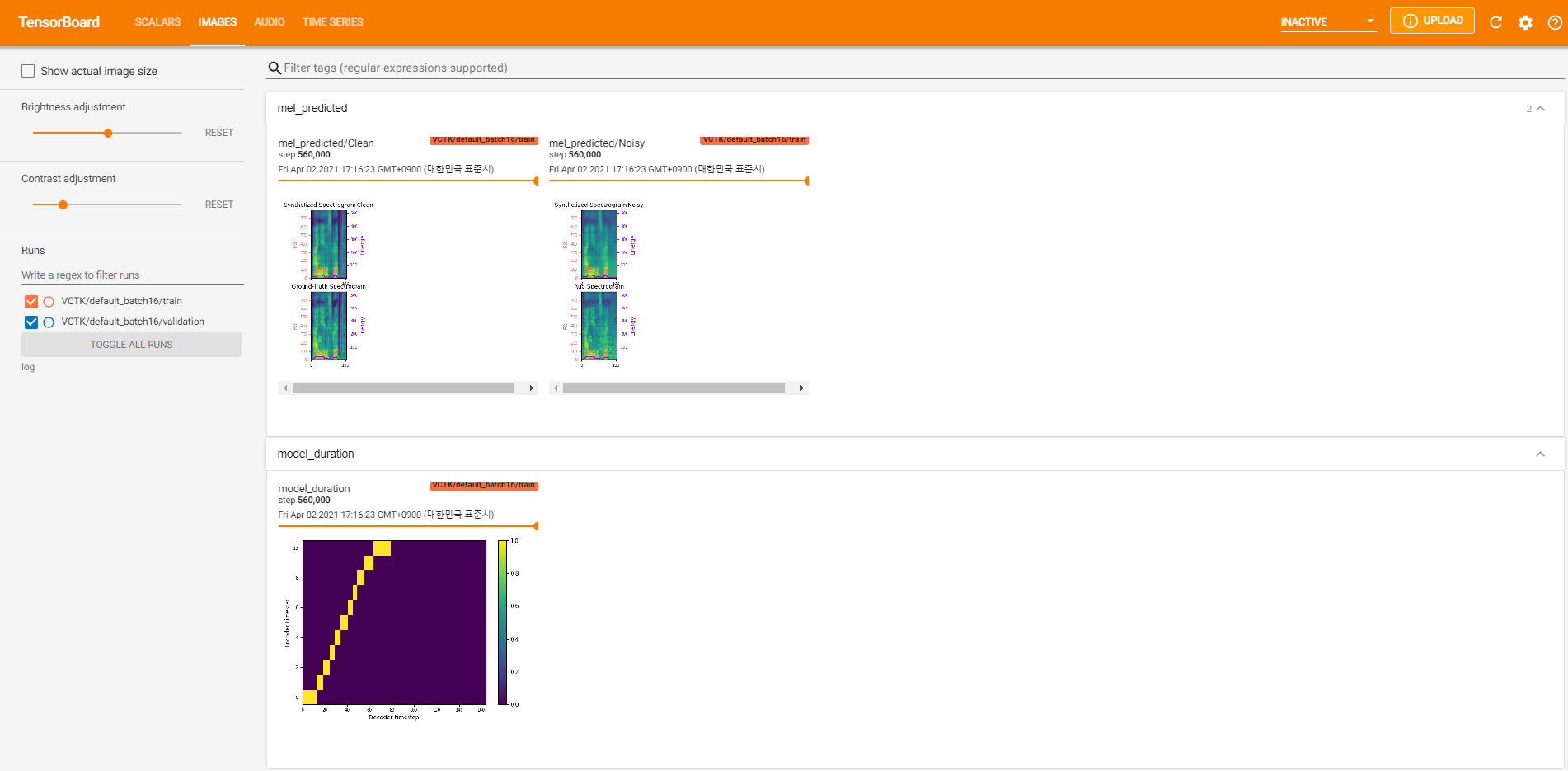
與乾淨的數據一樣,有太多的噪聲數據可以通過pyworld進行提取。為了解決這個問題, pysptk用於提取噪聲數據的基本頻率的Log F0。 --noisy_input選項將在合成過程中自動化此過程。
如果在運行preprocess.py期間發生與MFA相關的問題,請嘗試通過以下命令手動運行MFA。
# Replace $data_dir and $PREPROCESSED_PATH with ./VCTK-Corpus-92/wav48_silence_trimmed and ./preprocessed/VCTK/TextGrid, for example
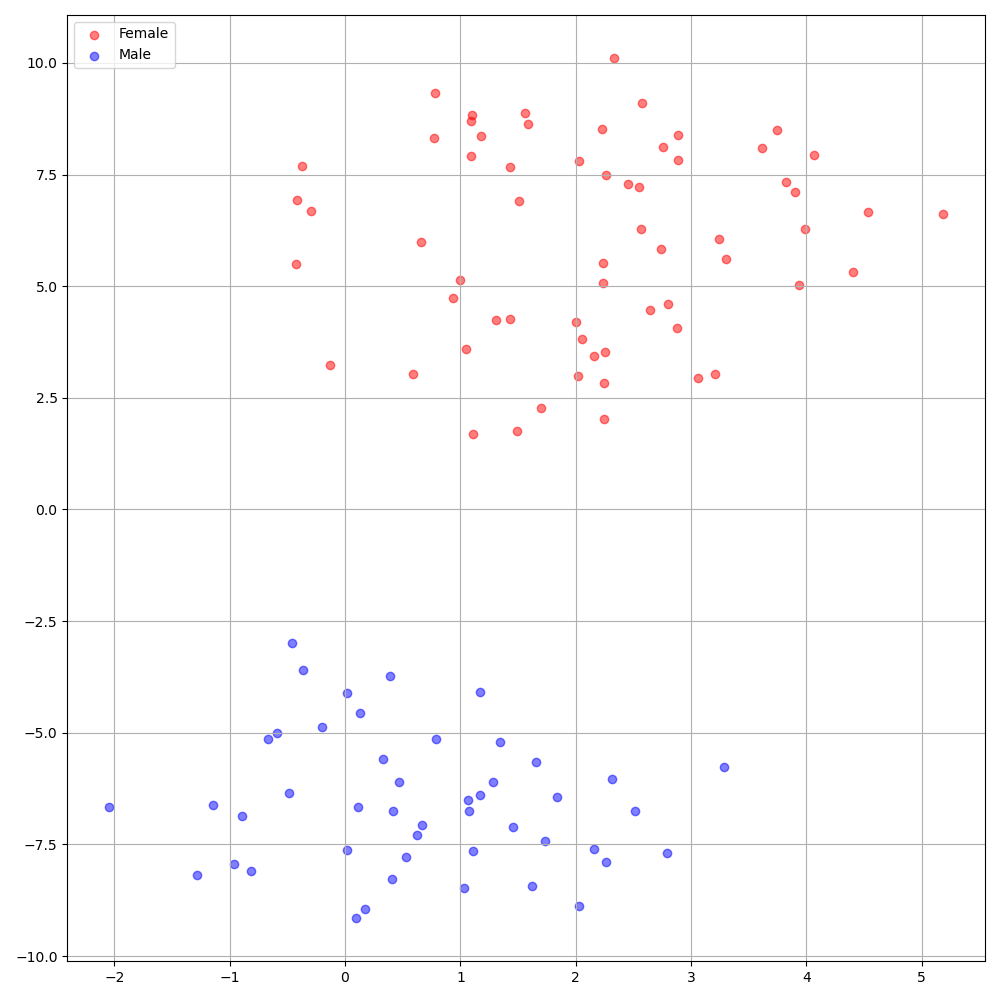
./montreal-forced-aligner/bin/mfa_align $YOUR_data_dir montreal-forced-aligner/pretrained_models/librispeech-lexicon.txt english $YOUR_PREPROCESSED_PATH -j 8VCTK數據集上的DeepSpeaker在說話者之間顯示出明確的身份。下圖顯示了我們實驗中提取的揚聲器嵌入的T-SNE圖。
當前, preprocess.py將數據集分為兩個子集:火車和驗證集。如果您需要其他集合,例如測試集val.txt則唯一要做的就是在hp.preprocessed_path/ train.txt
如果您想使用或參考此實現,請用回購引用我們的論文。
@inproceedings{lee21h_interspeech,
author={Keon Lee and Kyumin Park and Daeyoung Kim},
title={{STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech}},
year=2021,
booktitle={Proc. Interspeech 2021},
pages={4643--4647},
doi={10.21437/Interspeech.2021-838}
}

