STYLER
v1.0.0
私たちの論文では、速さ、堅牢性、表現力、制御性を達成するスタイルファクターモデリングを備えた非自動採用TTSフレームワークであるスタイラーを提案します。
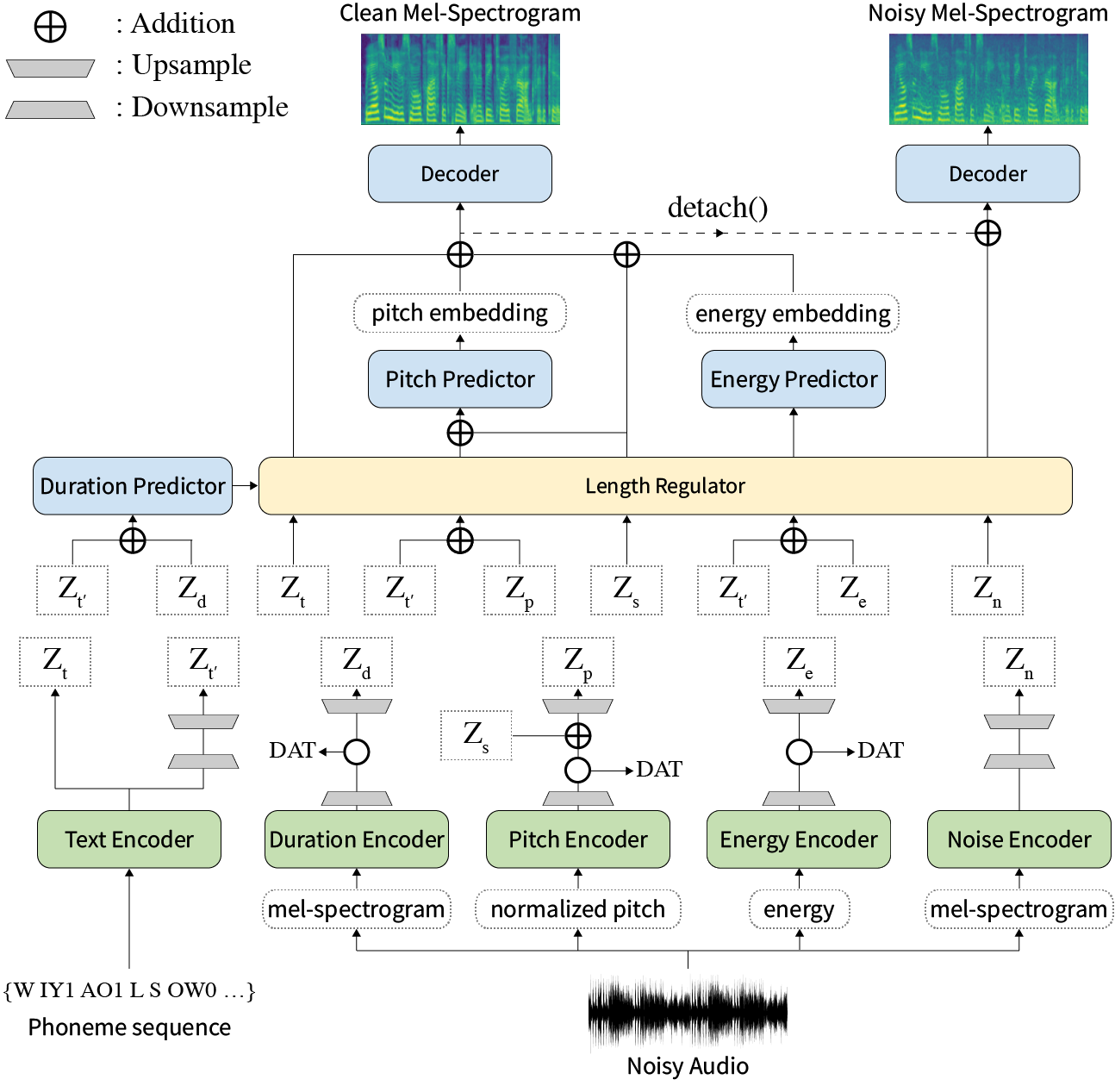
要約:神経テキストへのスピーチ(TTS)に関する以前の作品は、トレーニングと推論時間、困難な合成条件の堅牢性、表現力、制御性の限られた速度で対処されています。いくつかのアプローチはいくつかの制限を解決しますが、すべての弱点を一度に解決しようとする試みはありませんでした。この論文では、高速で堅牢な合成を備えた表現力豊かで制御可能なTTSフレームワークであるStylerを提案します。 MEL Calibratorと呼ばれる私たちの新しいオーディオテキストアライディングメソッドを除外し、オートレーフデコードを除外して、目に見えないデータの迅速なトレーニングと推論、堅牢な合成を可能にします。また、監督下での解きだめのスタイル因子モデリングは、表現力豊かなTTにつながる合成プロセスの制御性を拡大します。それに加えて、ドメインの敵対的なトレーニングと残留デコードを使用した新しいノイズモデリングパイプラインは、ノイズロビースタイルの転送を強化し、追加のラベルなしでノイズを分解します。さまざまな実験により、Stylerは、自己回帰デコードを備えた表現力豊かなTTSよりも速度と堅牢性がより効果的であり、読み取りスタイルの非自動性TTSよりも表現力豊かで制御可能であることが示されています。合成サンプルと実験結果はデモページから提供され、コードは公開されています。
前処理されたモデルをダウンロードできます。
requirements.txtに与えられたPython依存関係をインストールしてください。txt。
pip3 install -r requirements.txtdata/resample.shを参照してください。hparams.pyのhp.data_dir変更します。hparams.pyのhp.noise_dirを変更します。hifigan/generator_universal.pth.tar.zip 。 まず、PhilipperemyのDeepspeakerのRescnn SoftMax+Triplet Modelのダウンロードスピーカーの埋め込みのように、 hp.speaker_embedder_dirに配置します。
次に、モントリオールの強制Aligner(MFA)パッケージと、次のコマンドを介して前提条件の(Librispeech)Lexiconファイルをダウンロードします。 MFAは、発話と音素シーケンスの間のアライメントをfastspeech2として取得するために使用されます。
wget https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner/releases/download/v1.1.0-beta.2/montreal-forced-aligner_linux.tar.gz
tar -zxvf montreal-forced-aligner_linux.tar.gz
wget http://www.openslr.org/resources/11/librispeech-lexicon.txt -O montreal-forced-aligner/pretrained_models/librispeech-lexicon.txt次に、必要なすべての機能を処理します。 hp.preprocessed_path/でstat.txtファイルを取得します。 stat.txtの内容に従って、 hparams.pyのF0およびエネルギーパラメーターを変更する必要があります。
python3 preprocess.py最後に、各発言とランダムに選択されたバックグラウンドノイズからWHAMから混合することにより、クリーンデータとは別にノイズの多いデータを取得します!データセット。
python3 preprocess_noisy.py今、あなたはすべての前提条件を持っています!次のコマンドを使用してモデルをトレーニングします。
python3 train.pysentences.py in data/ pythons.pyを作成します。これには、合成されるテキストのsentencesという名前のpythonリストがあります。 sentences複数のテキストを含めることができることに注意してください。
# In 'data/sentences.py',
sentences = [
" Nothing is lost, everything is recycled. "
]リファレンスオーディオの準備には、データの準備と同様のプロセスがあります。参照には、清潔でうるさいという2種類の参照があります。
まず、対応するテキストでクリーンなオーディオを単一のディレクトリに配置し、 hparams.pyのhp.ref_audio_dir変更し、必要なすべての機能を処理します。 Train PreparationのClean Dataセクションを参照してください。
python3 preprocess_refs.py次に、ノイズの多い参照を取得します。
python3 preprocess_noisy.py --refs次のコマンドは、 hp.ref_audio_dirのdata/sentences.pyのすべてのテキストの組み合わせを統合します。
python3 synthesize.py --ckpt CHECKPOINT_PATHまたは、次のようにhp.ref_audio_dirで単一の参照オーディオを指定することもできます。
python3 synthesize.py --ckpt CHECKPOINT_PATH --ref_name AUDIO_FILENAMEまた、いくつかの便利なオプションがあります。
--speaker_idスピーカーを指定します。指定されたスピーカーの埋め込みは、 hp.preprocessed_path/spker_embedにある必要があります。デフォルトの値はNone 。スピーカーの埋め込みは、各入力オーディオの実行時に計算されます。
--inspection 、スタイラーの各エンコーダーの効果を示す追加の出力を提供します。サンプルは、デモページのStyle Factor Modelingセクションと同じです。
--cont 、デモページのStyle Factor Controlセクションとしてサンプルを生成します。
python3 synthesize.py --ckpt CHECKPOINT_PATH --cont --r1 AUDIO_FILENAME_1 --r2 AUDIO_FILENAME_1 --contオプションは、前処理されたデータのみで動作していることに注意してください。詳細には、Audiosの名前はVCTKデータセット(例えば、P323_229)と同じ形式を持つ必要があり、前処理されたデータはhp.preprocessed_pathに存在する必要があります。
テンソルボードロガーはlogディレクトリに保存されます。使用
tensorboard --logdir logLocalHostでテンソルボードを提供するため。 560KステップのVCTKでのモデルトレーニングのログビューを次に示します。
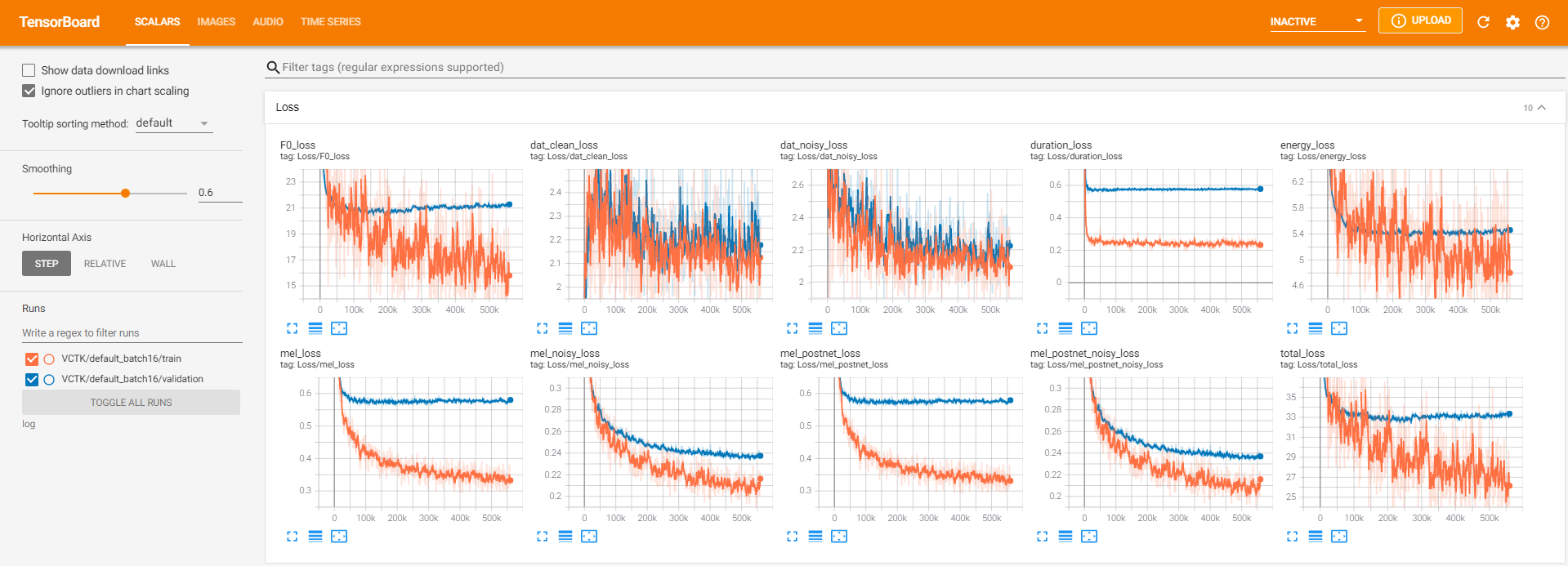
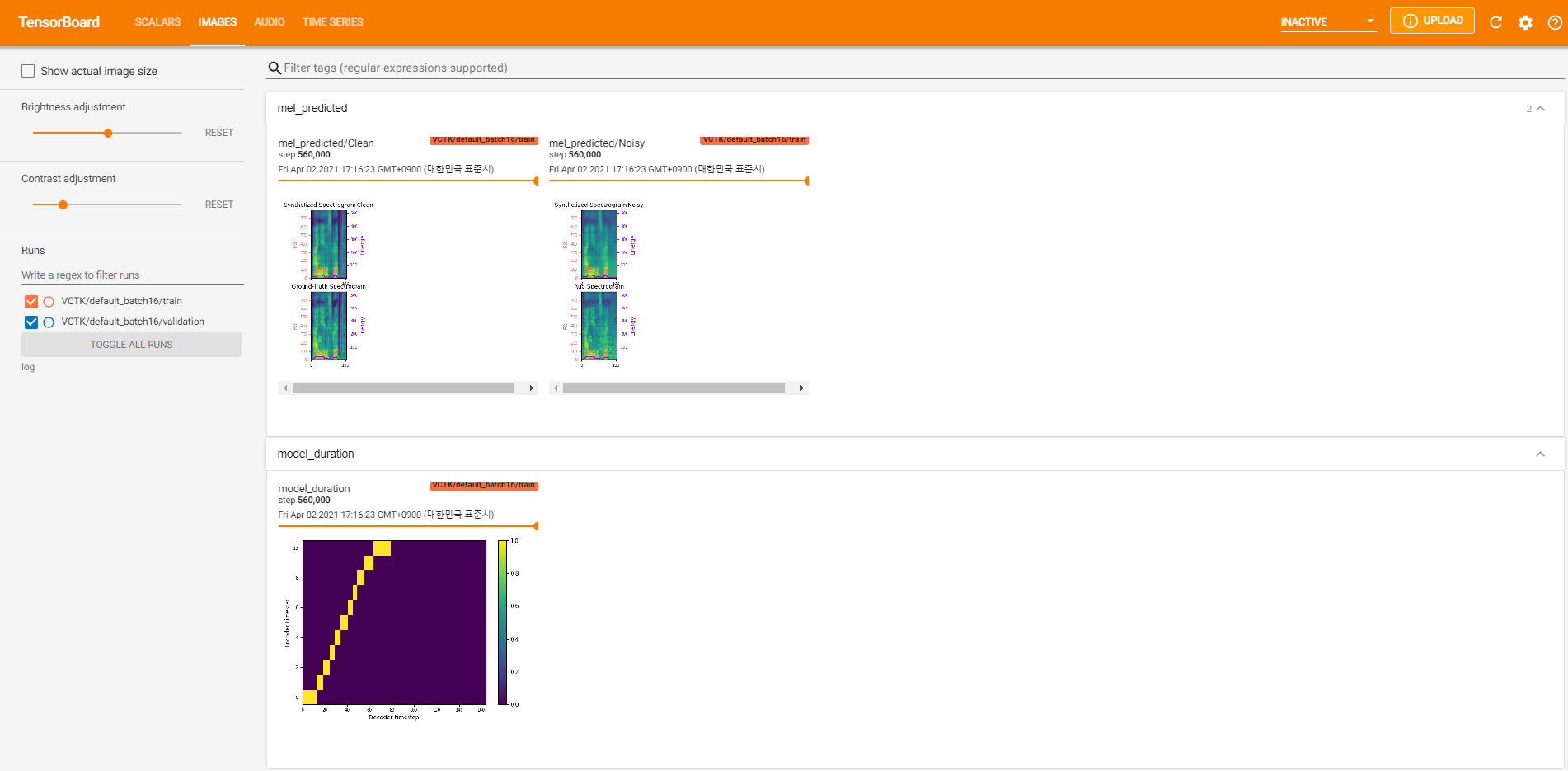
クリーンデータのように、 pyworldを通じて抽出が不可能なノイズデータが多すぎました。これを解決するために、 pysptkを適用して、ノイズの多いデータの基本頻度についてログF0を抽出しました。 --noisy_inputオプションは、合成中にこのプロセスを自動化します。
preprocess.pyを実行しているときにMFA関連の問題が発生した場合、次のコマンドでMFAを手動で実行してみてください。
# Replace $data_dir and $PREPROCESSED_PATH with ./VCTK-Corpus-92/wav48_silence_trimmed and ./preprocessed/VCTK/TextGrid, for example
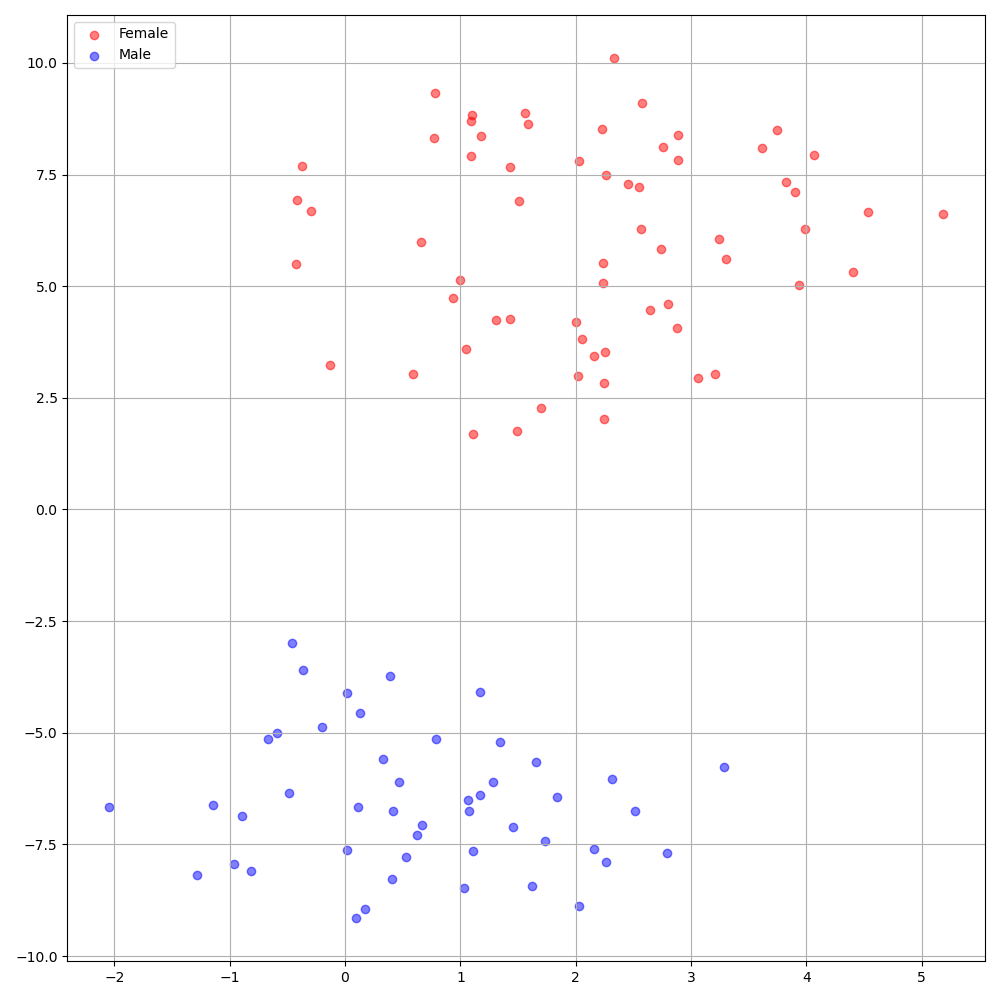
./montreal-forced-aligner/bin/mfa_align $YOUR_data_dir montreal-forced-aligner/pretrained_models/librispeech-lexicon.txt english $YOUR_PREPROCESSED_PATH -j 8VCTKデータセットのDeepSpeakerは、スピーカー間の明確な識別を示しています。次の図は、実験に抽出されたスピーカー埋め込みのT-SNEプロットを示しています。
現在、 preprocess.pyデータセットを2つのサブセットに分割します:トレーニングと検証セット。テストセットなどの他のセットが必要な場合、 hp.preprocessed_path/のテキストファイル( train.txtまたはval.txt )を変更することだけです。
この実装を使用または参照したい場合は、私たちの論文をリポジトリで引用してください。
@inproceedings{lee21h_interspeech,
author={Keon Lee and Kyumin Park and Daeyoung Kim},
title={{STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech}},
year=2021,
booktitle={Proc. Interspeech 2021},
pages={4643--4647},
doi={10.21437/Interspeech.2021-838}
}

