STYLER
v1.0.0
Dans notre article, nous proposons Styler, un cadre TTS non autorégressif avec modélisation de facteurs de style qui atteint la rapidité, la robustesse, l'expressivité et la contrôlabilité en même temps.
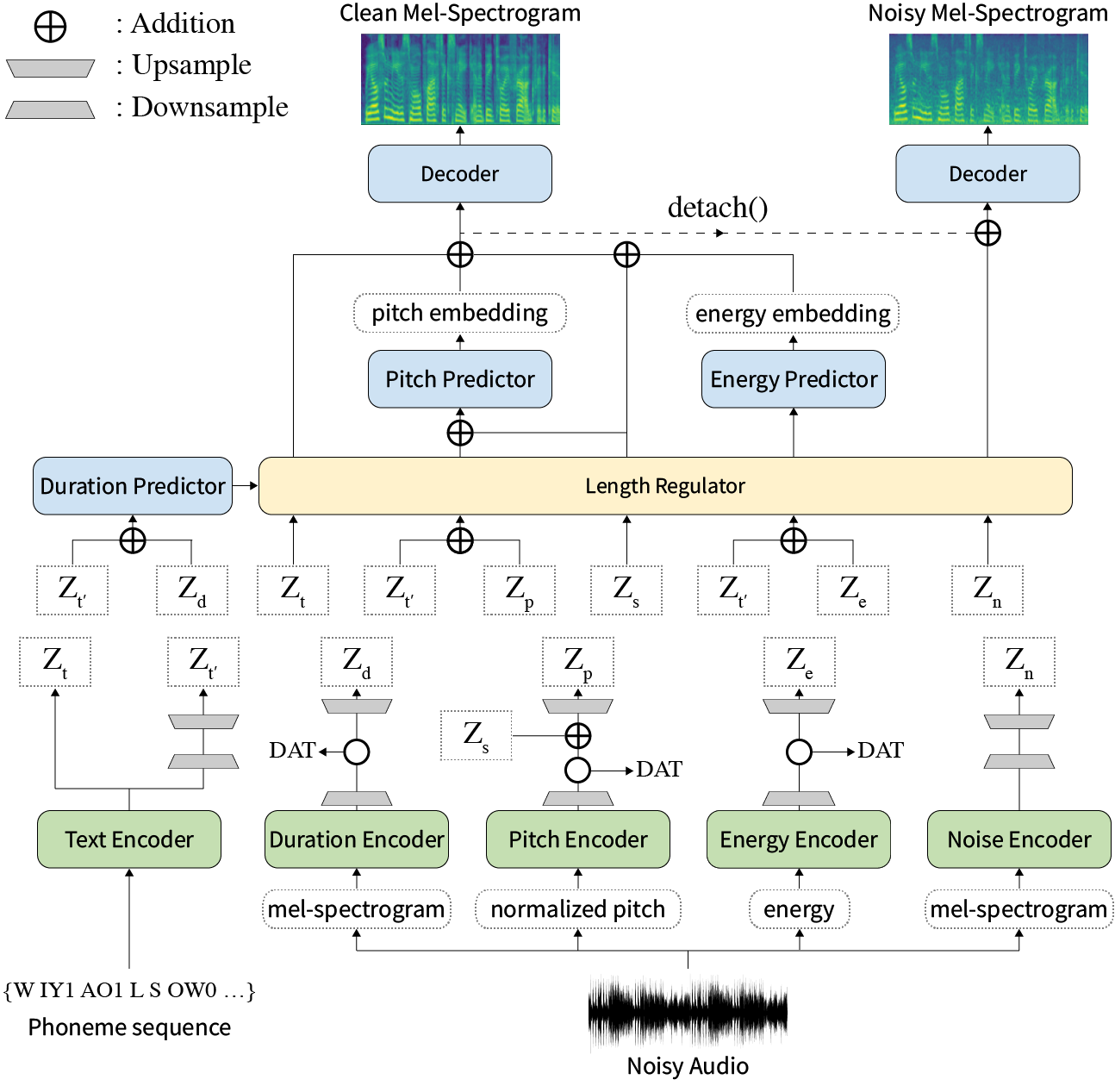
Résumé: Les travaux précédents sur le texte-propre-discours (TTS) ont été abordés à une vitesse limitée dans l'entraînement et le temps d'inférence, la robustesse pour les conditions de synthèse difficile, l'expressivité et la contrôlabilité. Bien que plusieurs approches résolvent certaines limites, il n'y a eu aucune tentative de résolution de toutes les faiblesses à la fois. Dans cet article, nous proposons Styler, un cadre TTS expressif et contrôlable avec une synthèse à grande vitesse et robuste. Notre nouvelle méthode d'alignement audio-texte appelé calibrateur MEL et excluant le décodage autorégressif permettent une formation et une inférence rapides et une synthèse robuste sur des données invisibles. De plus, la modélisation de facteurs de style démêlé sous la supervision élargit la contrôlabilité dans le processus de synthèse conduisant à des TT expressifs. En plus, un nouveau pipeline de modélisation du bruit utilisant l'entraînement adversaire du domaine et le décodage résiduel renforcent le transfert de style de robuste de bruit, décomposant le bruit sans aucune étiquette supplémentaire. Diverses expériences démontrent que Styler est plus efficace en vitesse et en robustesse que les TTs expressifs avec décodage autorégressif et plus expressif et contrôlable que TTS non autorégressif de style de lecture. Les échantillons de synthèse et les résultats de l'expérience sont fournis via notre page de démonstration, et le code est disponible publiquement.
Vous pouvez télécharger des modèles pré-entraînés.
Veuillez installer les dépendances Python données dans requirements.txt .
pip3 install -r requirements.txtdata/resample.sh pour le détail.hp.data_dir dans hparams.py .hp.noise_dir dans hparams.py .hifigan/generator_universal.pth.tar.zip dans le même répertoire. Tout d'abord, téléchargez Rescnn SoftMax + Triplet Pre-Trened Model of Philippermy's Deeppeaker pour le haut-parleur intégré comme décrit dans notre article et le localisez dans hp.speaker_embedder_dir .
Deuxièmement, téléchargez le package Montréal Forced Aligner (MFA) et le fichier de lexique prétrainé (LibrisEech) via les commandes suivantes. Le MFA est utilisé pour obtenir les alignements entre les énoncés et les séquences de phonèmes comme FastSpeech2.
wget https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner/releases/download/v1.1.0-beta.2/montreal-forced-aligner_linux.tar.gz
tar -zxvf montreal-forced-aligner_linux.tar.gz
wget http://www.openslr.org/resources/11/librispeech-lexicon.txt -O montreal-forced-aligner/pretrained_models/librispeech-lexicon.txt Ensuite, traitez toutes les fonctionnalités nécessaires. Vous obtiendrez un fichier stat.txt dans votre hp.preprocessed_path/ . Vous devez modifier les paramètres F0 et Energy dans le hparams.py en fonction du contenu de stat.txt .
python3 preprocess.pyEnfin, obtenez les données bruyantes séparément des données propres en mélangeant chaque énoncé avec un bruit de fond sélectionné au hasard de WHAM! ensemble de données.
python3 preprocess_noisy.pyMaintenant, vous avez toutes les conditions préalables! Former le modèle en utilisant la commande suivante:
python3 train.py Créer sentences.py dans data/ qui a une liste de python nommée sentences de textes à synthétiser. Notez que sentences peuvent contenir plus d'un texte.
# In 'data/sentences.py',
sentences = [
" Nothing is lost, everything is recycled. "
]La préparation audio de référence a un processus similaire à la préparation des données de formation. Il pourrait y avoir deux types de références: propre et bruyant.
Tout d'abord, mettez des audios propres avec des textes correspondants dans un seul répertoire et modifiez le hp.ref_audio_dir dans hparams.py et traitez toutes les fonctionnalités nécessaires. Reportez-vous à la section Clean Data de Train Preparation .
python3 preprocess_refs.pyEnsuite, obtenez les références bruyantes.
python3 preprocess_noisy.py --refs La commande suivante synthétisera toutes les combinaisons de textes dans data/sentences.py et audios dans hp.ref_audio_dir .
python3 synthesize.py --ckpt CHECKPOINT_PATH Ou vous pouvez spécifier l'audio de référence unique dans hp.ref_audio_dir comme suit.
python3 synthesize.py --ckpt CHECKPOINT_PATH --ref_name AUDIO_FILENAMEIl existe également plusieurs options utiles.
--speaker_id spécifiera le haut-parleur. L'intégration de l'orateur spécifié doit être dans hp.preprocessed_path/spker_embed . La valeur par défaut n'est None et l'intégration du haut-parleur est calculée à l'exécution de chaque audio d'entrée.
--inspection vous donnera des sorties supplémentaires qui montrent les effets de chaque encodeur de Styler. Les échantillons sont les mêmes que la section Style Factor Modeling sur notre page de démonstration.
--cont générera les échantillons comme la section Style Factor Control sur notre page de démonstration.
python3 synthesize.py --ckpt CHECKPOINT_PATH --cont --r1 AUDIO_FILENAME_1 --r2 AUDIO_FILENAME_1 Notez que l'option --cont ne fonctionne que sur les données prétraitées. En détail, le nom d'Audios doit avoir le même format que l'ensemble de données VCTK (par exemple, p323_229), et les données prétraitées doivent exister dans hp.preprocessed_path .
Les journalistes de Tensorboard sont stockés dans le répertoire log . Utiliser
tensorboard --logdir logPour servir le Tensorboard sur votre hôte local. Voici quelques vues forestières de la formation du modèle sur VCTK pour 560k étapes.
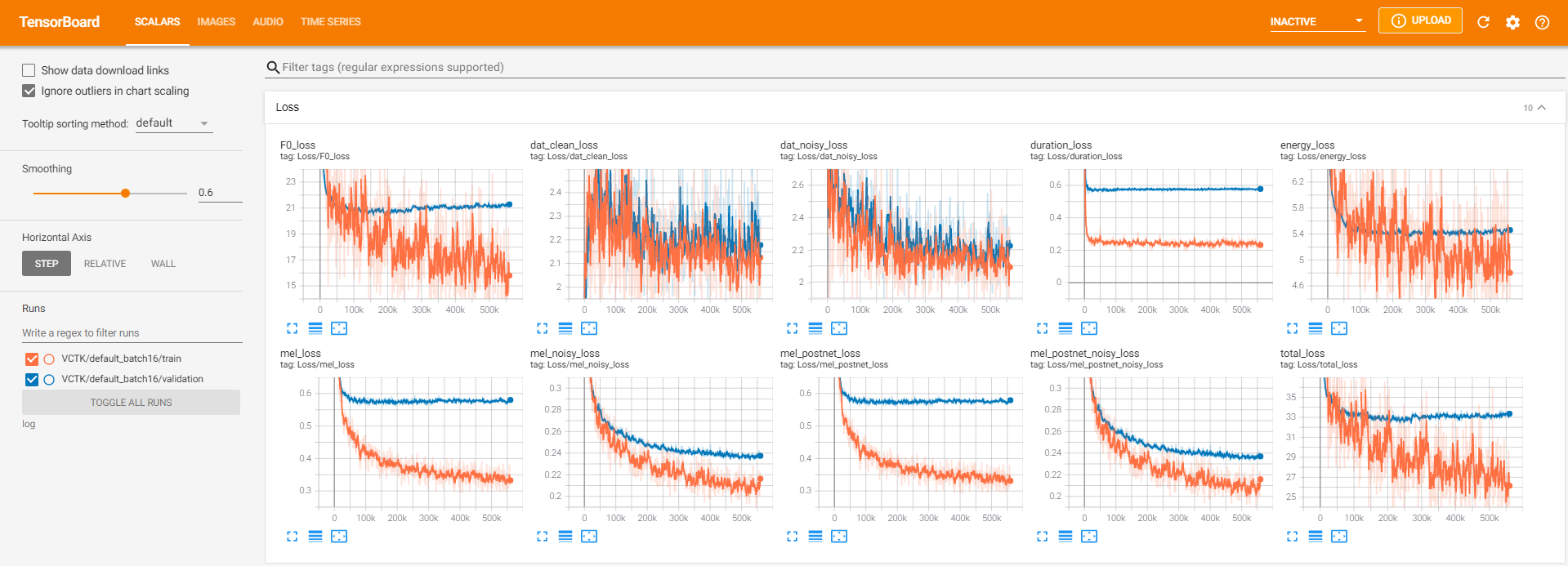
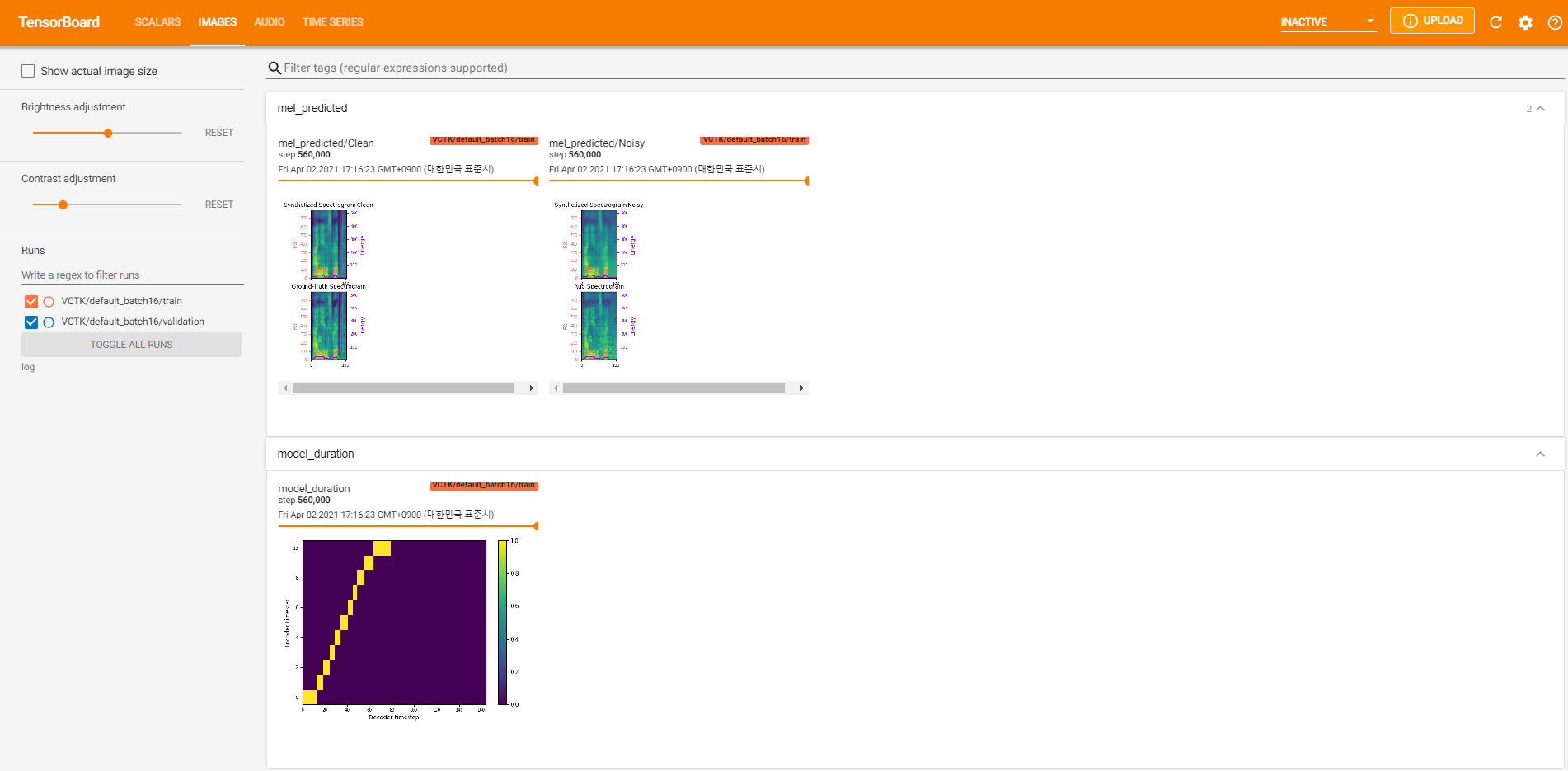
Il y avait trop de données de bruit où l'extraction n'était pas possible via pyworld comme dans les données propres. Pour résoudre ce problème, pysptk a été appliqué pour extraire le log F0 pour la fréquence fondamentale des données bruyantes. L'option --noisy_input automatisera ce processus pendant la synthèse.
Si des problèmes liés au MFA se produisent lors de l'exécution preprocess.py , essayez d'exécuter manuellement le MFA par la commande suivante.
# Replace $data_dir and $PREPROCESSED_PATH with ./VCTK-Corpus-92/wav48_silence_trimmed and ./preprocessed/VCTK/TextGrid, for example
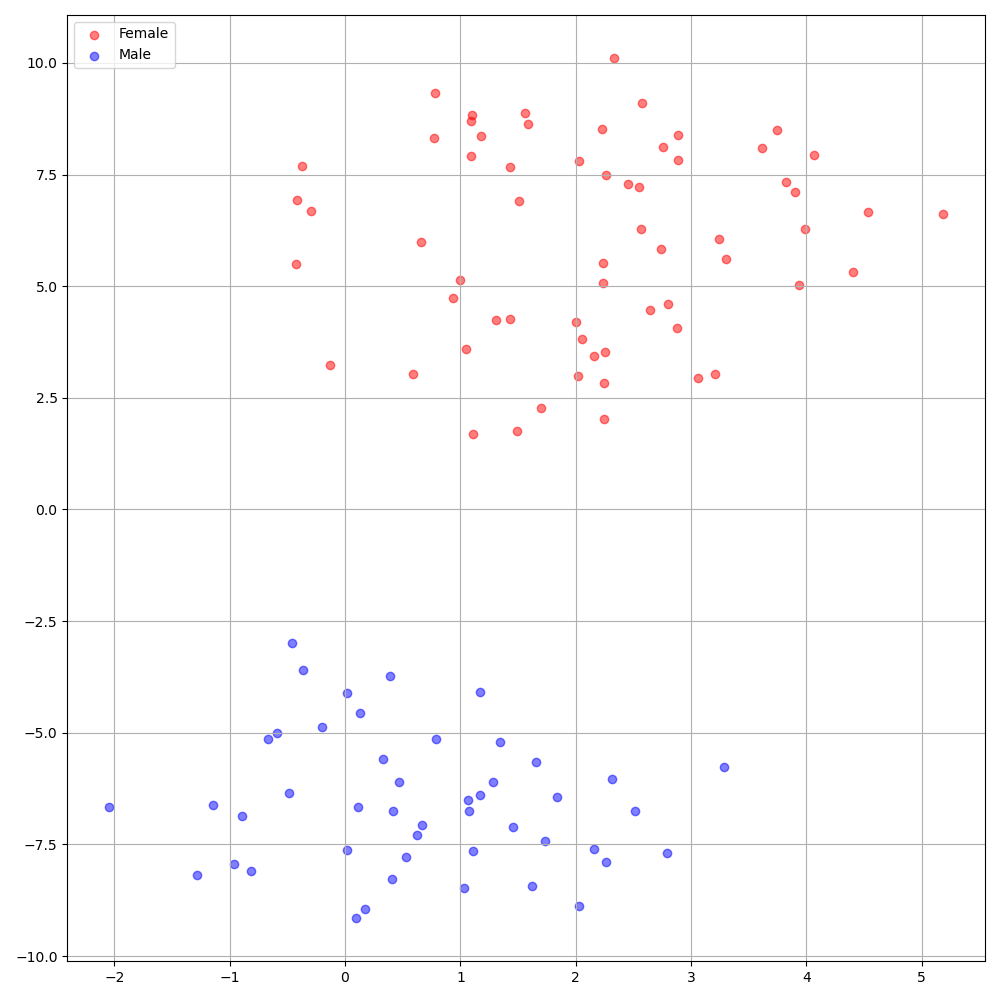
./montreal-forced-aligner/bin/mfa_align $YOUR_data_dir montreal-forced-aligner/pretrained_models/librispeech-lexicon.txt english $YOUR_PREPROCESSED_PATH -j 8DeepPeaker sur le jeu de données VCTK montre une identification claire parmi les haut-parleurs. La figure suivante montre le tracé T-SNE du haut-parleur extrait incorporant dans nos expériences.
Actuellement, preprocess.py divise l'ensemble de données en deux sous-ensembles: Train and Validation Set. Si vous avez besoin d'autres ensembles, tels qu'un ensemble de tests, la seule chose à faire est de modifier les fichiers texte ( train.txt ou val.txt ) dans hp.preprocessed_path/ .
Si vous souhaitez utiliser ou vous référer à cette implémentation, veuillez citer notre article avec le dépôt.
@inproceedings{lee21h_interspeech,
author={Keon Lee and Kyumin Park and Daeyoung Kim},
title={{STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech}},
year=2021,
booktitle={Proc. Interspeech 2021},
pages={4643--4647},
doi={10.21437/Interspeech.2021-838}
}

