STYLER
v1.0.0
In unserem Artikel schlagen wir Styler vor, ein nicht-autoregressives TTS-Framework mit Stilfaktormodellierung, das gleichzeitig Schnelligkeit, Robustheit, Expression und Kontrollierbarkeit erzielt.
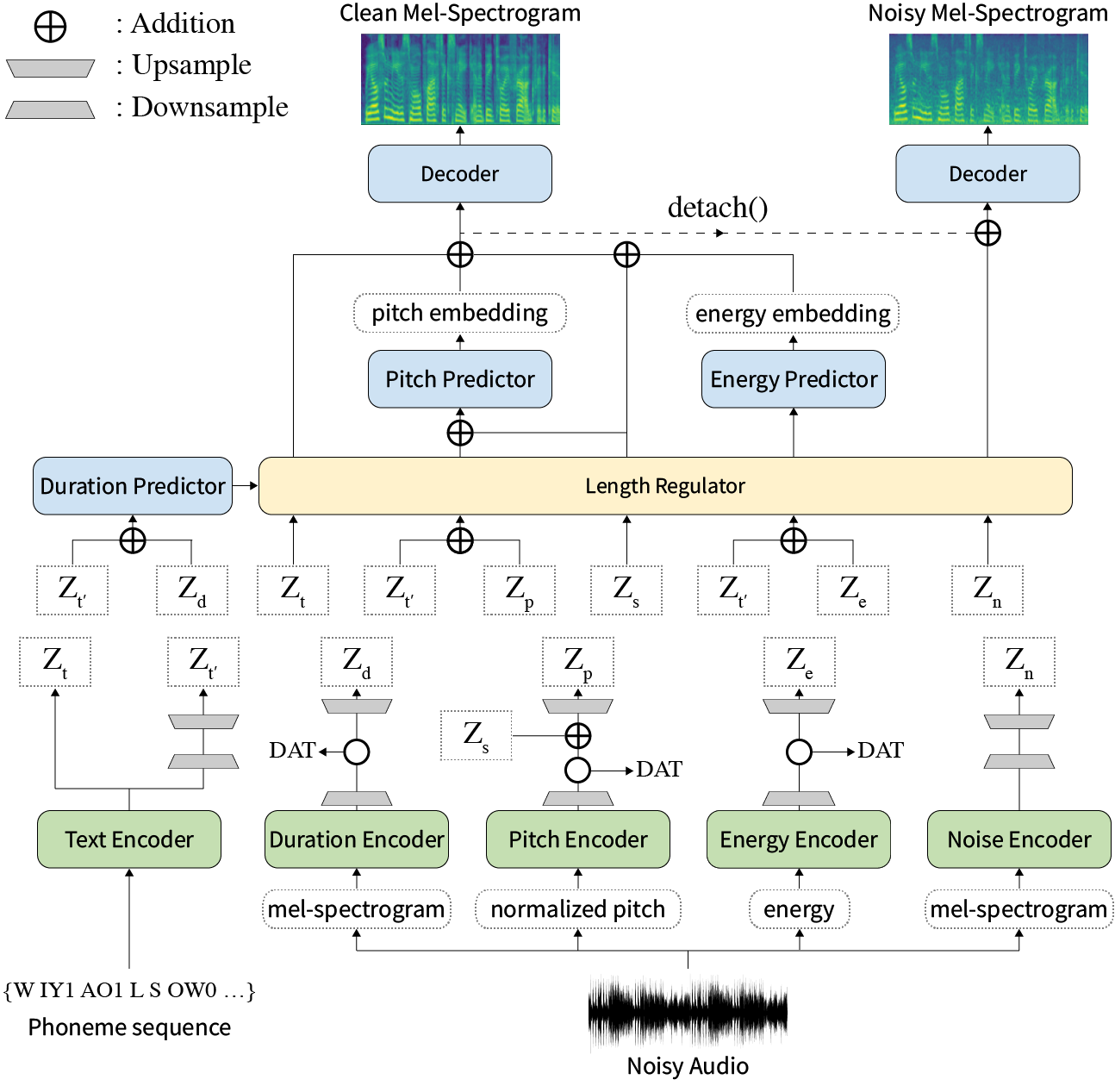
Zusammenfassung: Frühere Arbeiten zur Nerventextextation (TTS) wurden in Bezug auf die begrenzte Geschwindigkeit in der Trainings- und Inferenzzeit, die Robustheit für schwierige Synthesebedingungen, Ausdruckskraft und Kontrollierbarkeit angesprochen. Obwohl mehrere Ansätze einige Einschränkungen lösen, gab es keinen Versuch, alle Schwächen gleichzeitig zu lösen. In diesem Artikel schlagen wir Styler vor, ein ausdrucksstarkes und kontrollierbares TTS-Framework mit Hochgeschwindigkeits- und robuster Synthese. Unsere neuartige Audio-Text-Ausrichtungsmethode namens Mel Calibrator und ohne autoregressive Dekodierung ermöglicht ein schnelles Training und Inferenz und eine robuste Synthese zu unsichtbaren Daten. Außerdem vergrößert sich die Modellierung des Stilfaktors unter Aufsicht unter Überwachung die Kontrollierbarkeit bei der Syntheseprozesse, die zu ausdrucksstarken TTs führt. Darüber hinaus ermöglicht eine neuartige Rauschmodellierungspipeline mit Domänengegner und Restdekodierung den Rauschen-Robust-Stil, der das Rauschen ohne zusätzliche Etikett zerlegt. Verschiedene Experimente zeigen, dass Styler in Geschwindigkeit und Robustheit effektiver ist als ausdrucksstarke TTs mit autoregressiver Decodierung und ausdrucksvoller und kontrollierbarer als nicht-autoregressive TTs im Lesen. Syntheseproben und Experimentergebnisse werden über unsere Demo -Seite bereitgestellt, und Code ist öffentlich verfügbar.
Sie können vorbereitete Modelle herunterladen.
Bitte installieren Sie die in requirements.txt angegebenen Python -Abhängigkeiten.
pip3 install -r requirements.txtdata/resample.sh .hp.data_dir in hparams.py .hp.noise_dir in hparams.py .hifigan/generator_universal.pth.tar.zip im selben Verzeichnis. Download rescnn Softmax+Triplet Pretrained Model of Philipperemy's Deepspeaker für den Lautsprecher, der in unserem Papier beschrieben ist, und lokalisieren Sie es in hp.speaker_embedder_dir .
Laden Sie zweitens das Paket für erzwungene Aligner (MFA) von Montreal erzwungen und die Lexikondatei (Librispeech) durch die folgenden Befehle herunter. MFA wird verwendet, um die Ausrichtungen zwischen den Äußerungen und den Phonemsequenzen als Fastspeech2 zu erhalten.
wget https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner/releases/download/v1.1.0-beta.2/montreal-forced-aligner_linux.tar.gz
tar -zxvf montreal-forced-aligner_linux.tar.gz
wget http://www.openslr.org/resources/11/librispeech-lexicon.txt -O montreal-forced-aligner/pretrained_models/librispeech-lexicon.txt Bearbeiten Sie dann alle notwendigen Merkmale. Sie erhalten eine stat.txt -Datei in Ihrem hp.preprocessed_path/ . Sie müssen die F0- und Energieparameter in der hparams.py gemäß dem Inhalt von stat.txt ändern.
python3 preprocess.pyHolen Sie sich schließlich die lauten Daten getrennt von den sauberen Daten, indem Sie jede Äußerung mit einem zufällig ausgewählten Hintergrundgeräusch von Wham mischen! Datensatz.
python3 preprocess_noisy.pyJetzt haben Sie alle Voraussetzungen! Trainieren Sie das Modell mit dem folgenden Befehl:
python3 train.py sentences.py erstellen.py in data/ , in denen eine Python -Liste mit dem Namen sentences von Texten synthetisiert werden soll. Beachten Sie, dass sentences mehr als einen Text enthalten können.
# In 'data/sentences.py',
sentences = [
" Nothing is lost, everything is recycled. "
]Die Referenz -Audiovorbereitung hat einen ähnlichen Prozess wie die Vorbereitung der Schulungsdaten. Es könnte zwei Arten von Referenzen geben: sauber und laut.
Geben Sie zunächst saubere Audios mit entsprechenden Texten in ein einzelnes Verzeichnis und ändern Sie die hp.ref_audio_dir in hparams.py und verarbeiten Sie alle erforderlichen Funktionen. Siehe Abschnitt Clean Data der Train Preparation .
python3 preprocess_refs.pyHolen Sie sich dann die lauten Referenzen.
python3 preprocess_noisy.py --refs Der folgende Befehl synthetisiert alle Kombinationen von Texten in data/sentences.py und Audios in hp.ref_audio_dir .
python3 synthesize.py --ckpt CHECKPOINT_PATH Oder Sie können ein einzelnes Referenz -Audio in hp.ref_audio_dir wie folgt angeben.
python3 synthesize.py --ckpt CHECKPOINT_PATH --ref_name AUDIO_FILENAMEAußerdem gibt es mehrere nützliche Optionen.
--speaker_id wird den Sprecher angeben. Die Einbettung des angegebenen Sprechers sollte in hp.preprocessed_path/spker_embed liegen. Der Standardwert ist None und die Einbettung des Lautsprechers wird zur Laufzeit auf jedem Eingabe -Audio berechnet.
--inspection bietet Ihnen zusätzliche Ausgänge, die die Auswirkungen jedes Encoders von Styler zeigen. Die Proben entsprechen dem Abschnitt mit dem Abschnitt Style Factor Modeling auf unserer Demo -Seite.
--cont erzeugt die Proben als Abschnitt mit dem Style Factor Control auf unserer Demo-Seite.
python3 synthesize.py --ckpt CHECKPOINT_PATH --cont --r1 AUDIO_FILENAME_1 --r2 AUDIO_FILENAME_1 Beachten Sie, dass die Option --cont nur an vorverarbeiteten Daten funktioniert. Im Detail sollte der Name der Audios das gleiche Format wie VCTK -Datensatz (z. B. P323_229) haben, und die vorverarbeiteten Daten müssen in hp.preprocessed_path vorhanden sein.
Die Tensorboard -Logger werden im log gespeichert. Verwenden
tensorboard --logdir logum das Tensorboard auf Ihrem örtlichen Haus zu servieren. Hier finden Sie einige Protokollierungsansichten des Modelltrainings auf VCTK für 560K -Schritte.
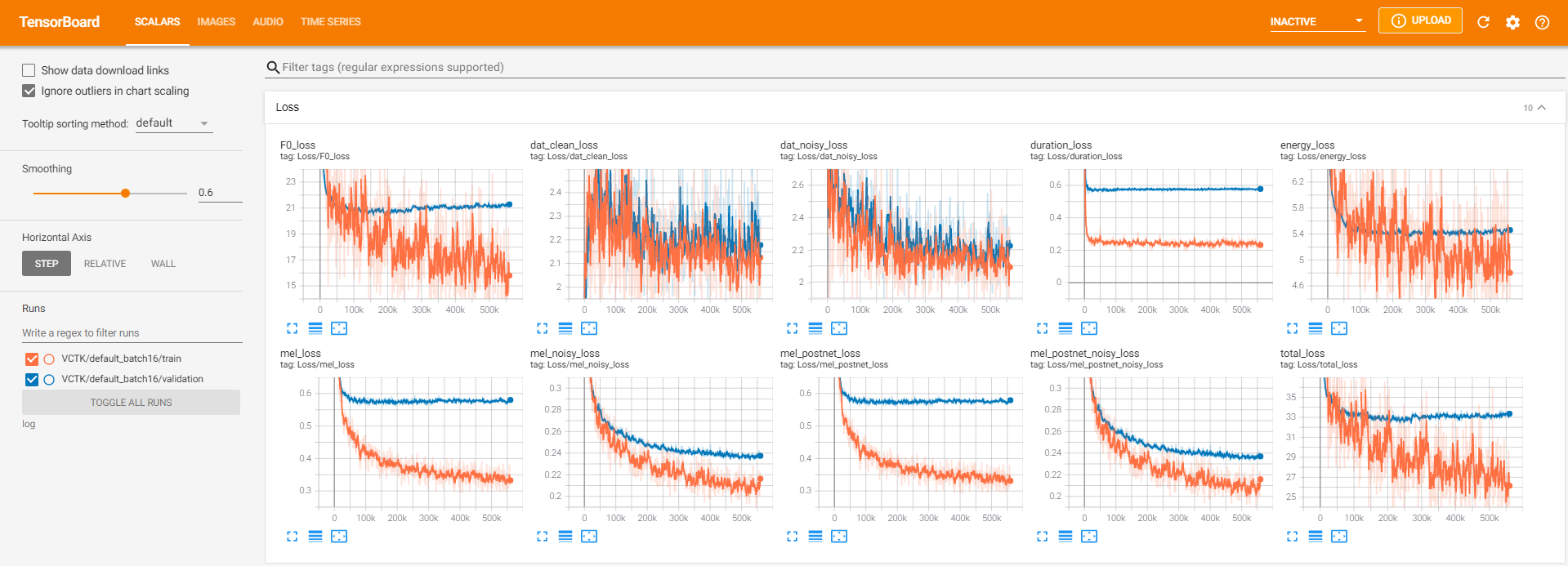
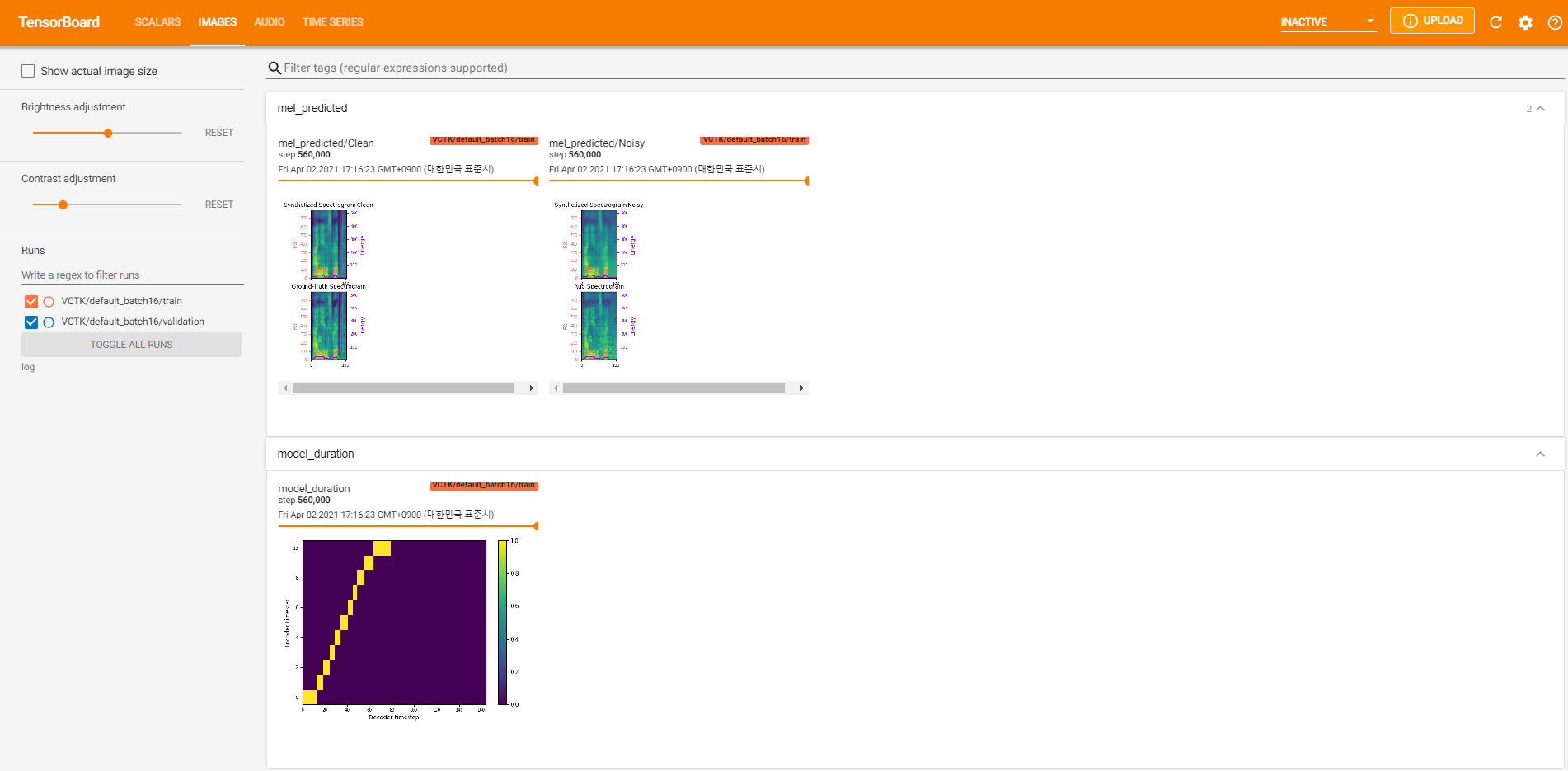
Es gab zu viele Rauschdaten, bei denen die Extraktion durch pyworld wie in sauberen Daten nicht möglich war. Um dies zu beheben, wurde pysptk angewendet, um log F0 für die grundlegende Häufigkeit der lauten Daten zu extrahieren. Die Option --noisy_input automatisiert diesen Prozess während der Synthese.
Wenn MFA-bezogene Probleme während des laufenden preprocess.py auftreten.
# Replace $data_dir and $PREPROCESSED_PATH with ./VCTK-Corpus-92/wav48_silence_trimmed and ./preprocessed/VCTK/TextGrid, for example
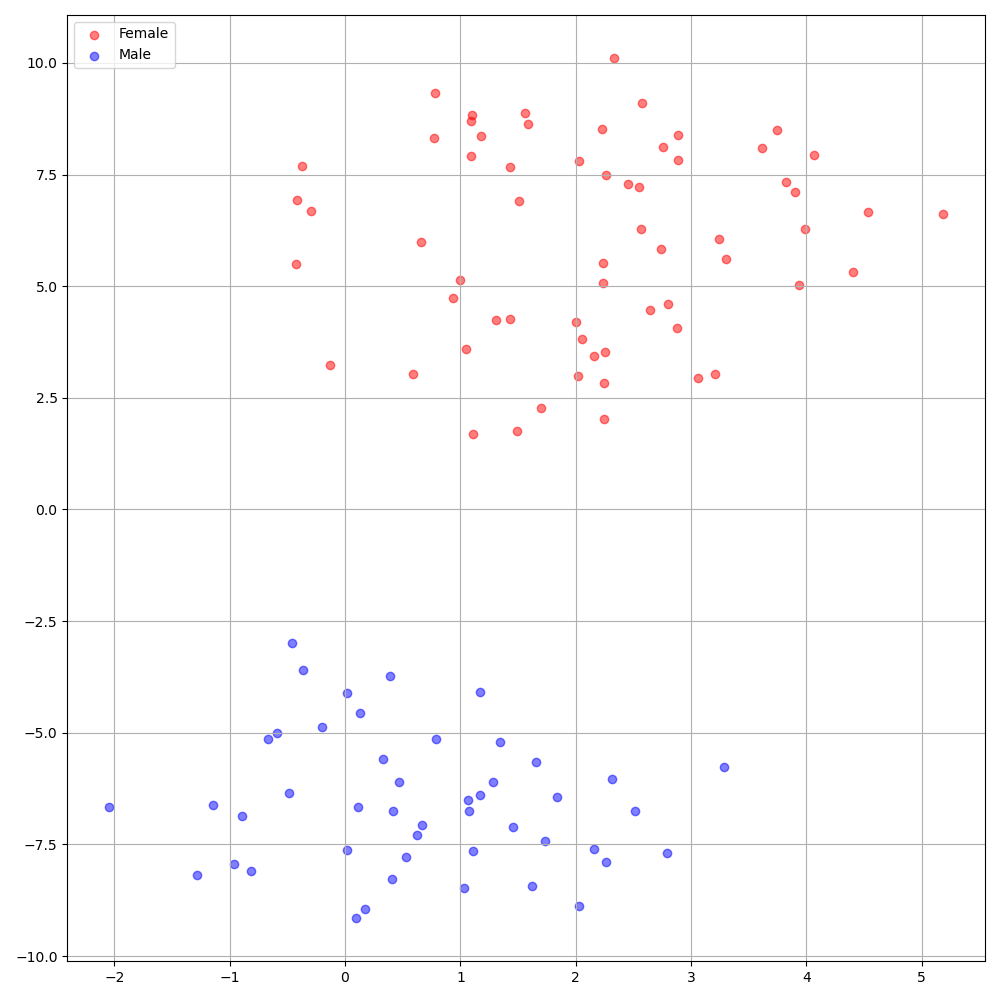
./montreal-forced-aligner/bin/mfa_align $YOUR_data_dir montreal-forced-aligner/pretrained_models/librispeech-lexicon.txt english $YOUR_PREPROCESSED_PATH -j 8Deepspeaker im VCTK -Datensatz zeigt eine klare Identifizierung unter den Sprechern. Die folgende Abbildung zeigt die T-SNE-Diagramme von extrahierten Lautsprechern, die in unsere Experimente eingebettet sind.
Derzeit unterteilt preprocess.py den Datensatz in zwei Teilmengen: Zug und Validierungssatz. Wenn Sie andere Sätze benötigen, z. B. einen Testsatz, ist das einzige, was Sie tun müssen, die Textdateien ( train.txt oder val.txt ) in hp.preprocessed_path/ .
Wenn Sie diese Implementierung verwenden oder auf diese Implementierung verweisen möchten, zitieren Sie bitte unser Papier mit dem Repo.
@inproceedings{lee21h_interspeech,
author={Keon Lee and Kyumin Park and Daeyoung Kim},
title={{STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech}},
year=2021,
booktitle={Proc. Interspeech 2021},
pages={4643--4647},
doi={10.21437/Interspeech.2021-838}
}

