STYLER
v1.0.0
في ورقتنا ، نقترح Styler ، وهو إطار TTS غير التابع للانحدار مع نمذجة عامل النمط التي تحقق السرعة والمتانة والتعبيرية والتحكم في نفس الوقت.
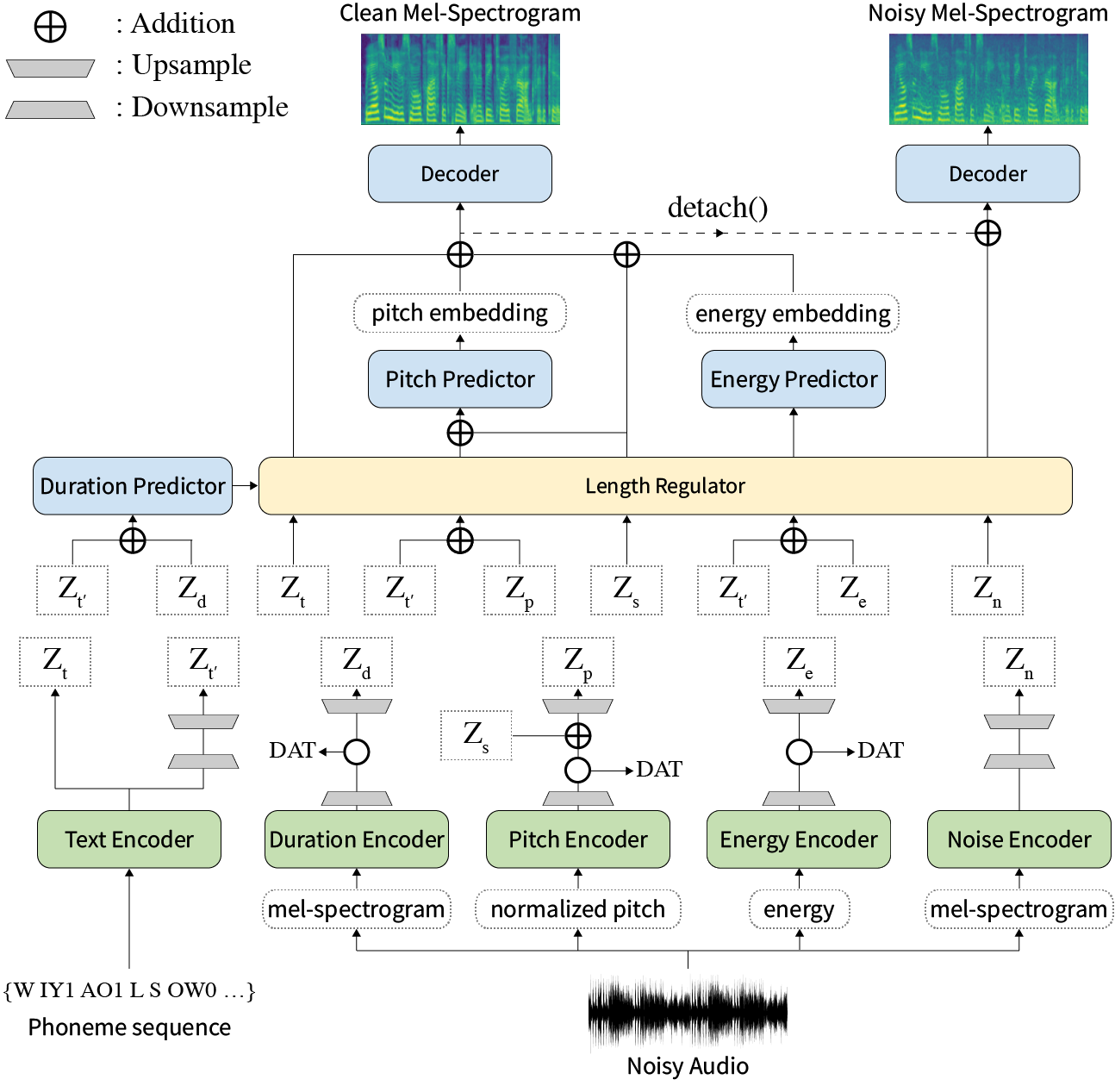
الخلاصة: تمت معالجة الأعمال السابقة على النص العصبي إلى كلام (TTS) على سرعة محدودة في وقت التدريب ووقت الاستدلال ، والمتانة لظروف التوليف الصعبة ، والتعبير ، والتحكم. على الرغم من أن العديد من الأساليب تحل بعض القيود ، إلا أنه لم تكن هناك محاولة لحل جميع نقاط الضعف في وقت واحد. في هذه الورقة ، نقترح Styler ، وهو إطار TTS التعبير والتحكم مع توليف عالي السرعة وقوي. تتيح طريقة محاذاة النص الصوتي الجديد الخاص بنا والتي تسمى MEL Cirafrator واستبعاد فك التشفير التلقائي للتدريب السريع والاستدلال والتوليف القوي على البيانات غير المرئية. أيضا ، فإن نمذجة عامل النمط Disentangled تحت الإشراف يوسع قابلية التحكم في توليف عملية مما يؤدي إلى TTS التعبيرية. علاوة على ذلك ، فإن خط أنابيب نمذجة الضوضاء الجديد باستخدام التدريب العددي للمجال ونقاط فك التشفير المتبقية يمكّن نقل نمط الضوضاء ، مما يتحلل الضوضاء دون أي علامة إضافية. توضح التجارب المختلفة أن Styler أكثر فاعلية في السرعة والمتانة من TTS التعبيرية مع فك التشفير التلقائي وأكثر تعبيرية ويمكن السيطرة عليه من القراءة TTS غير التوت. يتم توفير عينات التوليف ونتائج التجربة عبر صفحة العرض التجريبي الخاص بنا ، ويتوفر الكود علنًا.
يمكنك تنزيل النماذج المسبقة.
يرجى تثبيت تبعيات بيثون الواردة في requirements.txt .
pip3 install -r requirements.txtdata/resample.sh للحصول على التفاصيل.hp.data_dir في hparams.py .hp.noise_dir في hparams.py .hifigan/generator_universal.pth.tar.zip في نفس الدليل. أولاً ، قم بتنزيل نموذج RAVERMAX+TREPLET PRESTERED من Philipperemy's Deepspeaker لمكبر الصوت كما هو موضح في ورقتنا وتحديد موقعه في hp.speaker_embedder_dir .
ثانياً ، قم بتنزيل حزمة Montreal القسرية لـ Aligner (MFA) وملف المعجم المسبق (Librispeech) من خلال الأوامر التالية. يتم استخدام MFA للحصول على المحاذاة بين الكلام وتسلسل phoneme كما fastspeesh2.
wget https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner/releases/download/v1.1.0-beta.2/montreal-forced-aligner_linux.tar.gz
tar -zxvf montreal-forced-aligner_linux.tar.gz
wget http://www.openslr.org/resources/11/librispeech-lexicon.txt -O montreal-forced-aligner/pretrained_models/librispeech-lexicon.txt ثم ، معالجة جميع الميزات اللازمة. ستحصل على ملف stat.txt في hp.preprocessed_path/ . يجب عليك تعديل معلمات F0 والطاقة في hparams.py وفقًا لمحتوى stat.txt .
python3 preprocess.pyأخيرًا ، احصل على البيانات الصاخبة بشكل منفصل عن البيانات النظيفة عن طريق خلط كل كلام مع قطعة من ضوضاء الخلفية المحددة عشوائيًا من Wham! مجموعة البيانات.
python3 preprocess_noisy.pyالآن لديك كل المتطلبات المسبقة! تدريب النموذج باستخدام الأمر التالي:
python3 train.py قم بإنشاء sentences.py في data/ التي لديها قائمة بيثون تسمى sentences النصوص المراد تصنيعها. لاحظ أن sentences يمكن أن تحتوي على أكثر من نص واحد.
# In 'data/sentences.py',
sentences = [
" Nothing is lost, everything is recycled. "
]يعد إعداد الصوت المرجعي عملية مماثلة لإعداد بيانات التدريب. يمكن أن يكون هناك نوعان من المراجع: نظيفة وصاخبة.
أولاً ، ضع الصوت النظيف مع النصوص المقابلة في دليل واحد وقم بتعديل hp.ref_audio_dir في hparams.py ومعالجة جميع الميزات اللازمة. ارجع إلى قسم Clean Data Train Preparation .
python3 preprocess_refs.pyثم ، احصل على المراجع الصاخبة.
python3 preprocess_noisy.py --refs سيقوم الأمر التالي بتجميع جميع مجموعات النصوص في data/sentences.py و Audios في hp.ref_audio_dir .
python3 synthesize.py --ckpt CHECKPOINT_PATH أو يمكنك تحديد صوت مرجعي واحد في hp.ref_audio_dir على النحو التالي.
python3 synthesize.py --ckpt CHECKPOINT_PATH --ref_name AUDIO_FILENAMEأيضا ، هناك العديد من الخيارات المفيدة.
--speaker_id سيحدد السماعة. يجب أن يكون تضمين مكبر الصوت المحدد في hp.preprocessed_path/spker_embed . القيمة الافتراضية هي None ، ويتم حساب تضمين السماعة في وقت التشغيل على كل صوت إدخال.
-سوف يمنحك --inspection مخرجات إضافية توضح تأثيرات كل تشفير من Styler. العينات هي نفس قسم Style Factor Modeling في صفحة العرض التجريبي لدينا.
--cont بإنشاء العينات كقسم Style Factor Control في صفحة العرض التجريبي لدينا.
python3 synthesize.py --ckpt CHECKPOINT_PATH --cont --r1 AUDIO_FILENAME_1 --r2 AUDIO_FILENAME_1 لاحظ أن -خيار --cont يعمل فقط على البيانات المعالجة مسبقًا. بالتفصيل ، يجب أن يكون لاسم Audios نفس التنسيق مثل مجموعة بيانات VCTK (على سبيل المثال ، p323_229) ، ويجب أن تكون البيانات المعالجة مسبقًا موجودة في hp.preprocessed_path .
يتم تخزين سجلات Tensorboard في دليل log . يستخدم
tensorboard --logdir logلخدمة Tensorboard على مضيفك المحلي. فيما يلي بعض وجهات النظر في تسجيل التدريب النموذجي على VCTK لخطوة 560K.
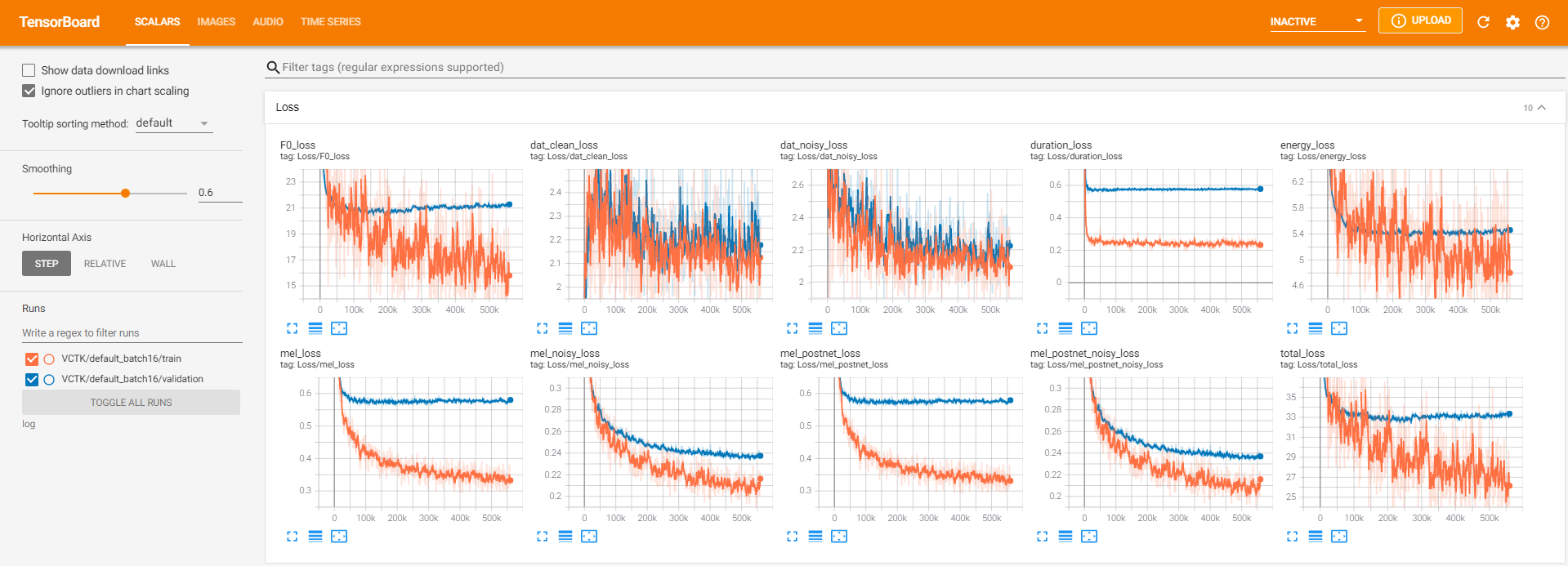
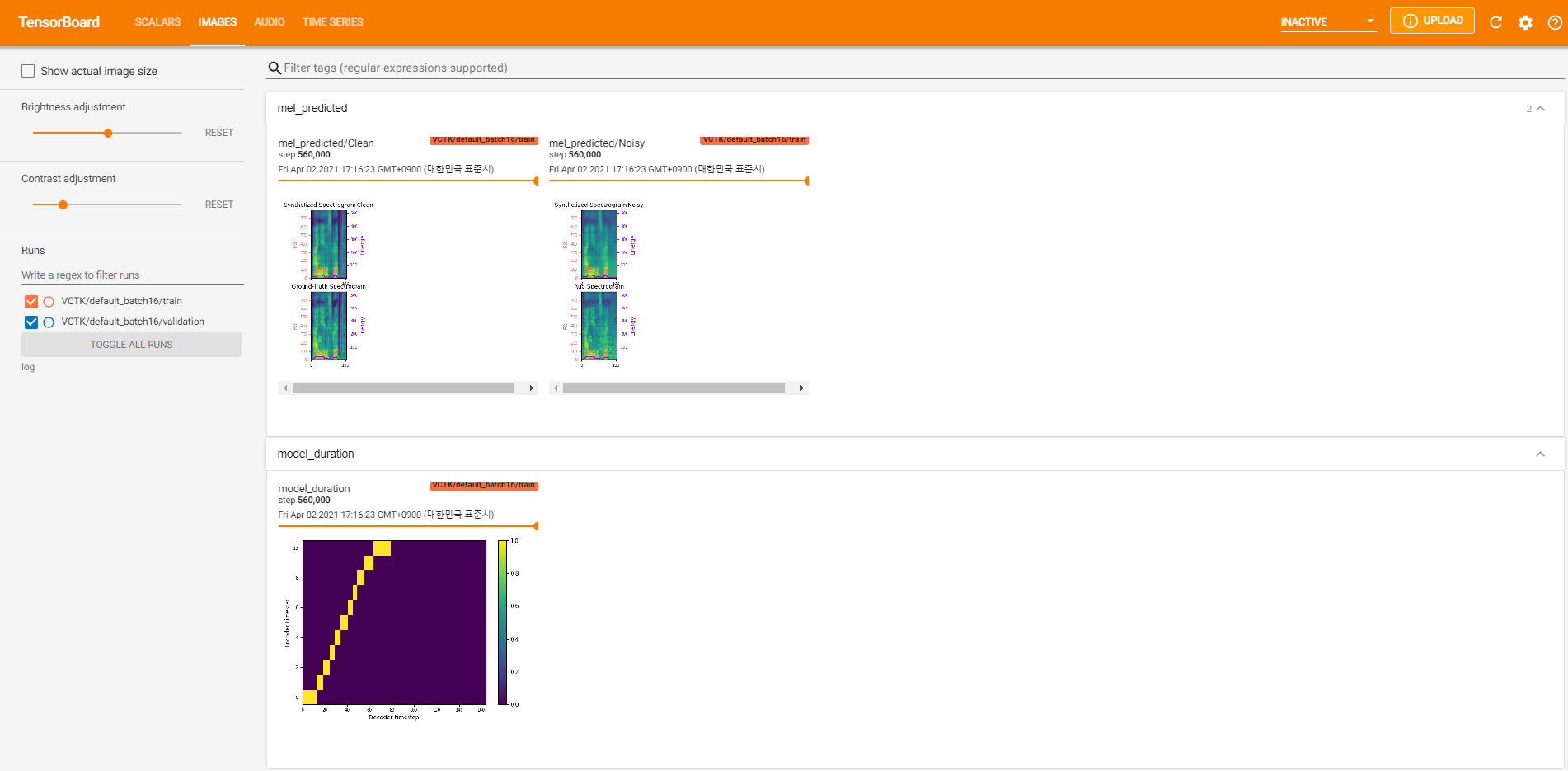
كان هناك الكثير من بيانات الضوضاء حيث لم يكن الاستخراج ممكنًا من خلال pyworld كما هو الحال في البيانات النظيفة. لحل هذا ، تم تطبيق pysptk لاستخراج سجل F0 للتردد الأساسي للبيانات الصاخبة. سيؤدي خيار --noisy_input إلى أتمتة هذه العملية أثناء التوليف.
في حالة حدوث مشاكل متعلقة بـ MFA أثناء التشغيل preprocess.py ، حاول تشغيل MFA يدويًا بواسطة الأمر التالي.
# Replace $data_dir and $PREPROCESSED_PATH with ./VCTK-Corpus-92/wav48_silence_trimmed and ./preprocessed/VCTK/TextGrid, for example
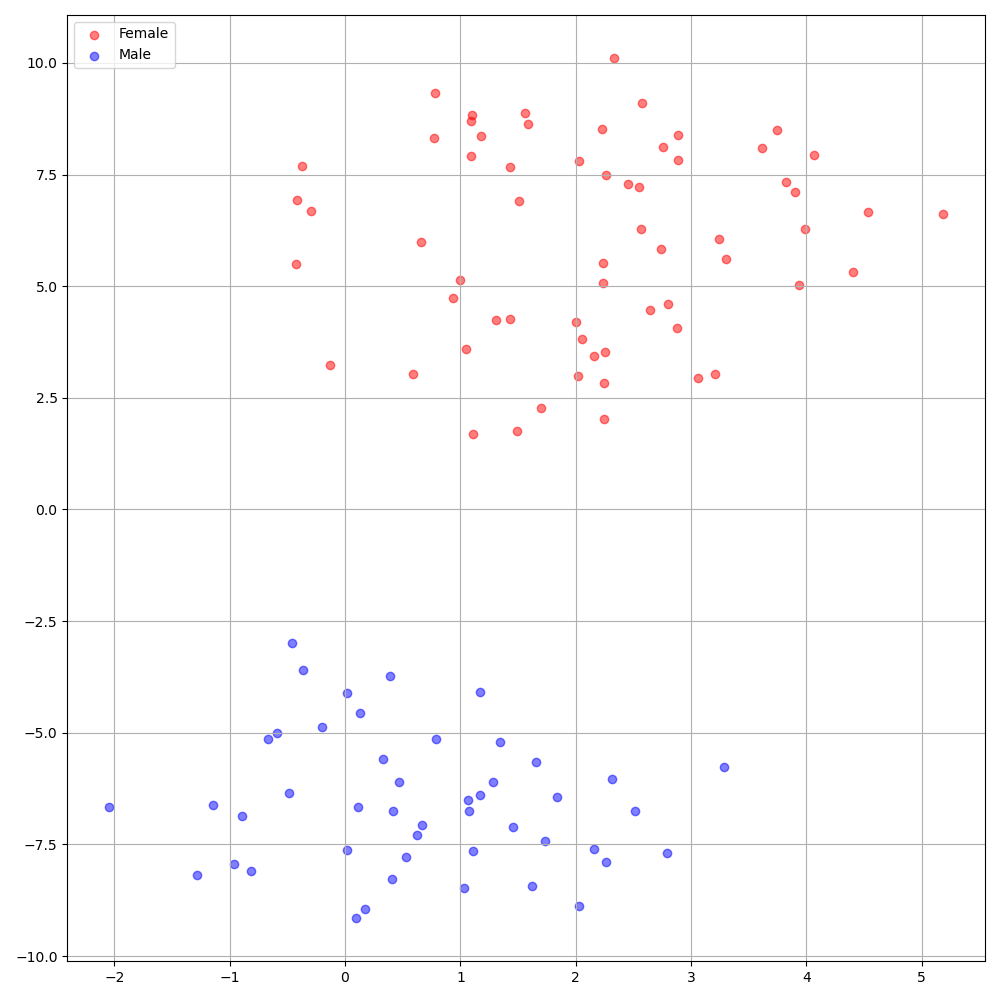
./montreal-forced-aligner/bin/mfa_align $YOUR_data_dir montreal-forced-aligner/pretrained_models/librispeech-lexicon.txt english $YOUR_PREPROCESSED_PATH -j 8تُظهر DeepSpeaker على مجموعة بيانات VCTK تحديدًا واضحًا بين المتحدثين. يوضح الشكل التالي مؤامرة T-Sne للمكبرات المستخرجة التي يتم تضمينها في تجاربنا.
حاليًا ، يقسم preprocess.py مجموعة البيانات إلى مجموعتين فرعيتين: مجموعة القطار والتحقق من الصحة. إذا كنت بحاجة إلى مجموعات أخرى ، مثل مجموعة الاختبار ، فإن الشيء الوحيد الذي يجب القيام به هو تعديل الملفات النصية ( train.txt أو val.txt ) في hp.preprocessed_path/ .
إذا كنت ترغب في استخدام هذا التنفيذ أو الرجوع إليه ، فيرجى الاستشهاد بالورقة مع الريبو.
@inproceedings{lee21h_interspeech,
author={Keon Lee and Kyumin Park and Daeyoung Kim},
title={{STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech}},
year=2021,
booktitle={Proc. Interspeech 2021},
pages={4643--4647},
doi={10.21437/Interspeech.2021-838}
}

