STYLER
v1.0.0
在我们的论文中,我们提出了Styler,这是一种非自动回归TTS框架,具有样式因子建模,可同时实现速度,鲁棒性,表现性和可控性。
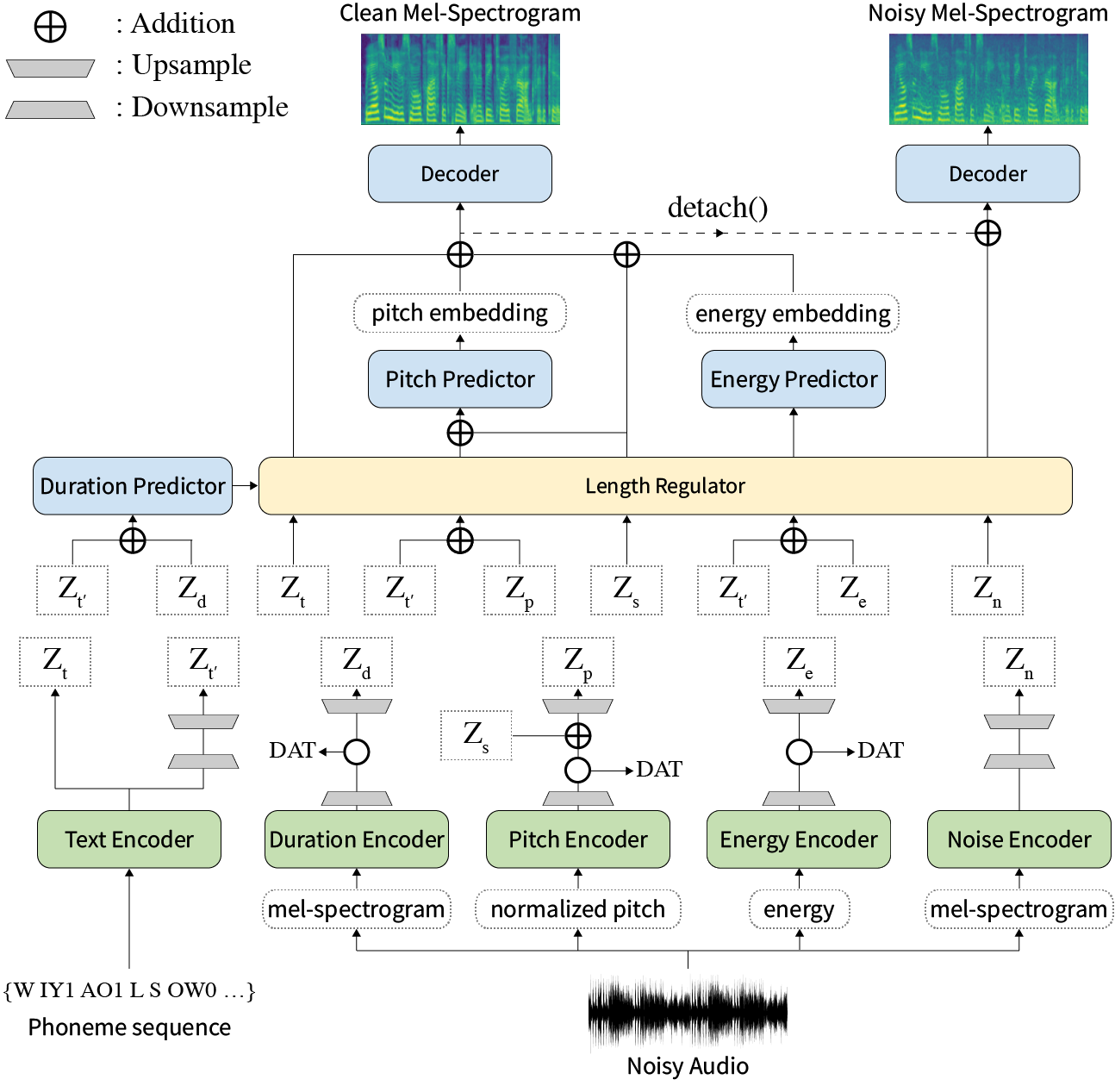
摘要:关于神经文本到语音(TTS)的先前著作已在训练和推理时间有限的速度,难度综合条件,表现力和可控性方面的稳健性。尽管几种方法可以解决一些局限性,但没有尝试一次解决所有弱点。在本文中,我们提出了一种具有高速和稳健合成的表现力和可控制的TTS框架。我们的新型音频文本对齐方法称为MEL校准器,排除自回归解码可以使快速训练,推理以及对看不见的数据的鲁棒合成。此外,在监督下进行解开的样式因子建模扩大了综合过程中的可控性,从而导致表达性TT。最重要的是,使用域对抗训练和残留解码的新型噪声建模管道赋予了噪声风格的传递,使噪声分解了噪声,而无需任何其他标签。各种实验表明,与自动回归解码的表达性TT相比,与阅读样式的非自动回报式TTS相比,造型器在速度和鲁棒性上更有效。合成样本和实验结果通过我们的演示页面提供,代码可公开使用。
您可以下载据预贴模型。
请安装requirements.txt中给出的python依赖项。
pip3 install -r requirements.txtdata/resample.sh 。hparams.py中的hp.data_dir 。hparams.py中的hp.noise_dir 。hifigan/generator_universal.pth.tar.zip在同一目录中。 首先,下载Recknn SoftMax+三重预读的Philipperemy DeepSpeaker的扬声器嵌入模型,如我们的论文所述,并在hp.speaker_embedder_dir中找到它。
其次,通过以下命令下载蒙特利尔强制对准器(MFA)软件包和验证的(librispeech)词典文件。 MFA用于以FastSpeech2的形式获得话语和音素序列之间的比对。
wget https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner/releases/download/v1.1.0-beta.2/montreal-forced-aligner_linux.tar.gz
tar -zxvf montreal-forced-aligner_linux.tar.gz
wget http://www.openslr.org/resources/11/librispeech-lexicon.txt -O montreal-forced-aligner/pretrained_models/librispeech-lexicon.txt然后,处理所有必要的功能。您将在stat.txt th hp.preprocessed_path/ 。您必须根据stat.txt的内容修改hparams.py中的F0和能量参数。
python3 preprocess.py最后,通过将每个话语与WHAM随机选择的背景噪声混合在一起,将嘈杂的数据与干净的数据分开获取!数据集。
python3 preprocess_noisy.py现在您拥有所有先决条件!使用以下命令训练模型:
python3 train.py在data/中创建sentences.py sentences请注意, sentences可以包含多个文本。
# In 'data/sentences.py',
sentences = [
" Nothing is lost, everything is recycled. "
]参考音频准备与培训数据准备相似的过程。可能有两种参考:干净和嘈杂。
首先,将带有相应文本的干净音频放在单个目录中,然后在hparams.py中修改hp.ref_audio_dir ,然后处理所有必要的功能。请参阅Train Preparation的Clean Data部分。
python3 preprocess_refs.py然后,获取嘈杂的参考。
python3 preprocess_noisy.py --refs以下命令将hp.ref_audio_dir data/sentences.py中的所有文本组合。
python3 synthesize.py --ckpt CHECKPOINT_PATH或者,您可以在hp.ref_audio_dir中指定单个参考音频。
python3 synthesize.py --ckpt CHECKPOINT_PATH --ref_name AUDIO_FILENAME另外,还有几个有用的选项。
--speaker_id将指定扬声器。指定的说话者的嵌入应在hp.preprocessed_path/spker_embed中。默认值None ,并且在每个输入音频的运行时计算说话者嵌入。
--inspection将为您提供其他输出,以显示Styler每个编码器的效果。样本与我们的演示页面上的Style Factor Modeling部分相同。
--cont将在我们的演示页面上生成样本作为Style Factor Control部分。
python3 synthesize.py --ckpt CHECKPOINT_PATH --cont --r1 AUDIO_FILENAME_1 --r2 AUDIO_FILENAME_1请注意, --cont选项仅处理预处理数据。详细说明,音频的名称应具有与VCTK数据集相同的格式(例如,p323_229),并且预处理的数据必须存在于hp.preprocessed_path中。
张板记录器存储在log目录中。使用
tensorboard --logdir log在您的本地主机上提供张板。以下是在VCTK上以560k步骤进行模型培训的一些记录视图。
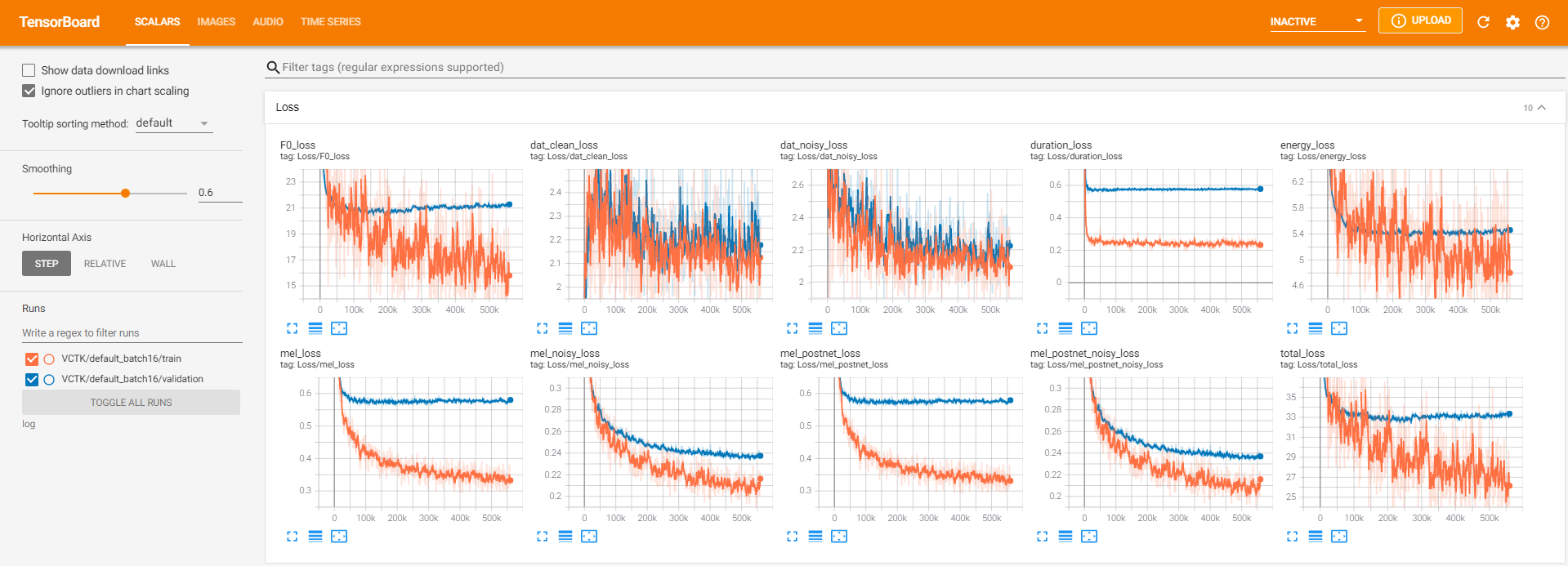
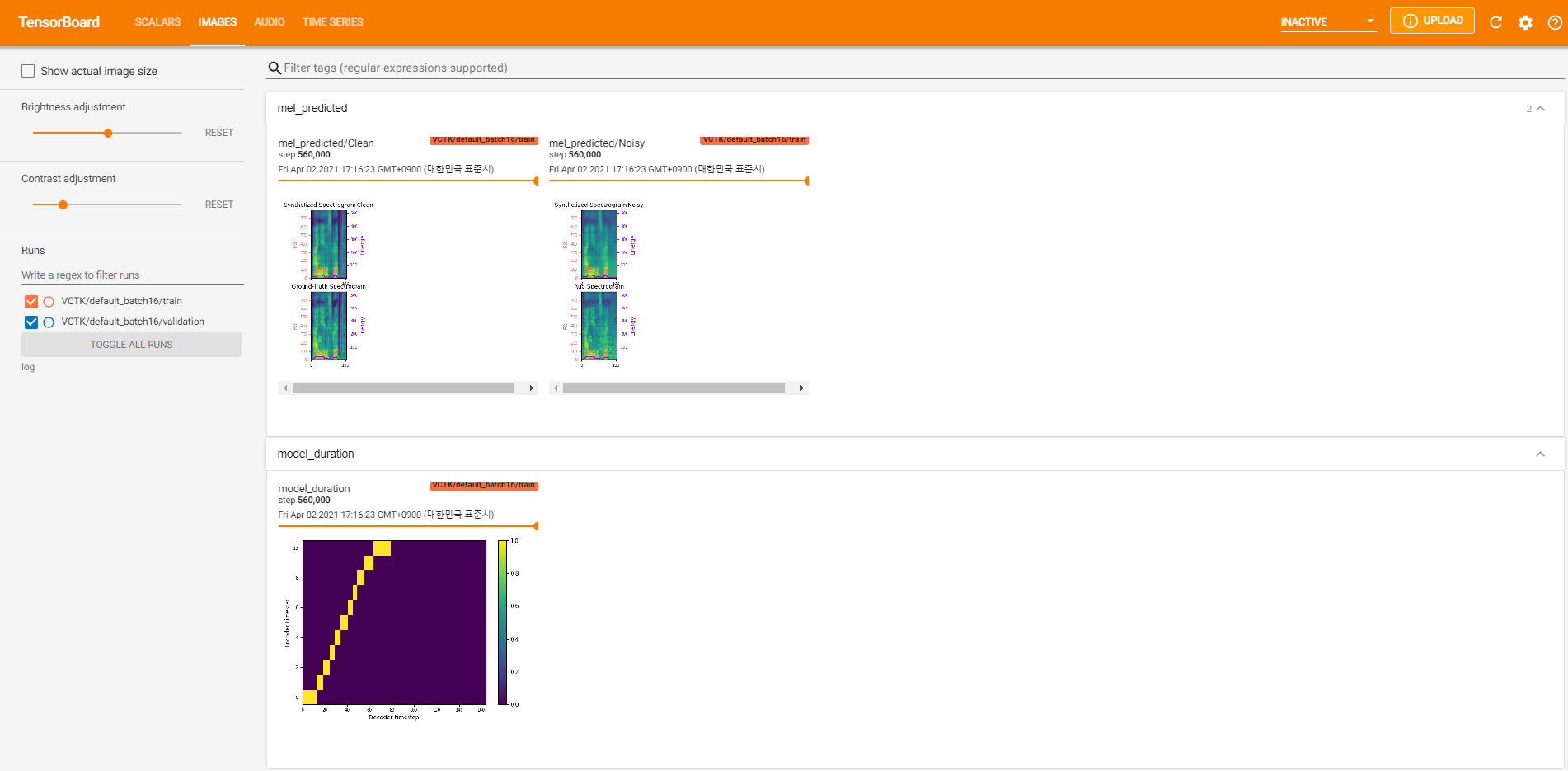
与干净的数据一样,有太多的噪声数据可以通过pyworld进行提取。为了解决这个问题, pysptk用于提取噪声数据的基本频率的Log F0。 --noisy_input选项将在合成过程中自动化此过程。
如果在运行preprocess.py期间发生与MFA相关的问题,请尝试通过以下命令手动运行MFA。
# Replace $data_dir and $PREPROCESSED_PATH with ./VCTK-Corpus-92/wav48_silence_trimmed and ./preprocessed/VCTK/TextGrid, for example
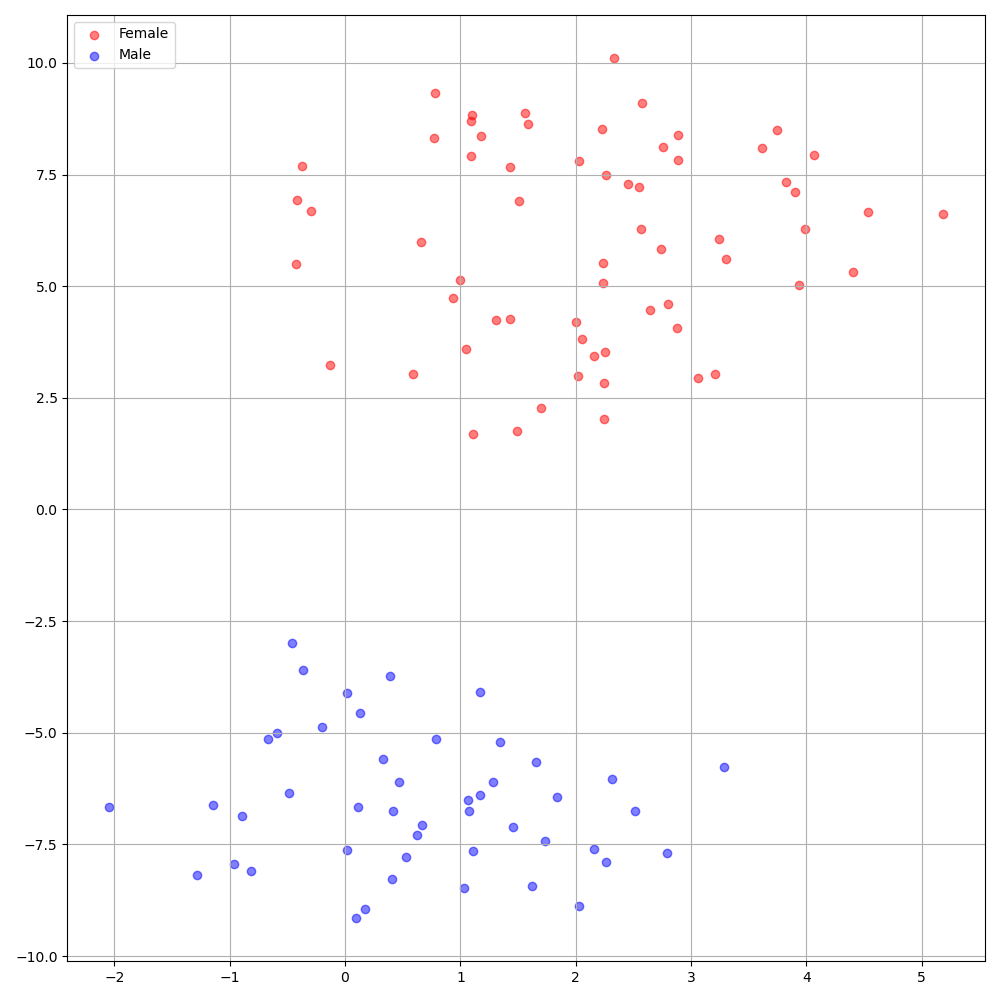
./montreal-forced-aligner/bin/mfa_align $YOUR_data_dir montreal-forced-aligner/pretrained_models/librispeech-lexicon.txt english $YOUR_PREPROCESSED_PATH -j 8VCTK数据集上的DeepSpeaker在说话者之间显示出明确的身份。下图显示了我们实验中提取的扬声器嵌入的T-SNE图。
当前, preprocess.py将数据集分为两个子集:火车和验证集。如果您需要其他集合,例如测试集val.txt则唯一要做的就是在hp.preprocessed_path/ train.txt
如果您想使用或参考此实现,请用回购引用我们的论文。
@inproceedings{lee21h_interspeech,
author={Keon Lee and Kyumin Park and Daeyoung Kim},
title={{STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech}},
year=2021,
booktitle={Proc. Interspeech 2021},
pages={4643--4647},
doi={10.21437/Interspeech.2021-838}
}

