STYLER
v1.0.0
Em nosso artigo, propomos a Styler, uma estrutura TTS não autorregressiva com modelagem de fatores de estilo que alcança rapidez, robustez, expressividade e controlabilidade ao mesmo tempo.
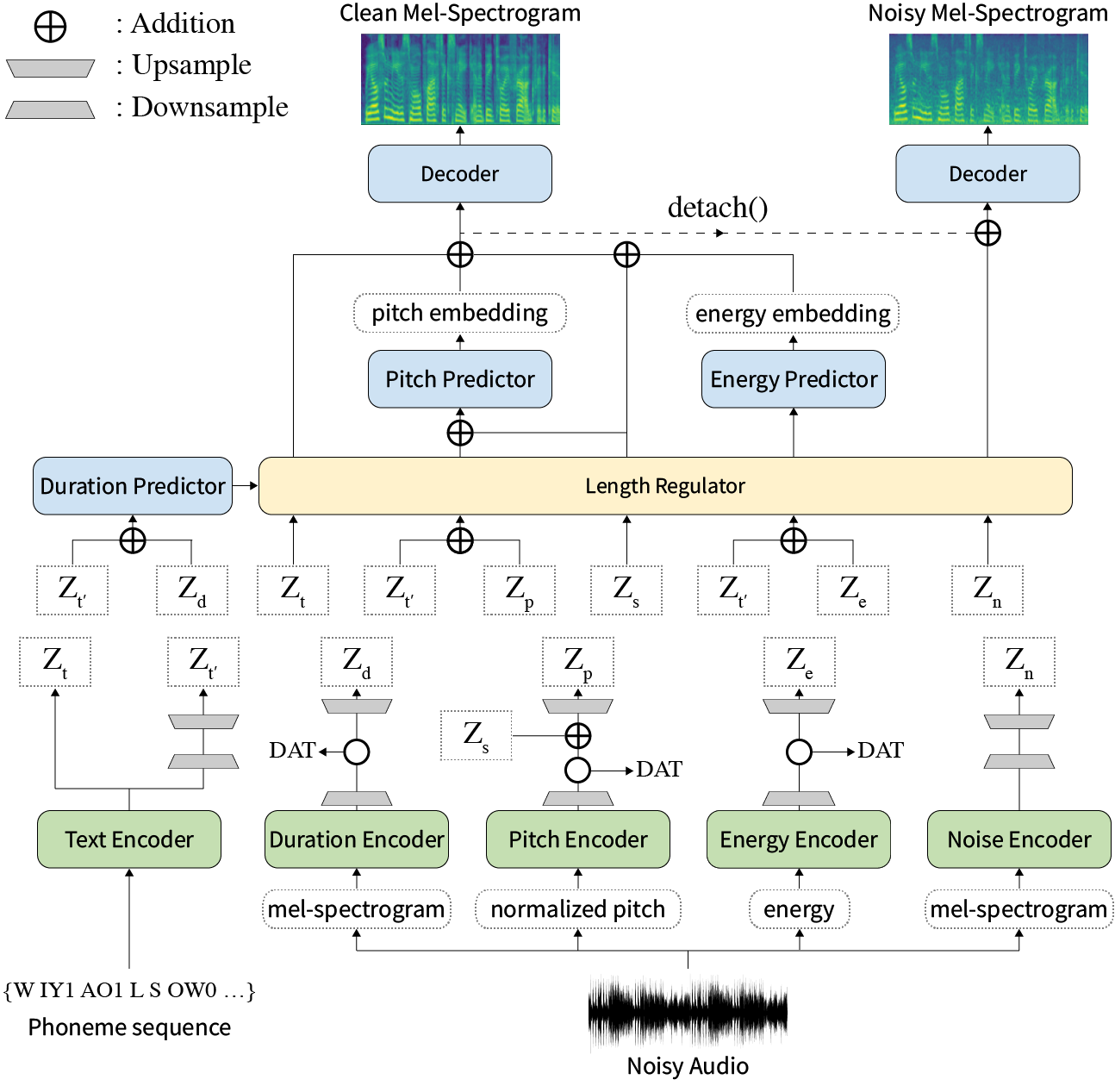
Resumo: Os trabalhos anteriores sobre o texto em fala neural (TTS) foram abordados em velocidade limitada em treinamento e tempo de inferência, robustez para condições de síntese difíceis, expressividade e controlabilidade. Embora várias abordagens resolvam algumas limitações, não houve nenhuma tentativa de resolver todas as fraquezas ao mesmo tempo. Neste artigo, propomos Styler, uma estrutura TTS expressiva e controlável com síntese de alta velocidade e robusta. Nosso novo método de alinhamento de texto de áudio chamado MEL calibrador e excluindo a decodificação autoregressiva permitem treinamento e inferência e síntese robusta em dados invisíveis. Além disso, a modelagem de fatores de estilo não eliminada sob supervisão aumenta a controlabilidade ao sintetizar o processo, levando a TTS expressivo. Além disso, um novo pipeline de modelagem de ruído usando treinamento adversário de domínio e decodificação residual capacita a transferência de estilo de ruído, decompondo o ruído sem nenhum rótulo adicional. Vários experimentos demonstram que o Styler é mais eficaz em velocidade e robustez do que o TTS expressivo com decodificação autoregressiva e mais expressiva e controlável do que o estilo de leitura TTS não autorregressivo. As amostras de síntese e os resultados do experimento são fornecidos por meio de nossa página de demonstração e o código está disponível publicamente.
Você pode baixar modelos pré -terenciados.
Instale as dependências do Python fornecidas nos requirements.txt .
pip3 install -r requirements.txtdata/resample.sh para obter os detalhes.hp.data_dir em hparams.py .hp.noise_dir em hparams.py .hifigan/generator_universal.pth.tar.zip no mesmo diretório. Primeiro, faça o download do Modelo Softmax+Tripleto de Rescnn Triplet do Deepaker de Philipperemy para a incorporação do alto -falante, conforme descrito em nosso artigo e localize -o em hp.speaker_embedder_dir .
Segundo, faça o download do pacote Aligner forçado de Montreal (MFA) e o arquivo de léxico pré -Treiado (Librispeech) através dos seguintes comandos. O MFA é usado para obter os alinhamentos entre os enunciados e as seqüências de fonemas como FastSpeech2.
wget https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner/releases/download/v1.1.0-beta.2/montreal-forced-aligner_linux.tar.gz
tar -zxvf montreal-forced-aligner_linux.tar.gz
wget http://www.openslr.org/resources/11/librispeech-lexicon.txt -O montreal-forced-aligner/pretrained_models/librispeech-lexicon.txt Em seguida, processe todos os recursos necessários. Você obterá um arquivo stat.txt no seu hp.preprocessed_path/ . Você deve modificar os parâmetros F0 e de energia no hparams.py de acordo com o conteúdo do stat.txt .
python3 preprocess.pyPor fim, obtenha os dados barulhentos separadamente dos dados limpos, misturando cada enunciada com um ruído de fundo selecionado aleatoriamente do Wham! conjunto de dados.
python3 preprocess_noisy.pyAgora você tem todos os pré -requisitos! Treine o modelo usando o seguinte comando:
python3 train.py Crie sentences.py em data/ que possui uma lista de Python nomeada sentences de textos a serem sintetizadas. Observe que sentences podem conter mais de um texto.
# In 'data/sentences.py',
sentences = [
" Nothing is lost, everything is recycled. "
]A preparação de áudio de referência tem um processo semelhante à preparação de dados de treinamento. Pode haver dois tipos de referências: limpo e barulhento.
Primeiro, coloque áudios limpos com textos correspondentes em um único diretório e modifique o hp.ref_audio_dir em hparams.py e processe todos os recursos necessários. Consulte a seção Clean Data da Train Preparation .
python3 preprocess_refs.pyEntão, obtenha as referências barulhentas.
python3 preprocess_noisy.py --refs O comando a seguir sintetizará todas as combinações de textos em data/sentences.py e áudios em hp.ref_audio_dir .
python3 synthesize.py --ckpt CHECKPOINT_PATH Ou você pode especificar áudio de referência única em hp.ref_audio_dir como segue.
python3 synthesize.py --ckpt CHECKPOINT_PATH --ref_name AUDIO_FILENAMEAlém disso, existem várias opções úteis.
--speaker_id especificará o alto-falante. A incorporação do orador especificado deve estar em hp.preprocessed_path/spker_embed . O valor padrão é None e a incorporação do alto -falante é calculada em tempo de execução em cada áudio de entrada.
--inspection fornecerá saídas adicionais que mostram os efeitos de cada codificador do Styler. As amostras são as mesmas da seção Style Factor Modeling em nossa página de demonstração.
--cont irá gerar as amostras como a seção Style Factor Control em nossa página de demonstração.
python3 synthesize.py --ckpt CHECKPOINT_PATH --cont --r1 AUDIO_FILENAME_1 --r2 AUDIO_FILENAME_1 Observe que --cont a opção está trabalhando apenas em dados pré -processados. Em detalhes, o nome do Audios deve ter o mesmo formato que o conjunto de dados VCTK (por exemplo, p323_229), e os dados pré -processados devem existir em hp.preprocessed_path .
Os madeireiros do Tensorboard são armazenados no diretório log . Usar
tensorboard --logdir logPara servir o tensorboard em sua localhost. Aqui estão algumas visualizações de registro do treinamento do modelo no VCTK para 560k etapas.
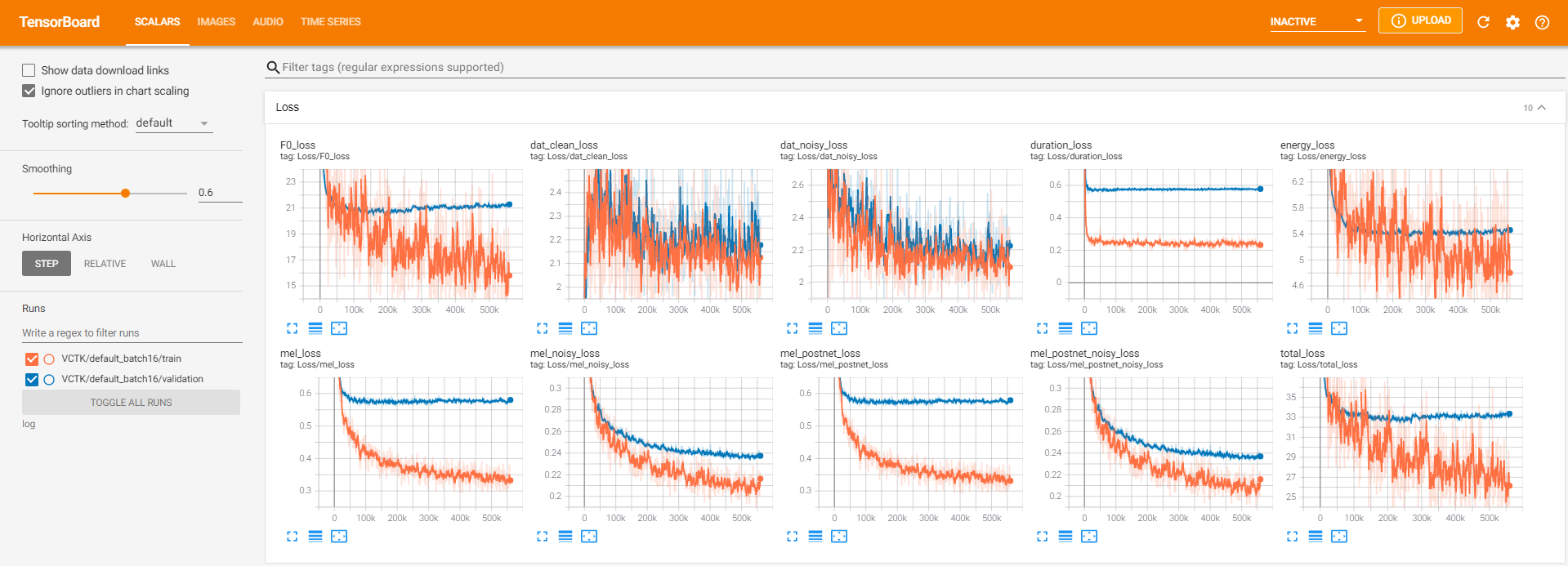
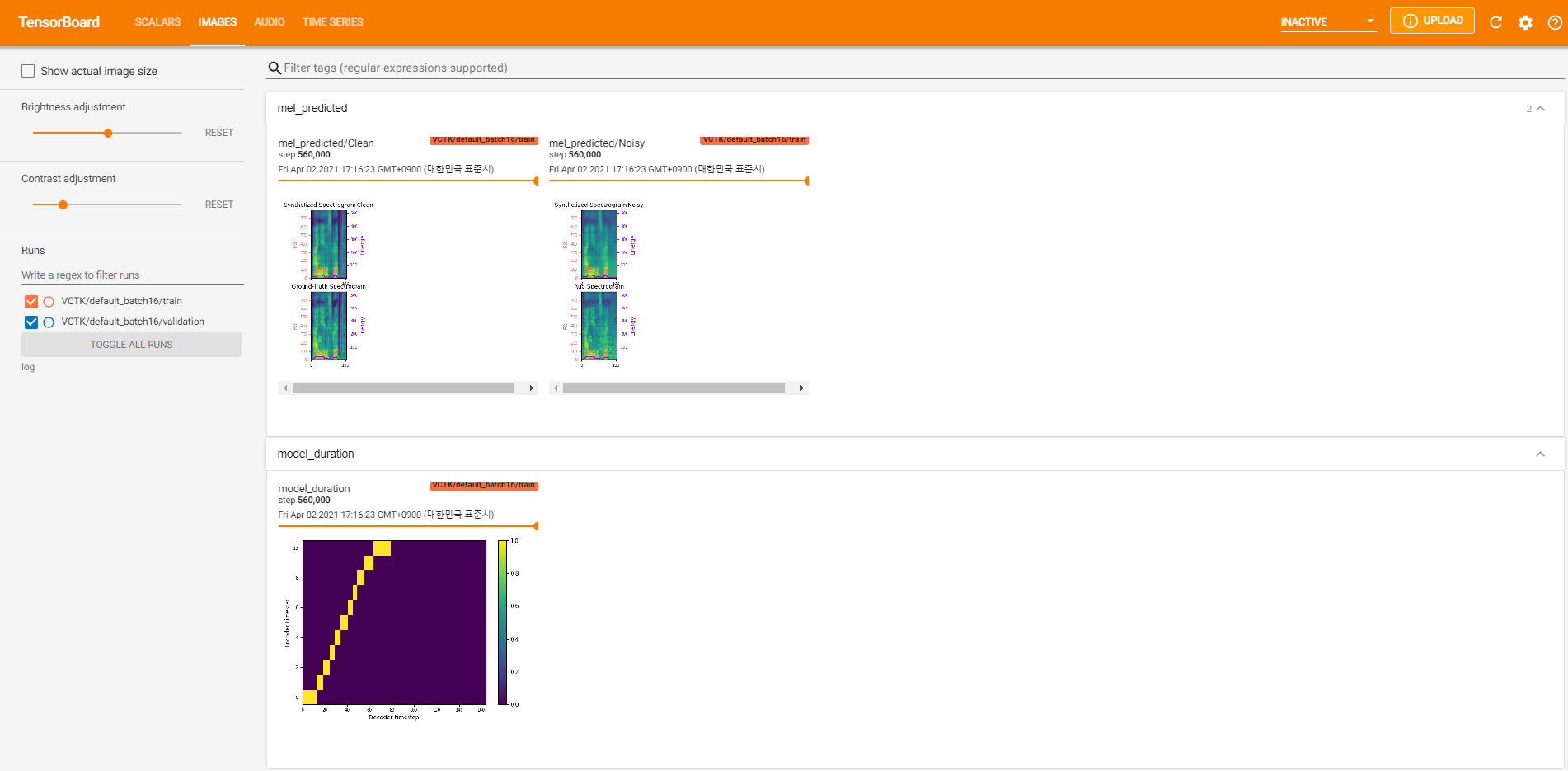
Havia muitos dados de ruído em que a extração não era possível através pyworld , como nos dados limpos. Para resolver isso, pysptk foi aplicado para extrair log F0 para a frequência fundamental dos dados ruidosos. A opção --noisy_input automatizará esse processo durante a sintetização.
Se os problemas relacionados ao MFA ocorrerem durante a execução preprocess.py , tente executar manualmente o MFA pelo comando a seguir.
# Replace $data_dir and $PREPROCESSED_PATH with ./VCTK-Corpus-92/wav48_silence_trimmed and ./preprocessed/VCTK/TextGrid, for example
./montreal-forced-aligner/bin/mfa_align $YOUR_data_dir montreal-forced-aligner/pretrained_models/librispeech-lexicon.txt english $YOUR_PREPROCESSED_PATH -j 8O DeepSpeaker no conjunto de dados VCTK mostra uma identificação clara entre os falantes. A figura a seguir mostra o gráfico de T-Sne do falante extraído incorporando nossos experimentos.
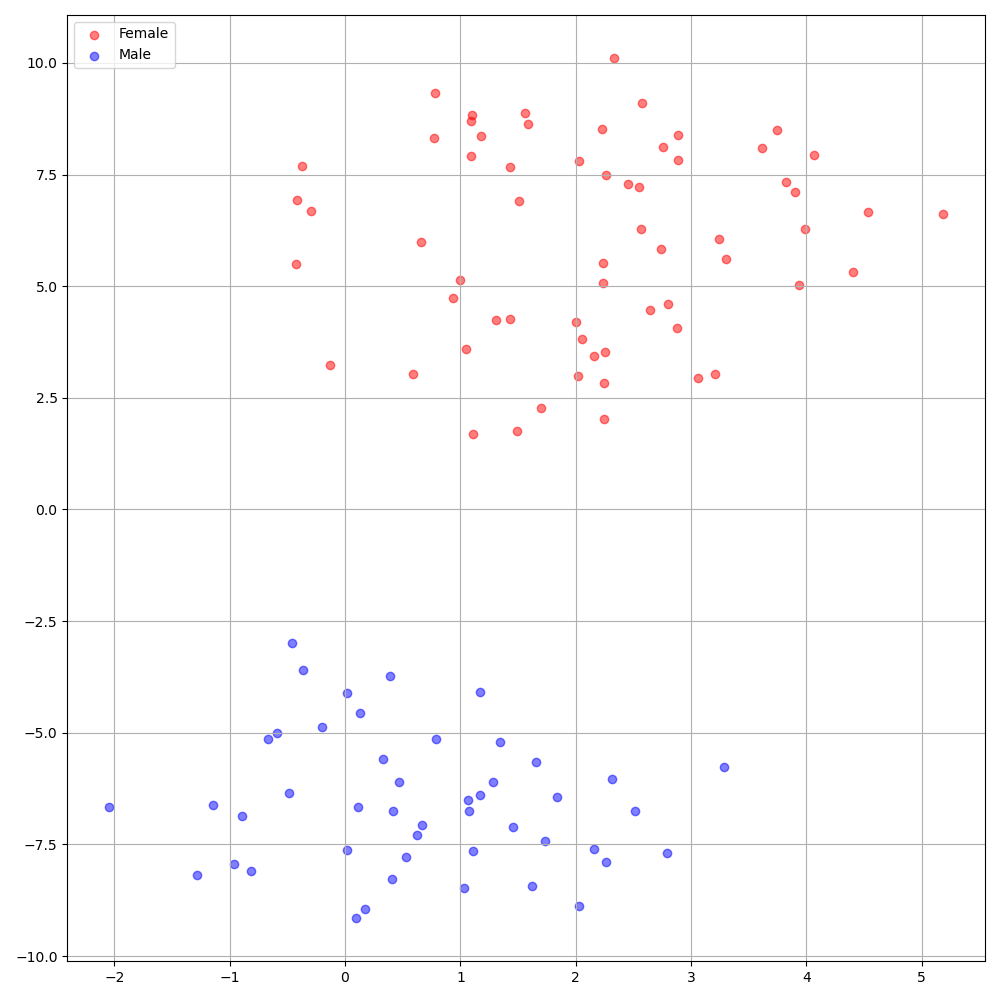
Atualmente, preprocess.py divide o conjunto de dados em dois subconjuntos: conjunto de trem e validação. Se você precisar de outros conjuntos, como um conjunto de testes, a única coisa a fazer é modificar os arquivos de texto ( train.txt ou val.txt ) em hp.preprocessed_path/ .
Se você deseja usar ou consultar esta implementação, cite nosso artigo com o repositório.
@inproceedings{lee21h_interspeech,
author={Keon Lee and Kyumin Park and Daeyoung Kim},
title={{STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech}},
year=2021,
booktitle={Proc. Interspeech 2021},
pages={4643--4647},
doi={10.21437/Interspeech.2021-838}
}

