STYLER
v1.0.0
Dalam makalah kami, kami mengusulkan Styler, kerangka kerja TTS non-autoregresif dengan pemodelan faktor gaya yang mencapai kecepatan, kekokohan, ekspresif, dan kemampuan kontrol pada saat yang sama.
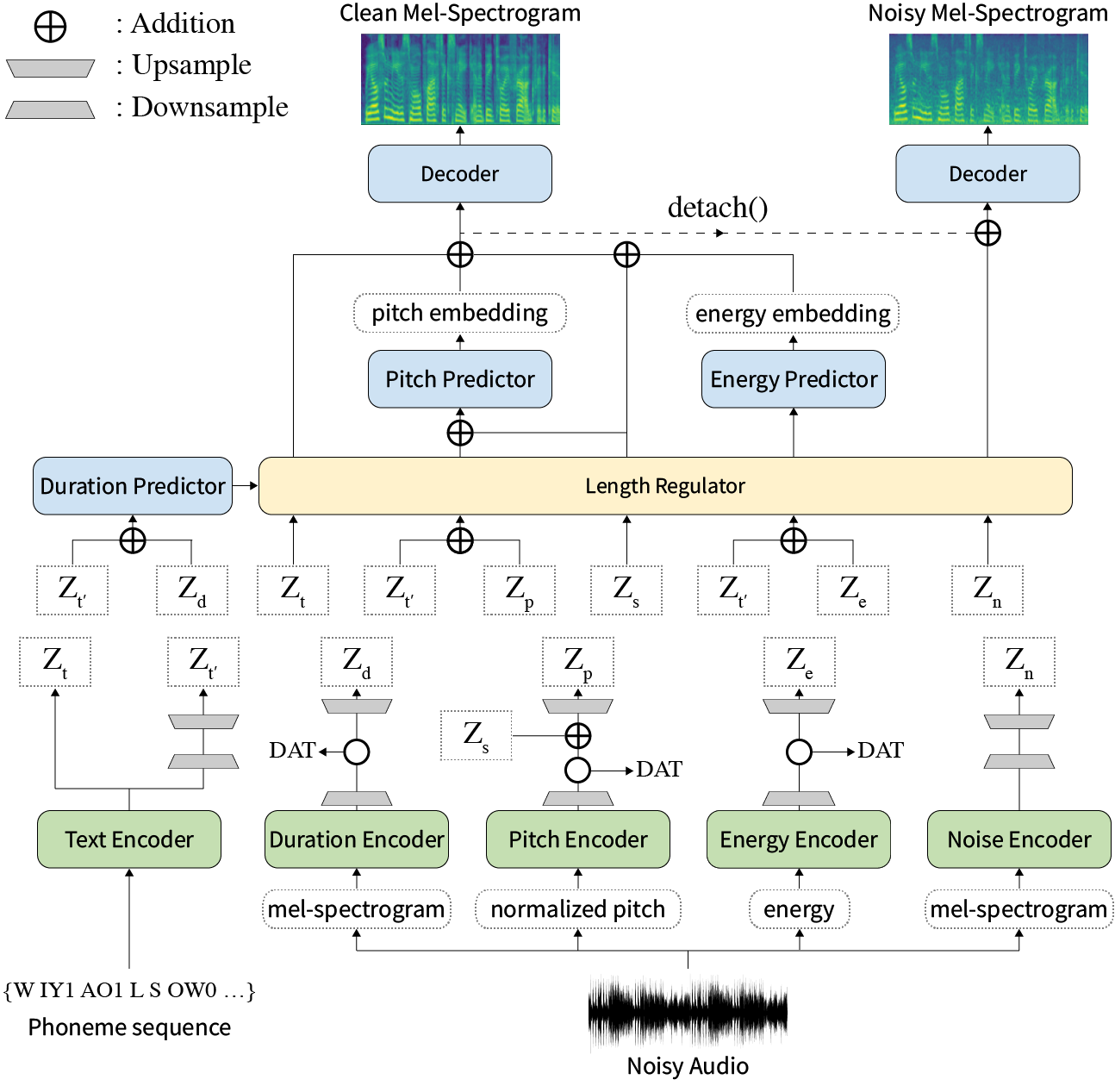
Abstrak: Karya-karya sebelumnya tentang teks-ke-pidato saraf (TTS) telah ditangani dengan kecepatan terbatas dalam pelatihan dan waktu inferensi, ketahanan untuk kondisi sintesis yang sulit, ekspresif, dan kemampuan kontrol. Meskipun beberapa pendekatan menyelesaikan beberapa keterbatasan, belum ada upaya untuk menyelesaikan semua kelemahan sekaligus. Dalam makalah ini, kami mengusulkan Styler, kerangka kerja TTS yang ekspresif dan dapat dikendalikan dengan sintesis berkecepatan tinggi dan kuat. Metode penyelarasan novel audio-teks kami yang disebut Mel Calibrator dan tidak termasuk decoding autoregresif memungkinkan pelatihan cepat dan inferensi dan sintesis yang kuat pada data yang tidak terlihat. Juga, pemodelan faktor gaya terpencil di bawah pengawasan memperbesar kemampuan kontrol dalam proses sintesis yang mengarah ke TT ekspresif. Di atasnya, pipa pemodelan kebisingan baru menggunakan pelatihan permusuhan domain dan decoding residual memberdayakan transfer gaya noise-robust noise, menguraikan kebisingan tanpa label tambahan. Berbagai percobaan menunjukkan bahwa Styler lebih efektif dalam kecepatan dan kekokohan daripada TT ekspresif dengan decoding autoregresif dan lebih ekspresif dan dapat dikendalikan daripada gaya membaca TT non-autoregresif. Sampel sintesis dan hasil percobaan disediakan melalui halaman demo kami, dan kode tersedia secara publik.
Anda dapat mengunduh model pretrained.
Harap instal dependensi Python yang diberikan dalam requirements.txt .
pip3 install -r requirements.txtdata/resample.sh untuk detailnya.hp.data_dir di hparams.py .hp.noise_dir di hparams.py .hifigan/generator_universal.pth.tar.zip di direktori yang sama. Pertama, unduh rescnn softmax+triplet pretrained model Deepspeaker Philipperemy untuk penyematan speaker seperti yang dijelaskan dalam makalah kami dan temukan di hp.speaker_embedder_dir .
Kedua, unduh paket Montreal Forced Aligner (MFA) dan file leksikon pretrained (Librispeech) melalui perintah berikut. MFA digunakan untuk mendapatkan keberpihakan antara ucapan dan urutan fonem sebagai FastSpeech2.
wget https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner/releases/download/v1.1.0-beta.2/montreal-forced-aligner_linux.tar.gz
tar -zxvf montreal-forced-aligner_linux.tar.gz
wget http://www.openslr.org/resources/11/librispeech-lexicon.txt -O montreal-forced-aligner/pretrained_models/librispeech-lexicon.txt Kemudian, proses semua fitur yang diperlukan. Anda akan mendapatkan file stat.txt di hp.preprocessed_path/ . Anda harus memodifikasi parameter F0 dan energi di hparams.py sesuai dengan konten stat.txt .
python3 preprocess.pyAkhirnya, dapatkan data berisik secara terpisah dari data bersih dengan mencampur setiap ucapan dengan sepotong kebisingan latar belakang yang dipilih secara acak dari Wham! dataset.
python3 preprocess_noisy.pySekarang Anda memiliki semua prasyarat! Latih model menggunakan perintah berikut:
python3 train.py Buat sentences.py dalam data/ yang memiliki daftar python bernama sentences teks yang akan disintesis. Perhatikan bahwa sentences dapat berisi lebih dari satu teks.
# In 'data/sentences.py',
sentences = [
" Nothing is lost, everything is recycled. "
]Persiapan audio referensi memiliki proses yang sama dengan persiapan data pelatihan. Mungkin ada dua jenis referensi: bersih dan berisik.
Pertama, letakkan audio bersih dengan teks yang sesuai dalam satu direktori dan modifikasi hp.ref_audio_dir di hparams.py dan proses semua fitur yang diperlukan. Lihat bagian Clean Data dari Train Preparation .
python3 preprocess_refs.pyKemudian, dapatkan referensi yang bising.
python3 preprocess_noisy.py --refs Perintah berikut akan mensintesis semua kombinasi teks dalam data/sentences.py dan audios di hp.ref_audio_dir .
python3 synthesize.py --ckpt CHECKPOINT_PATH Atau Anda dapat menentukan audio referensi tunggal di hp.ref_audio_dir sebagai berikut.
python3 synthesize.py --ckpt CHECKPOINT_PATH --ref_name AUDIO_FILENAMEJuga, ada beberapa opsi yang berguna.
--speaker_id akan menentukan speaker. Embedding speaker yang ditentukan harus di hp.preprocessed_path/spker_embed . Nilai default None , dan embedding speaker dihitung saat runtime pada setiap audio input.
--inspection akan memberi Anda output tambahan yang menunjukkan efek dari masing-masing encoder styler. Sampelnya sama dengan bagian Style Factor Modeling pada halaman demo kami.
--cont akan menghasilkan sampel sebagai bagian Style Factor Control pada halaman demo kami.
python3 synthesize.py --ckpt CHECKPOINT_PATH --cont --r1 AUDIO_FILENAME_1 --r2 AUDIO_FILENAME_1 Perhatikan bahwa -opsi --cont hanya bekerja pada data praproses. Secara rinci, nama audios harus memiliki format yang sama dengan dataset VCTK (misalnya, P323_229), dan data yang telah diproses harus ada di hp.preprocessed_path .
Pencatat Tensorboard disimpan di direktori log . Menggunakan
tensorboard --logdir loguntuk melayani papan tensor di localhost Anda. Berikut adalah beberapa tampilan logging dari pelatihan model pada VCTK untuk 560 ribu langkah.
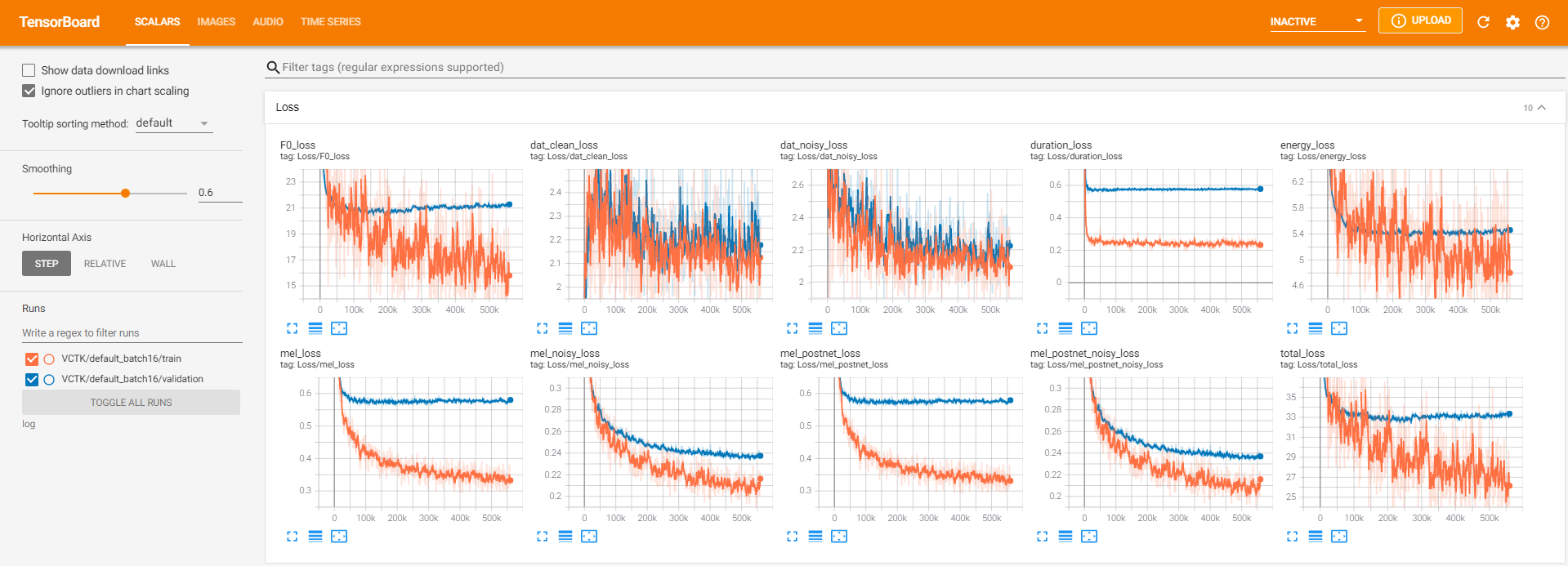
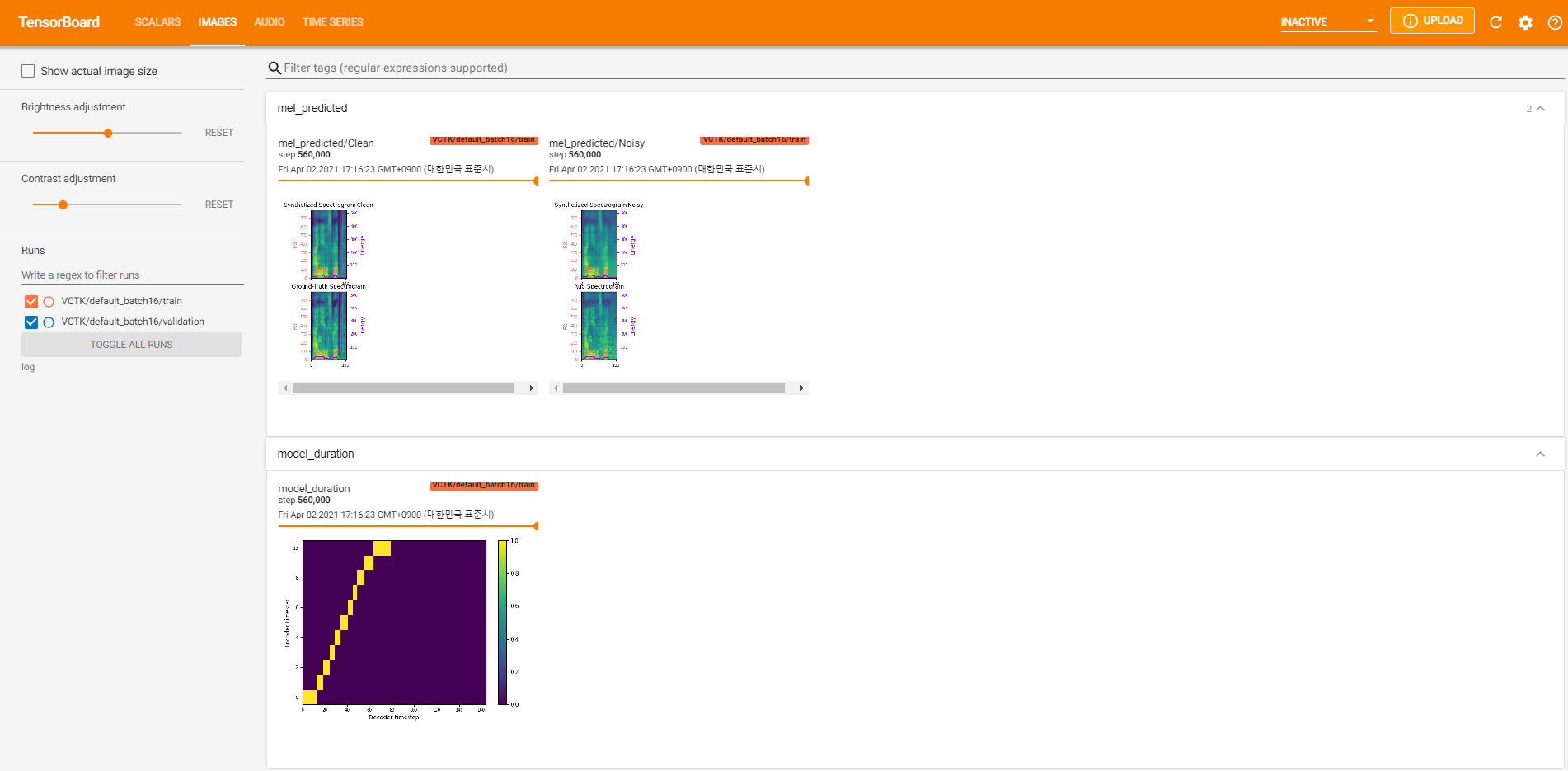
Ada terlalu banyak data kebisingan di mana ekstraksi tidak dimungkinkan melalui pyworld seperti dalam data bersih. Untuk menyelesaikannya, pysptk diterapkan untuk mengekstrak log F0 untuk frekuensi fundamental data yang berisik. Opsi --noisy_input akan mengotomatiskan proses ini selama sintesis.
Jika masalah terkait MFA terjadi selama menjalankan preprocess.py , cobalah untuk menjalankan MFA secara manual dengan perintah berikut.
# Replace $data_dir and $PREPROCESSED_PATH with ./VCTK-Corpus-92/wav48_silence_trimmed and ./preprocessed/VCTK/TextGrid, for example
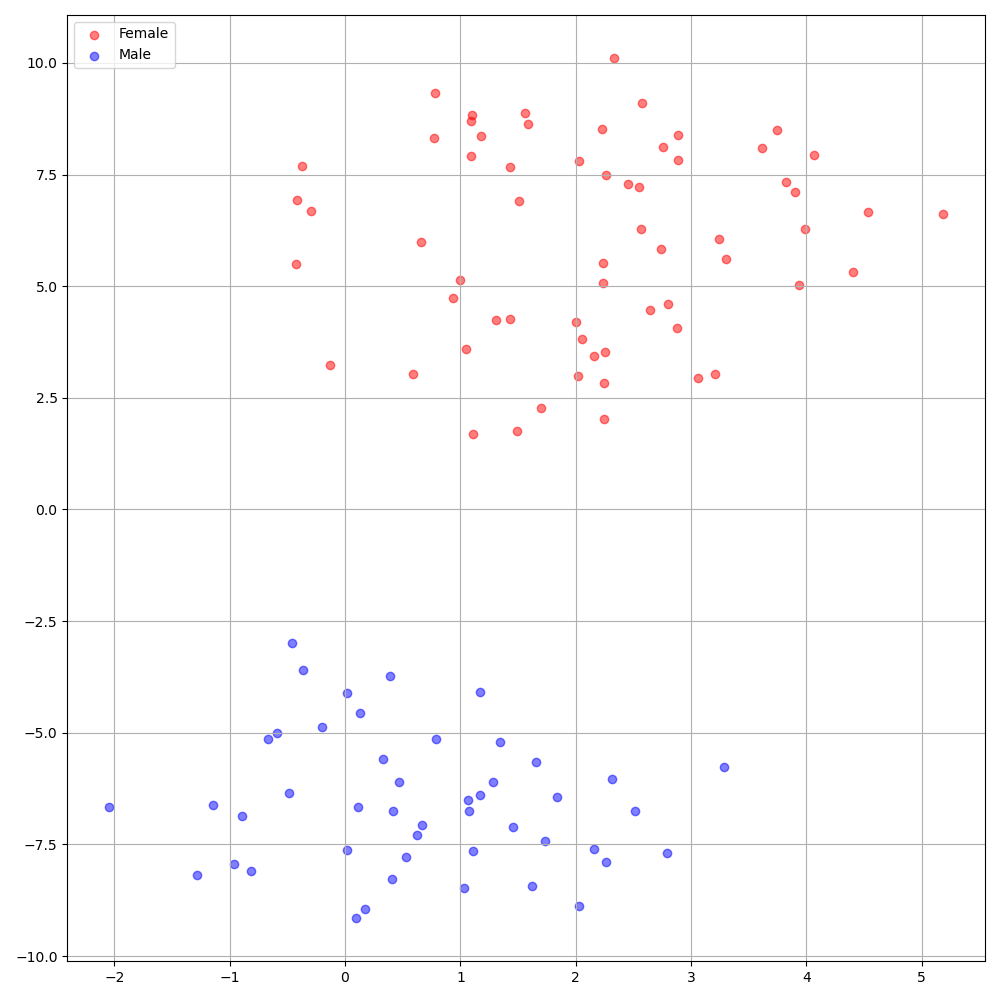
./montreal-forced-aligner/bin/mfa_align $YOUR_data_dir montreal-forced-aligner/pretrained_models/librispeech-lexicon.txt english $YOUR_PREPROCESSED_PATH -j 8Deepspeaker pada dataset VCTK menunjukkan identifikasi yang jelas di antara pembicara. Gambar berikut menunjukkan plot T-SNE dari embedding speaker yang diekstraksi dalam percobaan kami.
Saat ini, preprocess.py membagi dataset menjadi dua himpunan bagian: kereta dan set validasi. Jika Anda memerlukan set lain, seperti set tes, satu -satunya hal yang harus dilakukan adalah memodifikasi file teks ( train.txt atau val.txt ) di hp.preprocessed_path/ .
Jika Anda ingin menggunakan atau merujuk pada implementasi ini, silakan kutip makalah kami dengan repo.
@inproceedings{lee21h_interspeech,
author={Keon Lee and Kyumin Park and Daeyoung Kim},
title={{STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech}},
year=2021,
booktitle={Proc. Interspeech 2021},
pages={4643--4647},
doi={10.21437/Interspeech.2021-838}
}

