STYLER
v1.0.0
En nuestro artículo, proponemos Styler, un marco TTS no autorgresivo con modelado de factores de estilo que logra la rapidez, la robustez, la expresividad y la capacidad de control al mismo tiempo.
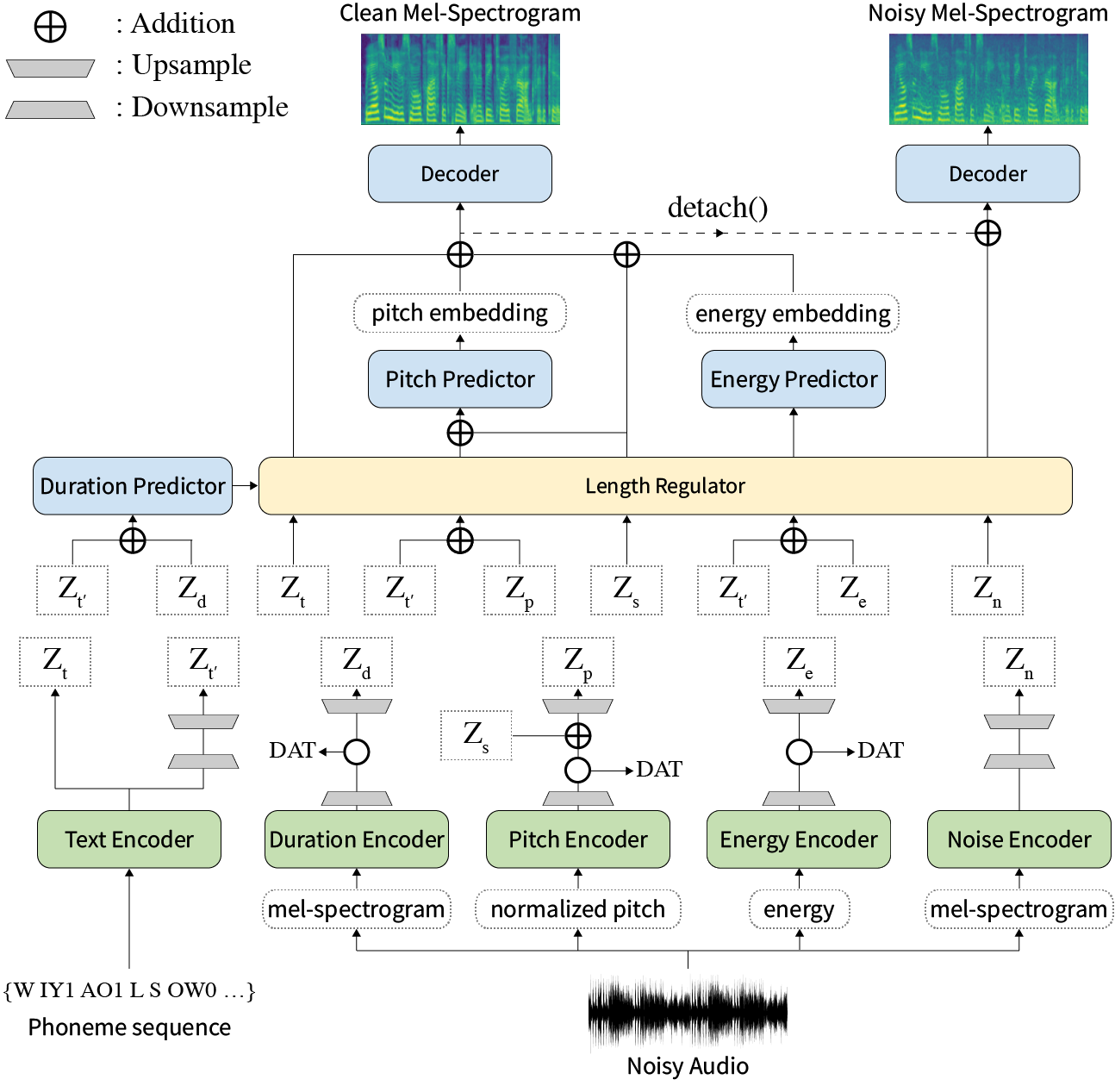
Resumen: Los trabajos anteriores sobre texto neuronal a voz (TTS) se han abordado a velocidad limitada en el tiempo de entrenamiento e inferencia, robustez para condiciones de síntesis difíciles, expresividad y capacidad de control. Aunque varios enfoques resuelven algunas limitaciones, no ha habido intento de resolver todas las debilidades a la vez. En este artículo, proponemos Styler, un marco TTS expresivo y controlable con síntesis de alta velocidad y robusta. Nuestro nuevo método de alineación de texto de audio llamado Mel Calibrador y excluyendo la decodificación autorregresiva permite un entrenamiento e inferencia rápida y una síntesis robusta en datos invisibles. Además, el modelado de factor de estilo desenredado bajo supervisión amplía la controlabilidad en la sintetización del proceso que conduce a TTS expresivos. Además de ella, una nueva tubería de modelado de ruido que utiliza entrenamiento adversario de dominio y decodificación residual empodera la transferencia de estilo-robusto, descomponiendo el ruido sin ninguna etiqueta adicional. Varios experimentos demuestran que Styler es más efectivo en la velocidad y la robustez que los TT expresivos con decodificación autorregresiva y más expresivo y controlable que el estilo de lectura TTS no autorregresivo. Las muestras de síntesis y los resultados del experimento se proporcionan a través de nuestra página de demostración, y el código está disponible públicamente.
Puede descargar modelos previos a la aparición.
Instale las dependencias de Python dadas en requirements.txt .
pip3 install -r requirements.txtdata/resample.sh para obtener el detalle.hp.data_dir en hparams.py .hp.noise_dir en hparams.py .hifigan/generator_universal.pth.tar.zip en el mismo directorio. Primero, descargue el modelo de pretrada de triplete rescnn+del triplete del Deepspeaker de Philipperemy para la incrustación del altavoz como se describe en nuestro documento y lo ubica en hp.speaker_embedder_dir .
En segundo lugar, descargue el paquete de alineador forzado de Montreal (MFA) y el archivo de léxico previamente previo (Librispeech) a través de los siguientes comandos. MFA se usa para obtener las alineaciones entre las expresiones y las secuencias de fonema como FastSpeech2.
wget https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner/releases/download/v1.1.0-beta.2/montreal-forced-aligner_linux.tar.gz
tar -zxvf montreal-forced-aligner_linux.tar.gz
wget http://www.openslr.org/resources/11/librispeech-lexicon.txt -O montreal-forced-aligner/pretrained_models/librispeech-lexicon.txt Luego, procese todas las características necesarias. Obtendrá un archivo stat.txt en su hp.preprocessed_path/ . Debe modificar los parámetros de F0 y energía en hparams.py de acuerdo con el contenido de stat.txt .
python3 preprocess.pyFinalmente, obtenga los datos ruidosos por separado de los datos limpios mezclando cada enunciado con una pieza de ruido de fondo seleccionada al azar de WHAM. conjunto de datos.
python3 preprocess_noisy.py¡Ahora tienes todos los requisitos previos! Entrena el modelo usando el siguiente comando:
python3 train.py Crear sentences.py en data/ que tiene una lista de Python con nombre de sentences de textos para ser sintetizados. Tenga en cuenta que sentences pueden contener más de un texto.
# In 'data/sentences.py',
sentences = [
" Nothing is lost, everything is recycled. "
]La preparación de audio de referencia tiene un proceso similar a la preparación de datos de capacitación. Podría haber dos tipos de referencias: limpio y ruidoso.
Primero, coloque los audios limpios con los textos correspondientes en un solo directorio y modifique el hp.ref_audio_dir en hparams.py y procese todas las características necesarias. Consulte la sección Clean Data de Train Preparation .
python3 preprocess_refs.pyLuego, obtenga las referencias ruidosas.
python3 preprocess_noisy.py --refs El siguiente comando sintetizará todas las combinaciones de textos en data/sentences.py y audios en hp.ref_audio_dir .
python3 synthesize.py --ckpt CHECKPOINT_PATH O puede especificar audio de referencia única en hp.ref_audio_dir de la siguiente manera.
python3 synthesize.py --ckpt CHECKPOINT_PATH --ref_name AUDIO_FILENAMEAdemás, hay varias opciones útiles.
--speaker_id especificará el altavoz. La incrustación del altavoz especificado debe estar en hp.preprocessed_path/spker_embed . El valor predeterminado es None , y la incrustación del altavoz se calcula en tiempo de ejecución en cada audio de entrada.
--inspection le dará salidas adicionales que muestran los efectos de cada codificador de Styler. Las muestras son las mismas que la sección Style Factor Modeling en nuestra página de demostración.
--cont generará las muestras como la sección Style Factor Control en nuestra página de demostración.
python3 synthesize.py --ckpt CHECKPOINT_PATH --cont --r1 AUDIO_FILENAME_1 --r2 AUDIO_FILENAME_1 Tenga en cuenta que la opción --cont solo está trabajando en datos preprocesados. En detalle, el nombre de los audios debe tener el mismo formato que el conjunto de datos VCTK (p. Ej., P323_229), y los datos preprocesados deben existir en hp.preprocessed_path .
Los registradores de tensorboard se almacenan en el directorio log . Usar
tensorboard --logdir logPara servir la tabla tensor en su localhost. Aquí hay algunas vistas de registro del entrenamiento modelo en VCTK para 560k pasos.
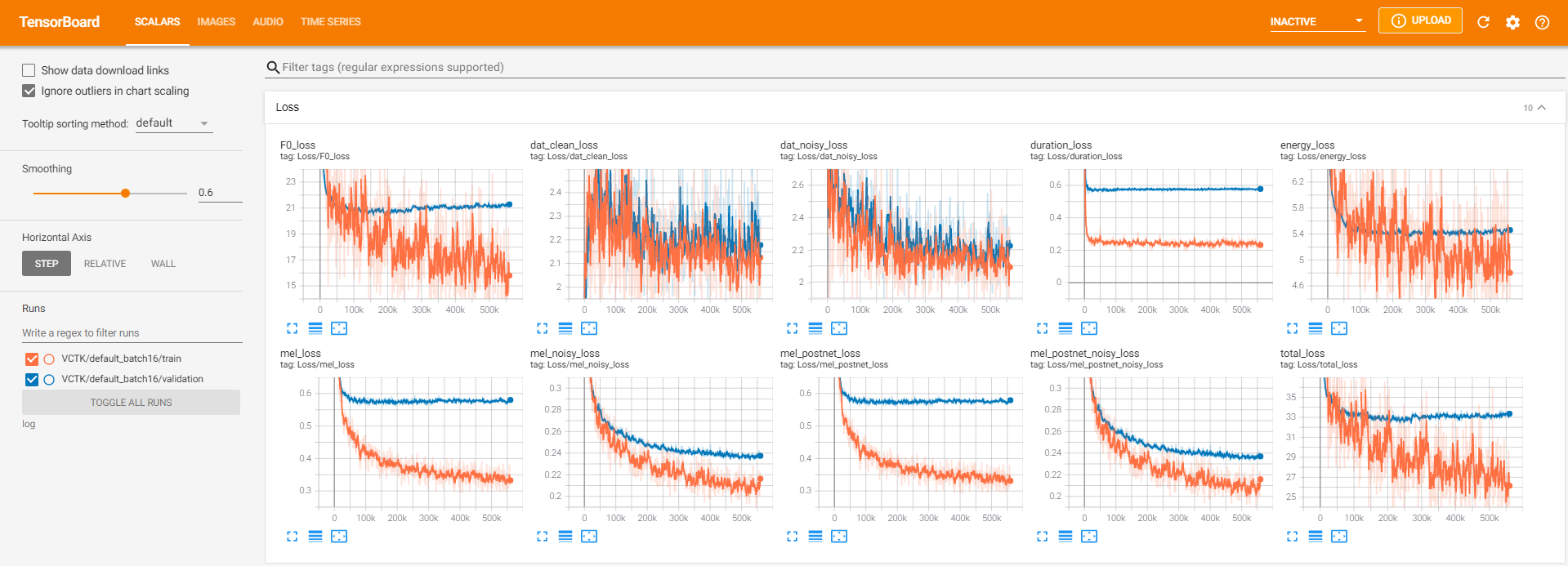
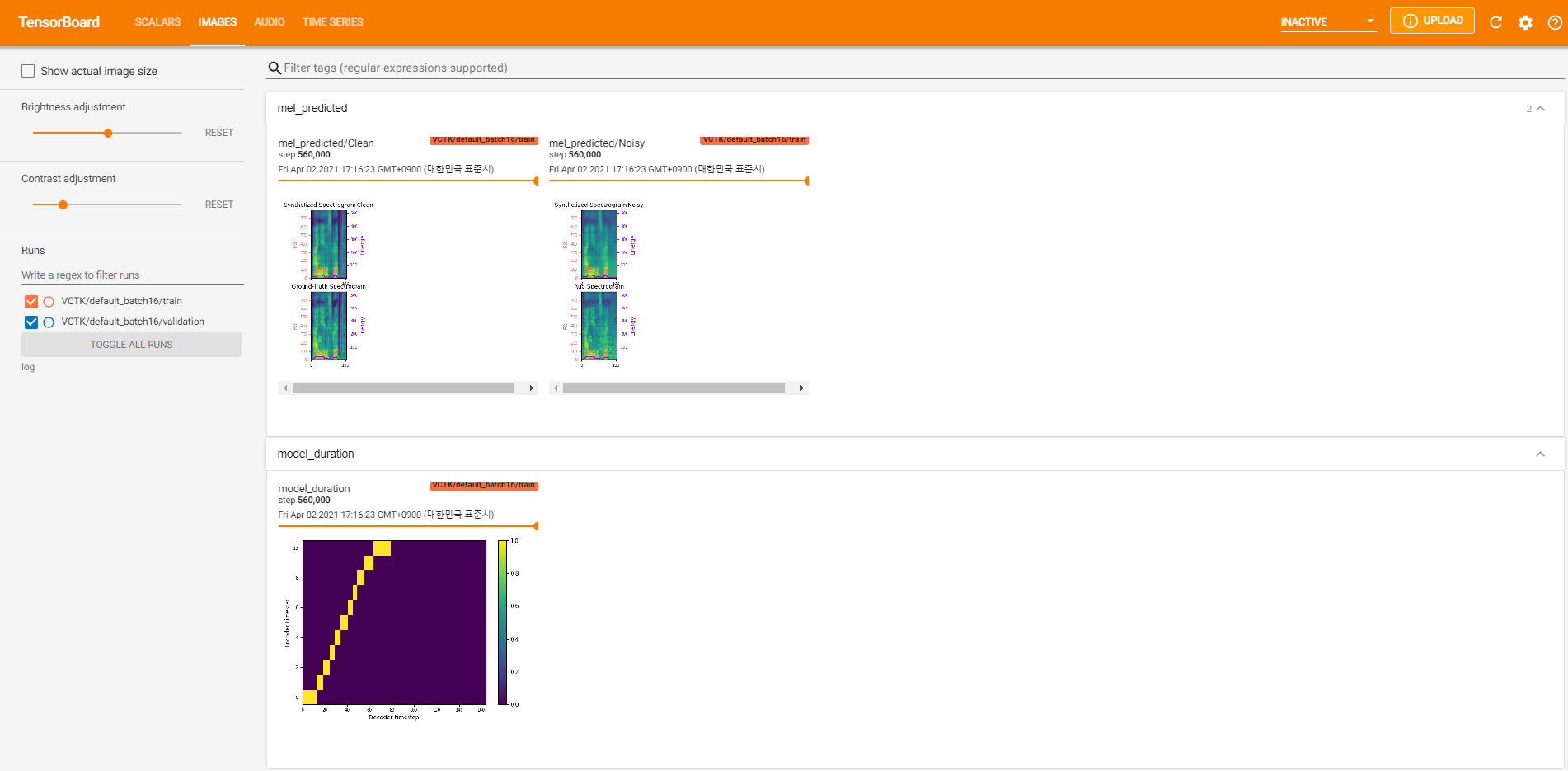
Hubo demasiados datos de ruido donde la extracción no era posible a través de pyworld como en los datos limpios. Para resolver esto, pysptk se aplicó para extraer log F0 para la frecuencia fundamental de los datos ruidosos. La opción --noisy_input automatizará este proceso durante la sintetización.
Si se producen problemas relacionados con MFA durante la ejecución preprocess.py , intente ejecutar manualmente MFA mediante el siguiente comando.
# Replace $data_dir and $PREPROCESSED_PATH with ./VCTK-Corpus-92/wav48_silence_trimmed and ./preprocessed/VCTK/TextGrid, for example
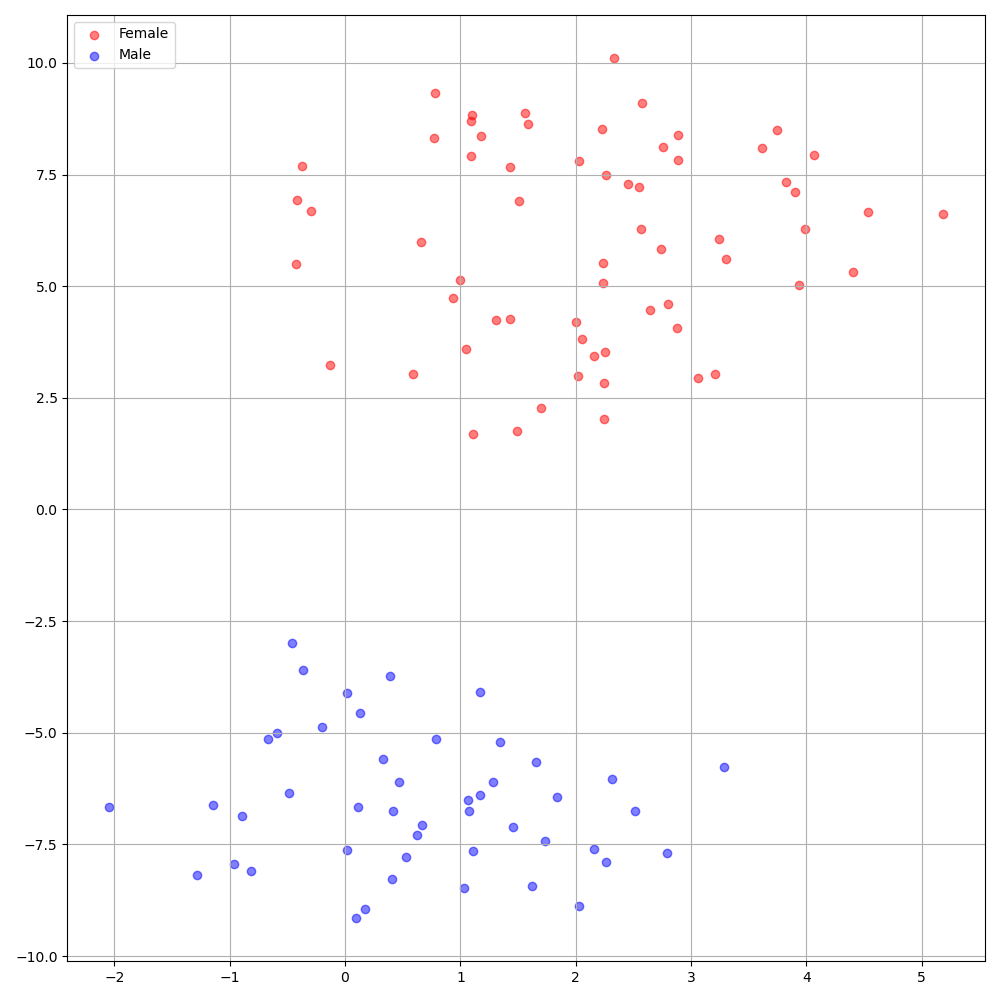
./montreal-forced-aligner/bin/mfa_align $YOUR_data_dir montreal-forced-aligner/pretrained_models/librispeech-lexicon.txt english $YOUR_PREPROCESSED_PATH -j 8Deepspeaker en el conjunto de datos VCTK muestra una identificación clara entre los oradores. La siguiente figura muestra la gráfica T-SNE de la incrustación de altavoz extraído en nuestros experimentos.
Actualmente, preprocess.py divide el conjunto de datos en dos subconjuntos: conjunto de trenes y validación. Si necesita otros conjuntos, como un conjunto de pruebas, lo único que debe hacer es modificar los archivos de texto ( train.txt o val.txt ) en hp.preprocessed_path/ .
Si desea usar o consultar esta implementación, cite nuestro documento con el repositorio.
@inproceedings{lee21h_interspeech,
author={Keon Lee and Kyumin Park and Daeyoung Kim},
title={{STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech}},
year=2021,
booktitle={Proc. Interspeech 2021},
pages={4643--4647},
doi={10.21437/Interspeech.2021-838}
}

