STYLER
v1.0.0
ในบทความของเราเราเสนอ Styler ซึ่งเป็นกรอบ TTS ที่ไม่ได้เป็นตัวอักษรที่มีการสร้างแบบจำลองปัจจัยสไตล์ที่บรรลุความรวดเร็วความทนทานการแสดงออกและการควบคุมในเวลาเดียวกัน
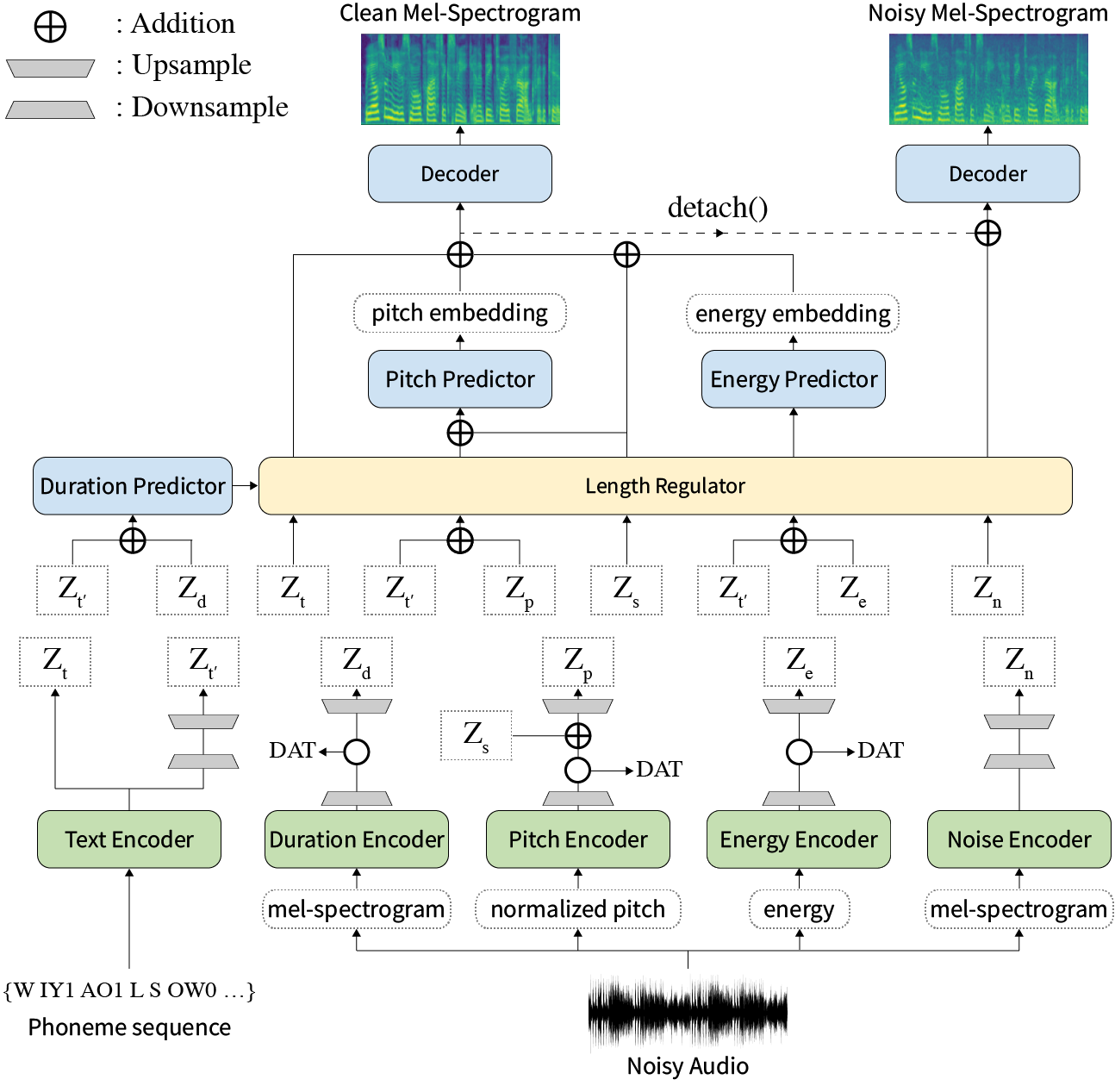
บทคัดย่อ: งานก่อนหน้านี้เกี่ยวกับข้อความประสาทต่อการพูด (TTS) ได้รับการแก้ไขด้วยความเร็วที่ จำกัด ในการฝึกอบรมและเวลาการอนุมานความทนทานสำหรับเงื่อนไขการสังเคราะห์ที่ยากลำบากการแสดงออกและการควบคุมได้ แม้ว่าหลายวิธีจะแก้ไขข้อ จำกัด บางอย่าง แต่ก็ไม่มีความพยายามที่จะแก้ปัญหาจุดอ่อนทั้งหมดในครั้งเดียว ในบทความนี้เราเสนอ Styler ซึ่งเป็นกรอบ TTS ที่แสดงออกและควบคุมได้พร้อมการสังเคราะห์ความเร็วสูงและแข็งแกร่ง วิธีการจัดแนวข้อความเสียงใหม่ของเราที่เรียกว่า Mel Calibrator และไม่รวมการถอดรหัสแบบอัตโนมัติเปิดใช้งานการฝึกอบรมอย่างรวดเร็วและการอนุมานและการสังเคราะห์ที่แข็งแกร่งในข้อมูลที่มองไม่เห็น นอกจากนี้การสร้างแบบจำลองปัจจัยสไตล์ที่แยกออกจากกันภายใต้การกำกับดูแลขยายความสามารถในการควบคุมในกระบวนการสังเคราะห์ที่นำไปสู่ TTs ที่แสดงออก ด้านบนของมันไปป์ไลน์การสร้างแบบจำลองเสียงรบกวนใหม่โดยใช้การฝึกอบรมด้านตรงข้ามโดเมนและการถอดรหัสที่ตกค้างช่วยให้การถ่ายโอนรูปแบบเสียงรบกวนเสียงรบกวนการย่อยสลายเสียงรบกวนโดยไม่ต้องมีฉลากเพิ่มเติม การทดลองต่าง ๆ แสดงให้เห็นว่า Styler มีประสิทธิภาพในด้านความเร็วและความทนทานมากกว่า TTS ที่แสดงออกด้วยการถอดรหัสแบบอัตโนมัติและการแสดงออกและควบคุมได้มากกว่าการอ่านสไตล์ TT ที่ไม่ใช่แบบอัตโนมัติ ตัวอย่างการสังเคราะห์และผลการทดลองมีให้ผ่านหน้าสาธิตของเราและรหัสจะเปิดเผยต่อสาธารณะ
คุณสามารถดาวน์โหลดโมเดลที่ผ่านการฝึกอบรมได้
โปรดติดตั้งการพึ่งพา Python ที่ให้ไว้ใน requirements.txt . txt
pip3 install -r requirements.txtdata/resample.sh สำหรับรายละเอียดhp.data_dir ใน hparams.pyhp.noise_dir ใน hparams.pyhifigan/generator_universal.pth.tar.zip ในไดเรกทอรีเดียวกัน ก่อนอื่นให้ดาวน์โหลดแบบจำลอง Rescnn Softmax+Triplet Pretrain ของ Deepspeaker ของ Philipperemy สำหรับการฝังลำโพงตามที่อธิบายไว้ในกระดาษของเราและค้นหาใน hp.speaker_embedder_dir
ประการที่สองดาวน์โหลดแพ็คเกจ Montreal Forced Aligner (MFA) และไฟล์พจนานุกรม (librispeech) ที่ได้รับการฝึกฝนผ่านคำสั่งต่อไปนี้ MFA ใช้เพื่อให้ได้การจัดตำแหน่งระหว่างคำพูดและลำดับฟอนิมเป็น fastspeech2
wget https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner/releases/download/v1.1.0-beta.2/montreal-forced-aligner_linux.tar.gz
tar -zxvf montreal-forced-aligner_linux.tar.gz
wget http://www.openslr.org/resources/11/librispeech-lexicon.txt -O montreal-forced-aligner/pretrained_models/librispeech-lexicon.txt จากนั้นประมวลผลคุณสมบัติที่จำเป็นทั้งหมด คุณจะได้รับไฟล์ stat.txt ใน hp.preprocessed_path/ คุณต้องปรับเปลี่ยนพารามิเตอร์ F0 และพลังงานใน hparams.py ตามเนื้อหาของ stat.txt
python3 preprocess.pyในที่สุดรับข้อมูลที่มีเสียงดังแยกออกจากข้อมูลที่สะอาดโดยการผสมคำพูดแต่ละคำด้วยเสียงพื้นหลังที่เลือกแบบสุ่มจาก WHAM! ชุดข้อมูล
python3 preprocess_noisy.pyตอนนี้คุณมีข้อกำหนดเบื้องต้นทั้งหมดแล้ว! ฝึกอบรมแบบจำลองโดยใช้คำสั่งต่อไปนี้:
python3 train.py สร้าง sentences.py ใน data/ ที่มีรายการ Python ชื่อ sentences ของข้อความที่จะสังเคราะห์ โปรดทราบว่า sentences สามารถมีข้อความได้มากกว่าหนึ่งข้อความ
# In 'data/sentences.py',
sentences = [
" Nothing is lost, everything is recycled. "
]การเตรียมเสียงอ้างอิงมีกระบวนการที่คล้ายกันกับการเตรียมข้อมูลการฝึกอบรม อาจมีการอ้างอิงสองประเภท: สะอาดและมีเสียงดัง
ขั้นแรกให้ใส่เสียงที่สะอาดด้วยข้อความที่สอดคล้องกันในไดเรกทอรีเดียวและแก้ไข hp.ref_audio_dir ใน hparams.py และประมวลผลคุณสมบัติที่จำเป็นทั้งหมด อ้างถึงส่วน Clean Data ของ Train Preparation
python3 preprocess_refs.pyจากนั้นรับการอ้างอิงที่มีเสียงดัง
python3 preprocess_noisy.py --refs คำสั่งต่อไปนี้จะสังเคราะห์ชุดข้อความทั้งหมดใน data/sentences.py และเสียงใน hp.ref_audio_dir
python3 synthesize.py --ckpt CHECKPOINT_PATH หรือคุณสามารถระบุเสียงอ้างอิงเดียวใน hp.ref_audio_dir ดังต่อไปนี้
python3 synthesize.py --ckpt CHECKPOINT_PATH --ref_name AUDIO_FILENAMEนอกจากนี้ยังมีตัวเลือกที่มีประโยชน์มากมาย
--speaker_id จะระบุลำโพง การฝังของผู้พูดที่ระบุควรอยู่ใน hp.preprocessed_path/spker_embed ค่าเริ่มต้นคือ None และการฝังลำโพงจะคำนวณที่รันไทม์ในแต่ละเสียงอินพุต
--inspection จะให้เอาต์พุตเพิ่มเติมที่แสดงผลของแต่ละ encoder ของ styler ตัวอย่างเหมือนกับส่วน Style Factor Modeling ในหน้าสาธิตของเรา
--cont จะสร้างตัวอย่างเป็นส่วน Style Factor Control ในหน้าสาธิตของเรา
python3 synthesize.py --ckpt CHECKPOINT_PATH --cont --r1 AUDIO_FILENAME_1 --r2 AUDIO_FILENAME_1 โปรดทราบว่า --cont ตัวเลือกคอนเนตทำงานกับข้อมูลที่ประมวลผลล่วงหน้าเท่านั้น ในรายละเอียดชื่อของเสียงควรมีรูปแบบเดียวกับชุดข้อมูล VCTK (เช่น p323_229) และข้อมูลที่ประมวลผลล่วงหน้าจะต้องมีอยู่ใน hp.preprocessed_path
ตัวบันทึกเทนซอร์บอร์ดจะถูกเก็บไว้ในไดเรกทอรี log ใช้
tensorboard --logdir logเพื่อให้บริการ tensorboard ในท้องถิ่นของคุณ นี่คือมุมมองการบันทึกของการฝึกอบรมแบบจำลองบน VCTK สำหรับขั้นตอน 560k
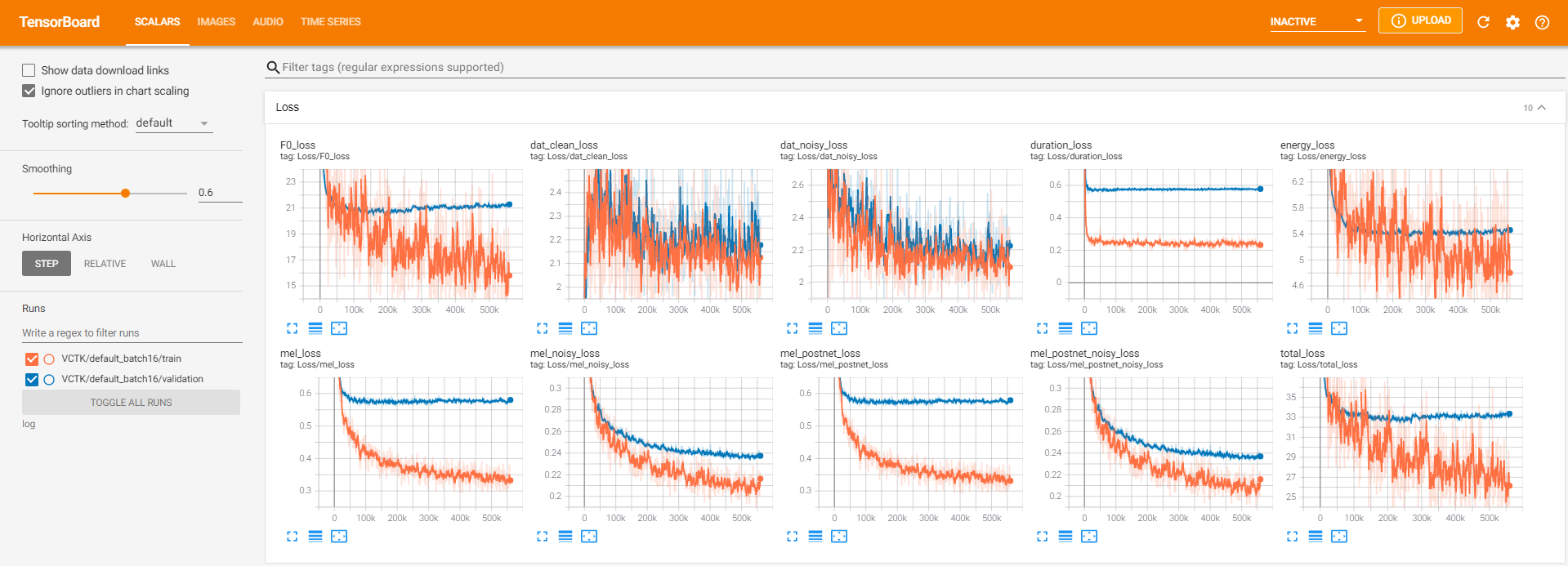
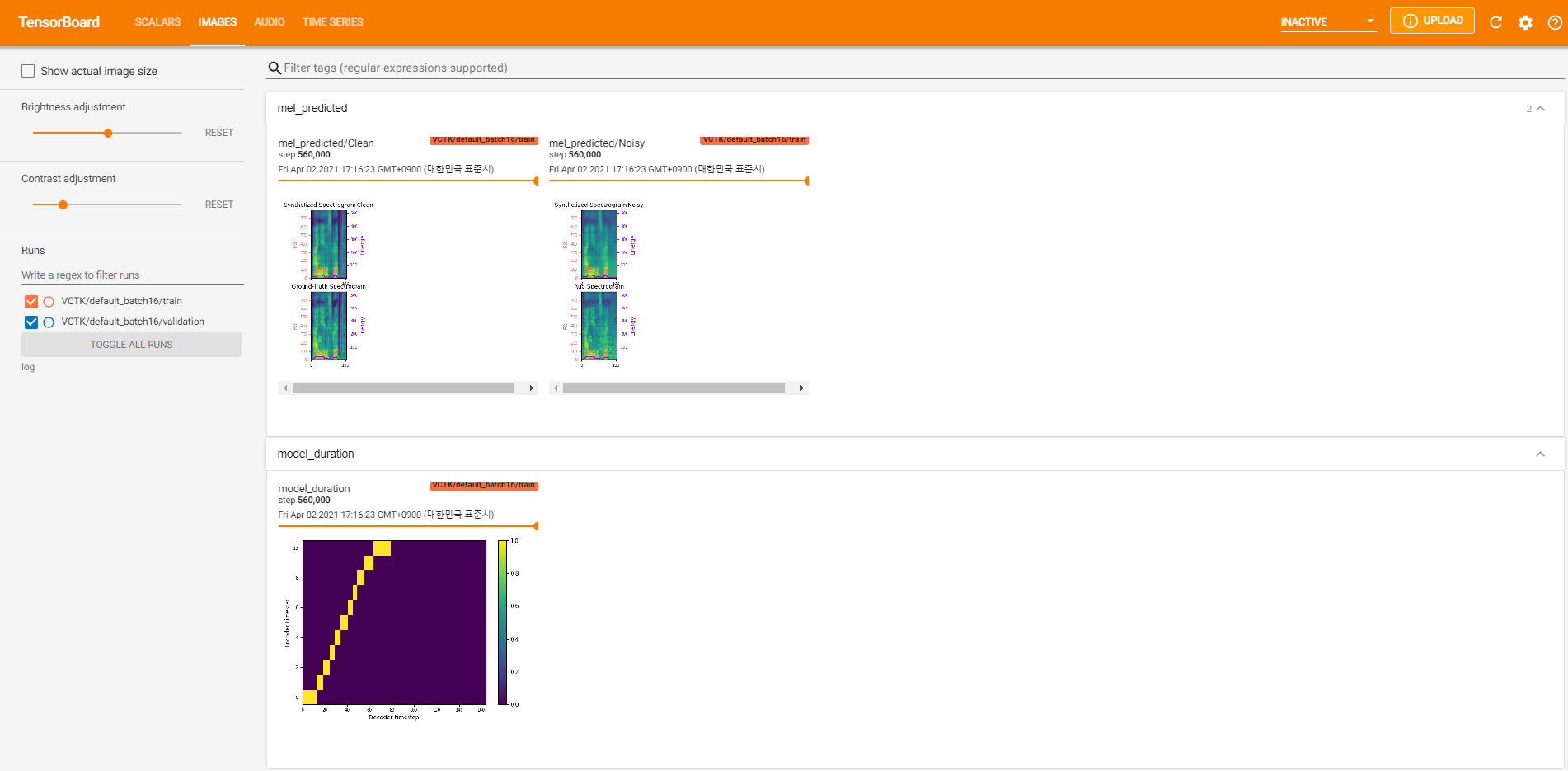
มีข้อมูลเสียงรบกวนมากเกินไปที่ไม่สามารถสกัดได้ผ่าน pyworld เช่นเดียวกับในข้อมูลที่สะอาด เพื่อแก้ไขปัญหานี้ pysptk ถูกนำไปใช้เพื่อแยกบันทึก F0 สำหรับความถี่พื้นฐานของข้อมูลที่มีเสียงดัง ตัวเลือก --noisy_input จะทำให้กระบวนการนี้เป็นไปโดยอัตโนมัติในระหว่างการสังเคราะห์
หากปัญหาที่เกี่ยวข้องกับ MFA เกิดขึ้นระหว่างการประมวล preprocess.py ลองใช้ MFA ด้วยตนเองโดยคำสั่งต่อไปนี้
# Replace $data_dir and $PREPROCESSED_PATH with ./VCTK-Corpus-92/wav48_silence_trimmed and ./preprocessed/VCTK/TextGrid, for example
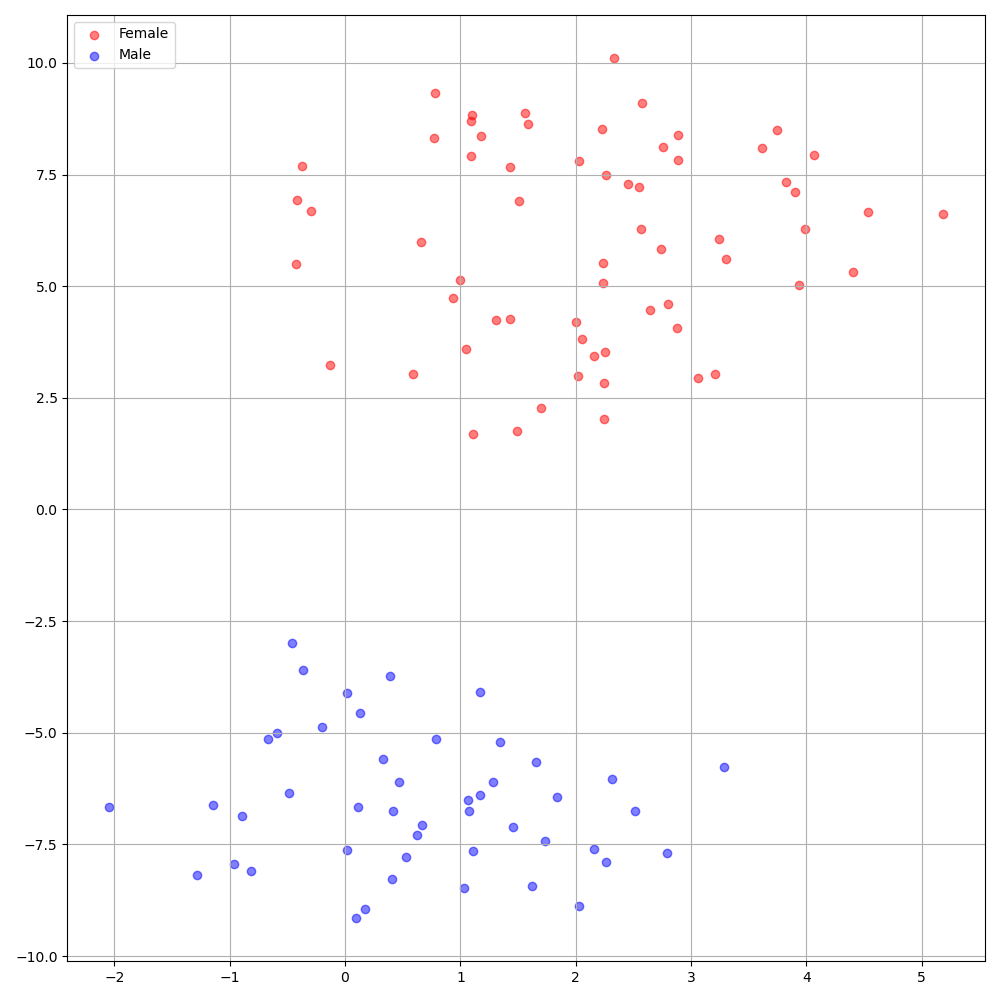
./montreal-forced-aligner/bin/mfa_align $YOUR_data_dir montreal-forced-aligner/pretrained_models/librispeech-lexicon.txt english $YOUR_PREPROCESSED_PATH -j 8Deepspeaker บนชุดข้อมูล VCTK แสดงการระบุที่ชัดเจนระหว่างลำโพง รูปต่อไปนี้แสดงพล็อต T-SNE ของการฝังลำโพงที่แยกออกมาในการทดลองของเรา
ปัจจุบัน preprocess.py แบ่งชุดข้อมูลออกเป็นสองชุดย่อย: ชุดรถไฟและการตรวจสอบความถูกต้อง หากคุณต้องการชุดอื่นเช่นชุดทดสอบสิ่งเดียวที่ต้องทำคือการแก้ไขไฟล์ข้อความ ( train.txt หรือ val.txt ) ใน hp.preprocessed_path/
หากคุณต้องการใช้หรืออ้างถึงการใช้งานนี้โปรดอ้างอิงกระดาษของเราด้วย repo
@inproceedings{lee21h_interspeech,
author={Keon Lee and Kyumin Park and Daeyoung Kim},
title={{STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech}},
year=2021,
booktitle={Proc. Interspeech 2021},
pages={4643--4647},
doi={10.21437/Interspeech.2021-838}
}

