STYLER
v1.0.0
우리의 논문에서, 우리는 스타일 요인 모델링을 갖춘 비유로 인한 TTS 프레임 워크 인 스타일러를 제안하여 속도, 견고성, 표현성 및 제어 성을 동시에 달성합니다.
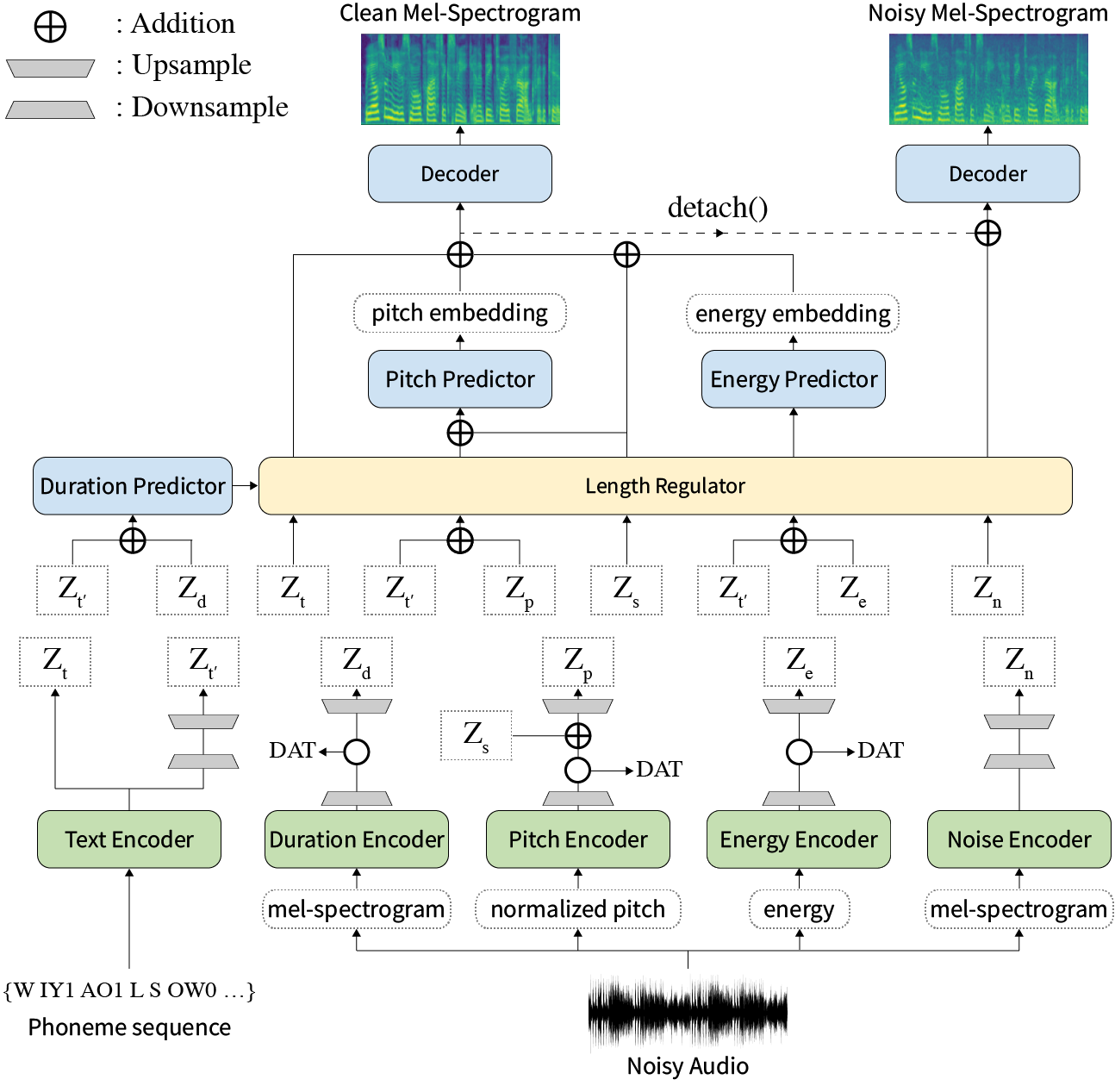
초록 : 신경 텍스트 음성 연설 (TTS)에 대한 이전 작품은 훈련 및 추론 시간, 어려운 합성 조건, 표현성 및 제어성에 대한 견고성에서 제한된 속도로 다루어졌습니다. 몇 가지 접근 방식이 일부 한계를 해결하지만 한 번에 모든 약점을 해결하려는 시도는 없었습니다. 이 논문에서는 고속 및 강력한 합성을 갖춘 표현적이고 제어 가능한 TTS 프레임 워크 인 스타일러를 제안합니다. Mel Calibrator라는 새로운 오디오 텍스트 정렬 방법을 제외하고자가 회귀 디코딩을 제외하면 보이지 않는 데이터에 대한 빠른 훈련 및 추론 및 강력한 합성이 가능합니다. 또한 감독하에있는 스타일 팩터 모델링이 분리되어 공정 합성의 제어 성을 확대시킵니다. 또한 도메인 대적 훈련 및 잔류 디코딩을 사용하는 새로운 노이즈 모델링 파이프 라인은 소음으로 인한 스타일 전송을 강화하여 추가 레이블없이 노이즈를 분해합니다. 다양한 실험은 스타일러가자가 회귀 디코딩을 갖는 표현 TT보다 속도와 견고성에 더 효과적이며 독서 스타일의 비 유적 인 회귀 TT보다 표현력이 뛰어나고 제어 가능하다는 것을 보여줍니다. 합성 샘플 및 실험 결과는 데모 페이지를 통해 제공되며 코드는 공개적으로 제공됩니다.
사전에 사전 모델을 다운로드 할 수 있습니다.
requirements.txt 에 따라 주어진 Python 종속성을 설치하십시오.
pip3 install -r requirements.txtdata/resample.sh 참조하십시오.hp.data_dir 를 hparams.py 에서 수정하십시오.hp.noise_dir 를 hparams.py 에서 수정하십시오.hifigan/generator_universal.pth.tar.zip 동일한 디렉토리에서. 먼저, 우리 논문에 설명 된대로 스피커 임베딩을 위해 Philipperemy의 Deepspeaker의 rescnn softmax+triplet 모델을 다운로드하여 hp.speaker_embedder_dir 에서 찾으십시오.
둘째, MFA (Montreal) 강제 Aligner (MFA) 패키지와 다음 명령을 통해 사전에 사전화 된 (Librispeech) Lexicon 파일을 다운로드하십시오. MFA는 FASTSPEECH2로 발화와 음소 시퀀스 사이의 정렬을 얻는 데 사용됩니다.
wget https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner/releases/download/v1.1.0-beta.2/montreal-forced-aligner_linux.tar.gz
tar -zxvf montreal-forced-aligner_linux.tar.gz
wget http://www.openslr.org/resources/11/librispeech-lexicon.txt -O montreal-forced-aligner/pretrained_models/librispeech-lexicon.txt 그런 다음 필요한 모든 기능을 처리하십시오. hp.preprocessed_path/ 에 stat.txt 파일이 나타납니다. stat.txt 의 내용에 따라 hparams.py 에서 f0 및 에너지 매개 변수를 수정해야합니다.
python3 preprocess.py마지막으로, 각 발화를 WHAM에서 무작위로 선택한 배경 노이즈와 혼합하여 청정 데이터와 별도로 시끄러운 데이터를 얻으십시오! 데이터 세트.
python3 preprocess_noisy.py이제 당신은 모든 전제 조건이 있습니다! 다음 명령을 사용하여 모델을 훈련하십시오.
python3 train.py data/ 에서 sentences.py 작성/ 합성 할 텍스트의 sentences 이라는 Python 목록이 있습니다. sentences 에는 하나 이상의 텍스트가 포함될 수 있습니다.
# In 'data/sentences.py',
sentences = [
" Nothing is lost, everything is recycled. "
]참조 오디오 준비는 교육 데이터 준비와 유사한 프로세스를 가지고 있습니다. 깨끗하고 시끄러운 두 종류의 참고 문헌이있을 수 있습니다.
먼저, 해당 텍스트가 단일 디렉토리로 깨끗한 오디오를 넣고 hp.ref_audio_dir hparams.py 를 수정하고 필요한 모든 기능을 처리하십시오. Train Preparation 의 Clean Data 섹션을 참조하십시오.
python3 preprocess_refs.py그런 다음 시끄러운 참조를 얻으십시오.
python3 preprocess_noisy.py --refs 다음 명령은 hp.ref_audio_dir 의 data/sentences.py 및 오디오의 텍스트의 모든 조합을 종합합니다.
python3 synthesize.py --ckpt CHECKPOINT_PATH 또는 다음과 같이 hp.ref_audio_dir 에서 단일 참조 오디오를 지정할 수 있습니다.
python3 synthesize.py --ckpt CHECKPOINT_PATH --ref_name AUDIO_FILENAME또한 몇 가지 유용한 옵션이 있습니다.
--speaker_id 스피커를 지정합니다. 지정된 스피커의 임베딩은 hp.preprocessed_path/spker_embed 에 있어야합니다. 기본값은 None 스피커 임베딩은 각 입력 오디오에서 런타임에 계산됩니다.
--inspection 스타일러의 각 인코더의 효과를 보여주는 추가 출력을 제공합니다. 샘플은 데모 페이지의 Style Factor Modeling 섹션과 동일합니다.
--cont 데모 페이지의 Style Factor Control 섹션으로 샘플을 생성합니다.
python3 synthesize.py --ckpt CHECKPOINT_PATH --cont --r1 AUDIO_FILENAME_1 --r2 AUDIO_FILENAME_1 --cont 옵션은 전처리 데이터에서만 작동합니다. 자세히 오디오의 이름은 VCTK 데이터 세트 (예 : P323_229)와 동일한 형식을 가져야하며, 전처리 된 데이터는 hp.preprocessed_path 에 존재해야합니다.
텐서 보드 로거는 log 디렉토리에 저장됩니다. 사용
tensorboard --logdir log지역 호스트에서 텐서 보드를 제공합니다. 다음은 560K 단계에 대한 VCTK에 대한 모델 교육의 로깅보기입니다.
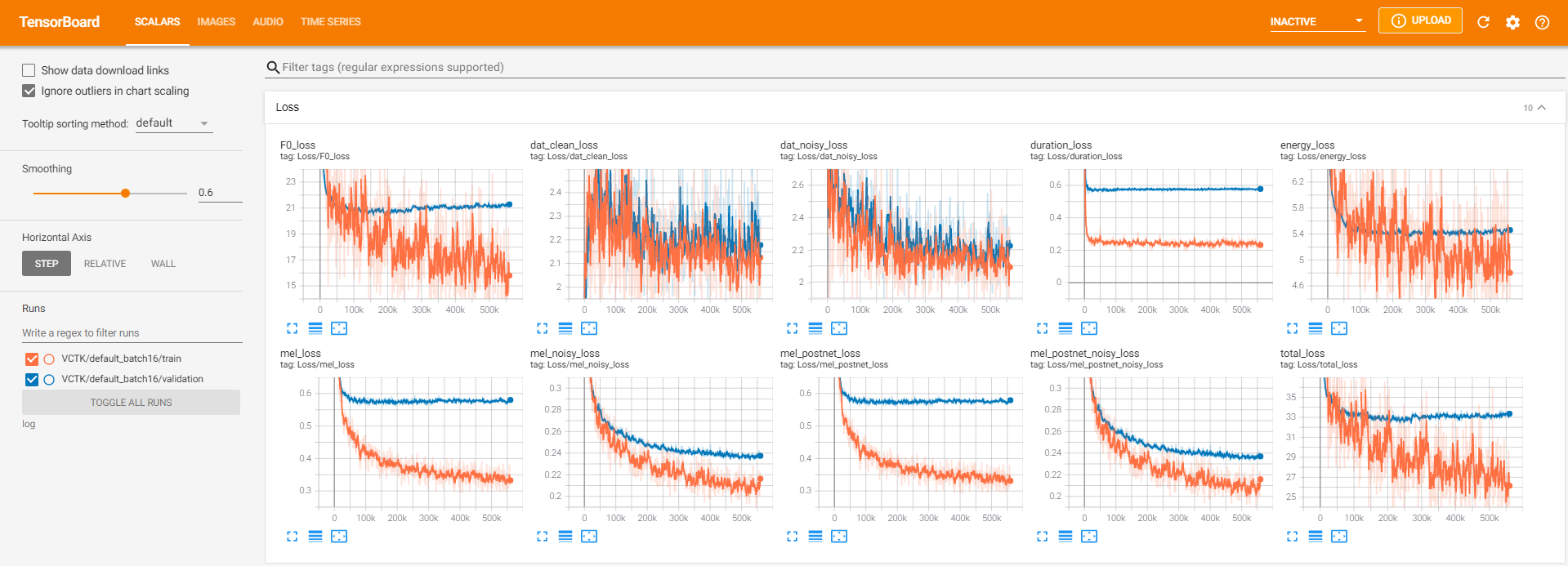
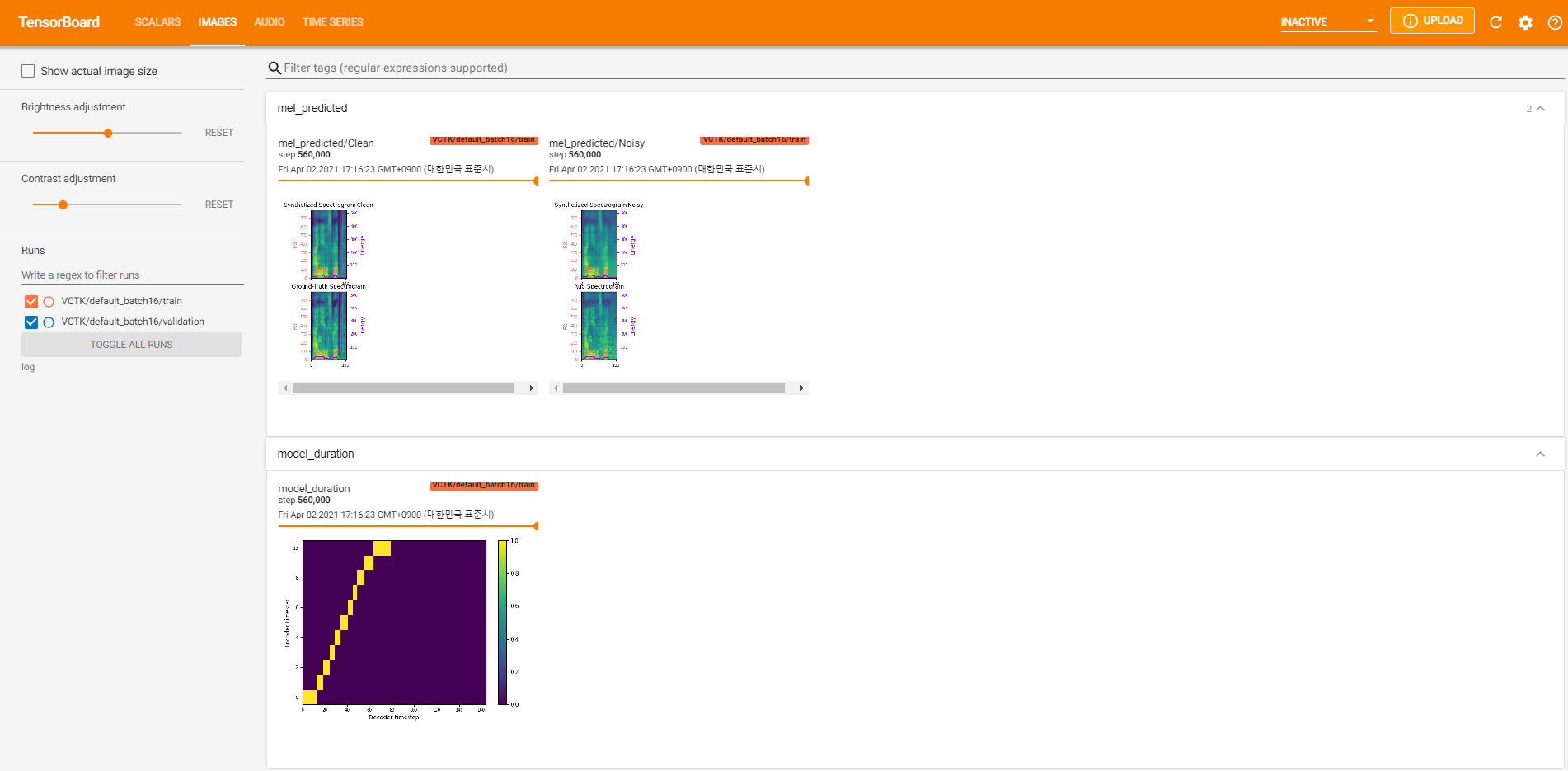
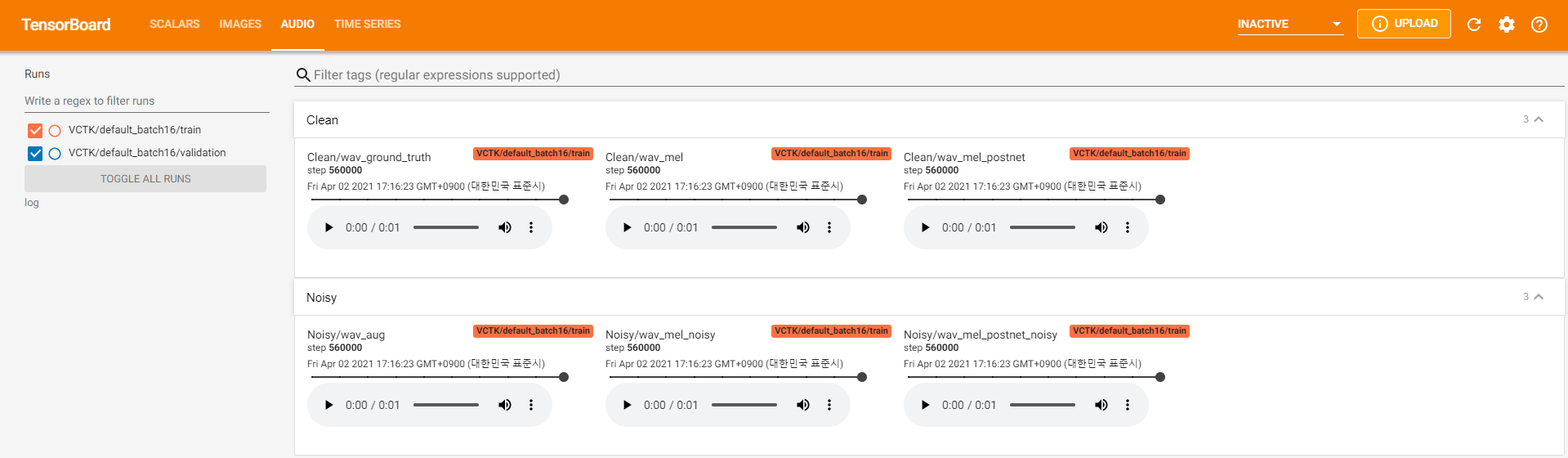
청정 데이터와 같이 pyworld 통해 추출이 불가능한 소음 데이터가 너무 많았습니다. 이를 해결하기 위해 pysptk 적용하여 시끄러운 데이터의 기본 주파수에 대한 Log F0을 추출했습니다. --noisy_input 옵션은 합성 중에이 프로세스를 자동화합니다.
preprocess.py 실행하는 동안 MFA 관련 문제가 발생하면 다음 명령으로 MFA를 수동으로 실행하십시오.
# Replace $data_dir and $PREPROCESSED_PATH with ./VCTK-Corpus-92/wav48_silence_trimmed and ./preprocessed/VCTK/TextGrid, for example
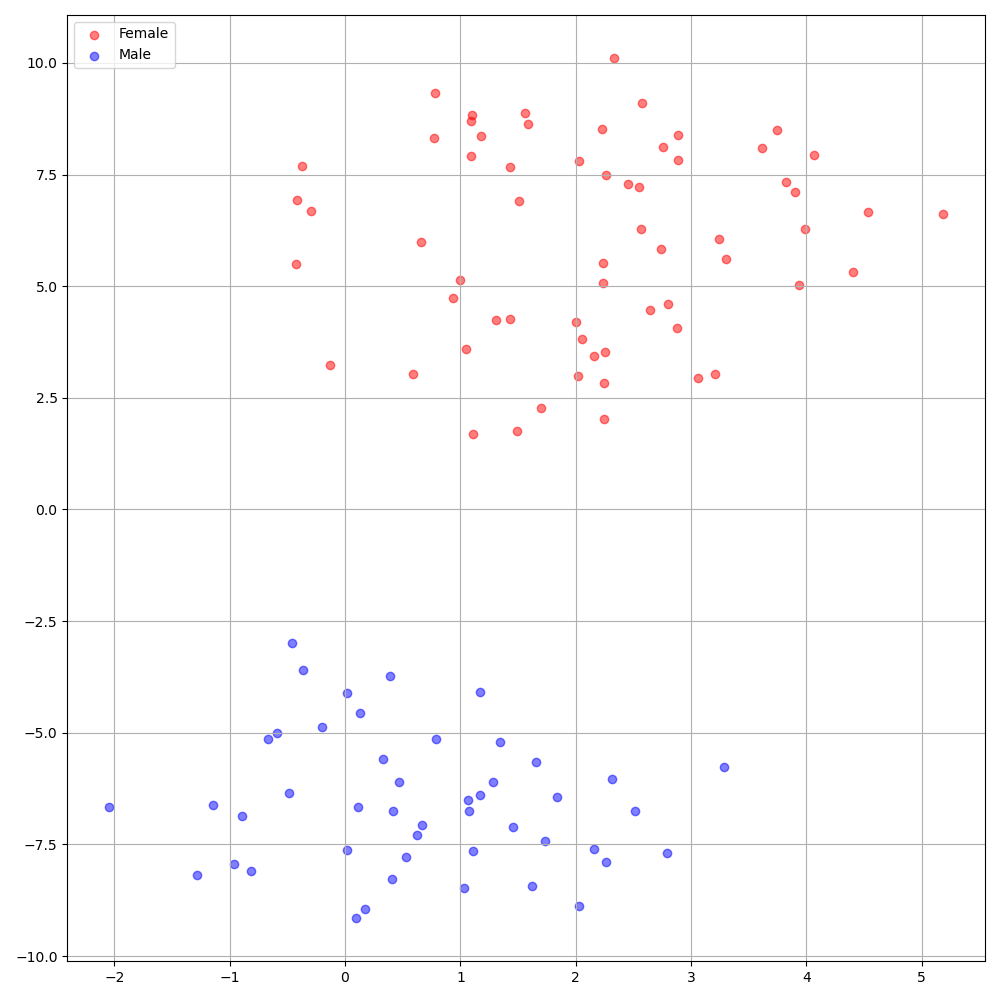
./montreal-forced-aligner/bin/mfa_align $YOUR_data_dir montreal-forced-aligner/pretrained_models/librispeech-lexicon.txt english $YOUR_PREPROCESSED_PATH -j 8VCTK 데이터 세트의 DeepSpeaker는 스피커간에 명확한 식별을 보여줍니다. 다음 그림은 실험에서 추출 된 스피커 임베딩의 T-SNE 플롯을 보여줍니다.
현재, preprocess.py 데이터 세트를 두 개의 서브 세트, 즉 트레인 및 검증 세트로 나눕니다. 테스트 세트와 같은 다른 세트가 필요한 경우 hp.preprocessed_path/ 에서 텍스트 파일 ( train.txt 또는 val.txt )을 수정하는 것입니다.
이 구현을 사용하거나 참조하려면 Repo와 함께 논문을 인용하십시오.
@inproceedings{lee21h_interspeech,
author={Keon Lee and Kyumin Park and Daeyoung Kim},
title={{STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech}},
year=2021,
booktitle={Proc. Interspeech 2021},
pages={4643--4647},
doi={10.21437/Interspeech.2021-838}
}

