STYLER
v1.0.0
В нашей статье мы предлагаем Styler, неавторегрессивную структуру TTS с моделированием фактора стиля, которая одновременно достигает быстрого, надежности, экспрессивности и управляемости.
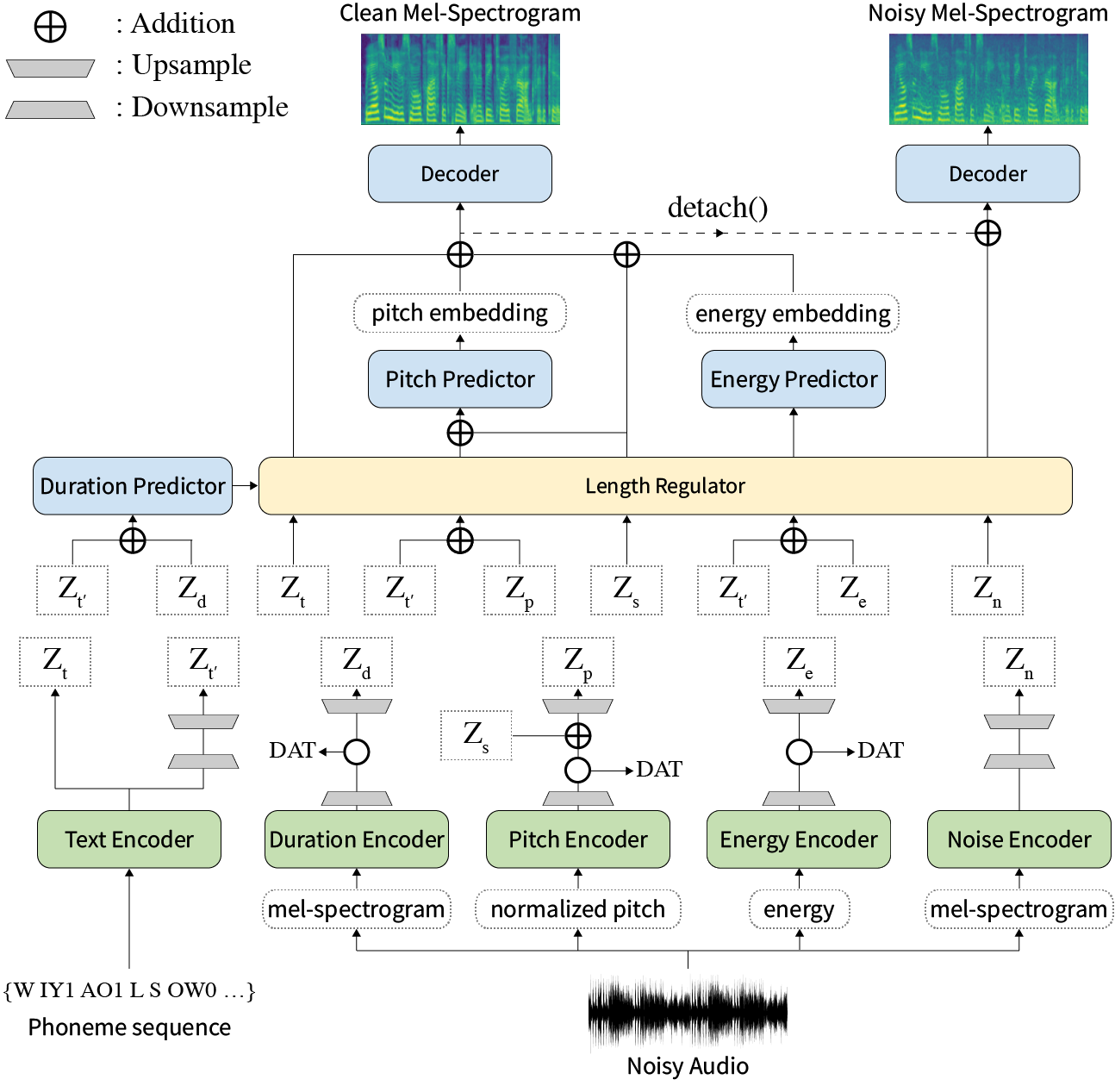
Аннотация: Предыдущие работы по нейронному тексту в речь (TTS) были рассмотрены с ограниченной скоростью в обучении и времени вывода, устойчивости к трудным условиям синтеза, выразительности и управляемости. Хотя несколько подходов разрешают некоторые ограничения, не было попытки решить все слабости одновременно. В этой статье мы предлагаем Styler, выразительную и контролируемую структуру TTS с высокоскоростным и надежным синтезом. Наш новый метод выравнивания аудиозвукового текста под названием Mel Calibrator и исключение авторегрессии декодирования обеспечивают быстрое обучение и вывод и надежный синтез на невидимых данных. Кроме того, моделирование фактора стиля, оснащенного подразделением под наблюдением, расширяет управляемость в процессе синтеза, что приводит к выразительным TTS. Кроме того, новый трубопровод моделирования шума с использованием домена состязательного обучения и остаточного декодирования дает возможность переносу в стиле шума, разлагая шум без какой-либо дополнительной метки. Различные эксперименты демонстрируют, что стилер более эффективен по скорости и надежности, чем выразительные TTS с ауторегрессивным декодированием и более выразительным и контролируемым, чем неавторегрессивные TTS в стиле чтения. Образцы синтеза и результаты эксперимента предоставляются через нашу демо -страницу, а код доступен публично.
Вы можете скачать предварительные модели.
Пожалуйста, установите зависимости от Python, приведенные в requirements.txt .
pip3 install -r requirements.txtdata/resample.sh для детализации.hp.data_dir в hparams.py .hp.noise_dir в hparams.py .hifigan/generator_universal.pth.tar.zip в том же каталоге. Во -первых, загрузите Rescnn Softmax+триплетная модель DeepSpeaker от Philipperemy для встраивания динамика, как описано в нашей статье, и найдите его в hp.speaker_embedder_dir .
Во -вторых, загрузите пакет Montreal Arvence Aligner (MFA) и файл лексикона, предварительно расположенного (Librispeech), через следующие команды. MFA используется для получения выравнивания между высказываниями и последовательностями фонем в качестве Fastspeech2.
wget https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner/releases/download/v1.1.0-beta.2/montreal-forced-aligner_linux.tar.gz
tar -zxvf montreal-forced-aligner_linux.tar.gz
wget http://www.openslr.org/resources/11/librispeech-lexicon.txt -O montreal-forced-aligner/pretrained_models/librispeech-lexicon.txt Затем обработайте все необходимые функции. Вы получите файл stat.txt в своем hp.preprocessed_path/ . Вы должны изменить параметры F0 и энергии в hparams.py в соответствии с содержанием stat.txt .
python3 preprocess.pyНаконец, получите шумные данные отдельно от чистых данных, смешивая каждое высказывание с случайно выбранным кусочком фонового шума от WHAM! набор данных.
python3 preprocess_noisy.pyТеперь у вас есть все предпосылки! Обучить модель, используя следующую команду:
python3 train.py sentences sentences.py data/ Обратите внимание, что sentences могут содержать более одного текста.
# In 'data/sentences.py',
sentences = [
" Nothing is lost, everything is recycled. "
]Справочная подготовка звука имеет аналогичный процесс с подготовкой обучающих данных. Там может быть два вида ссылок: чистый и шумный.
Во -первых, поместите чистые аудиосистемы с соответствующими текстами в один каталог и измените hp.ref_audio_dir в hparams.py и обработайте все необходимые функции. Обратитесь к разделу Clean Data Train Preparation .
python3 preprocess_refs.pyЗатем получите шумные ссылки.
python3 preprocess_noisy.py --refs Следующая команда синтезирует все комбинации текстов в data/sentences.py hp.ref_audio_dir
python3 synthesize.py --ckpt CHECKPOINT_PATH Или вы можете указать единый эталонный аудио в hp.ref_audio_dir следующим образом.
python3 synthesize.py --ckpt CHECKPOINT_PATH --ref_name AUDIO_FILENAMEКроме того, есть несколько полезных вариантов.
--speaker_id указат динамик. Указанное встраивание динамика должно быть в hp.preprocessed_path/spker_embed . Значение по умолчанию None является, и встраивание динамика рассчитывается во время выполнения на каждом входном аудио.
--inspection даст вам дополнительные выходы, которые показывают эффекты каждого энкодера стилера. Образцы такие же, как раздел Style Factor Modeling на нашей демо -странице.
--cont будет генерировать образцы в качестве раздела Style Factor Control на нашей демо-странице.
python3 synthesize.py --ckpt CHECKPOINT_PATH --cont --r1 AUDIO_FILENAME_1 --r2 AUDIO_FILENAME_1 Обратите внимание, что опция --cont работает только над предварительно предварительно связанными данными. Подробно, имя Audios должно иметь тот же формат, что и набор данных VCTK (например, p323_229), а предварительные данные должны существовать в hp.preprocessed_path .
Руггеры Tensorboard хранятся в каталоге log . Использовать
tensorboard --logdir logПодавать в тендентор на вашем местном хосте. Вот несколько видов ведения журнала на модель обучения на VCTK для 560 тыс.
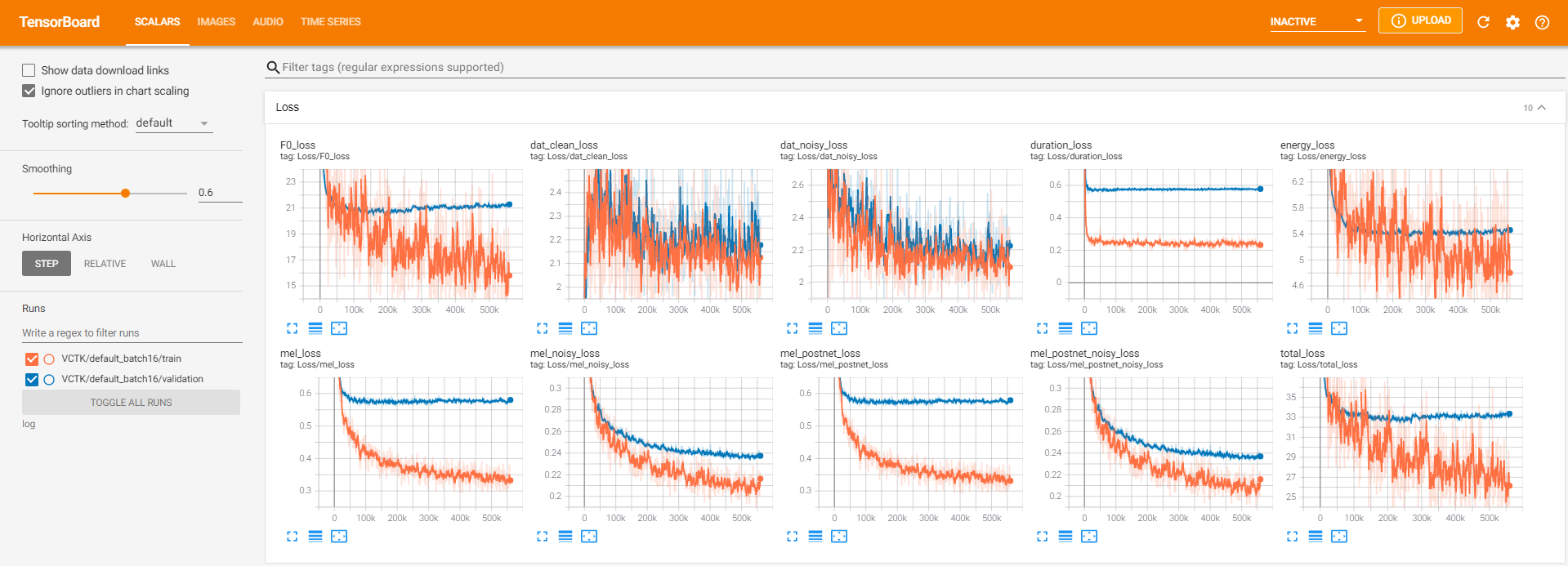
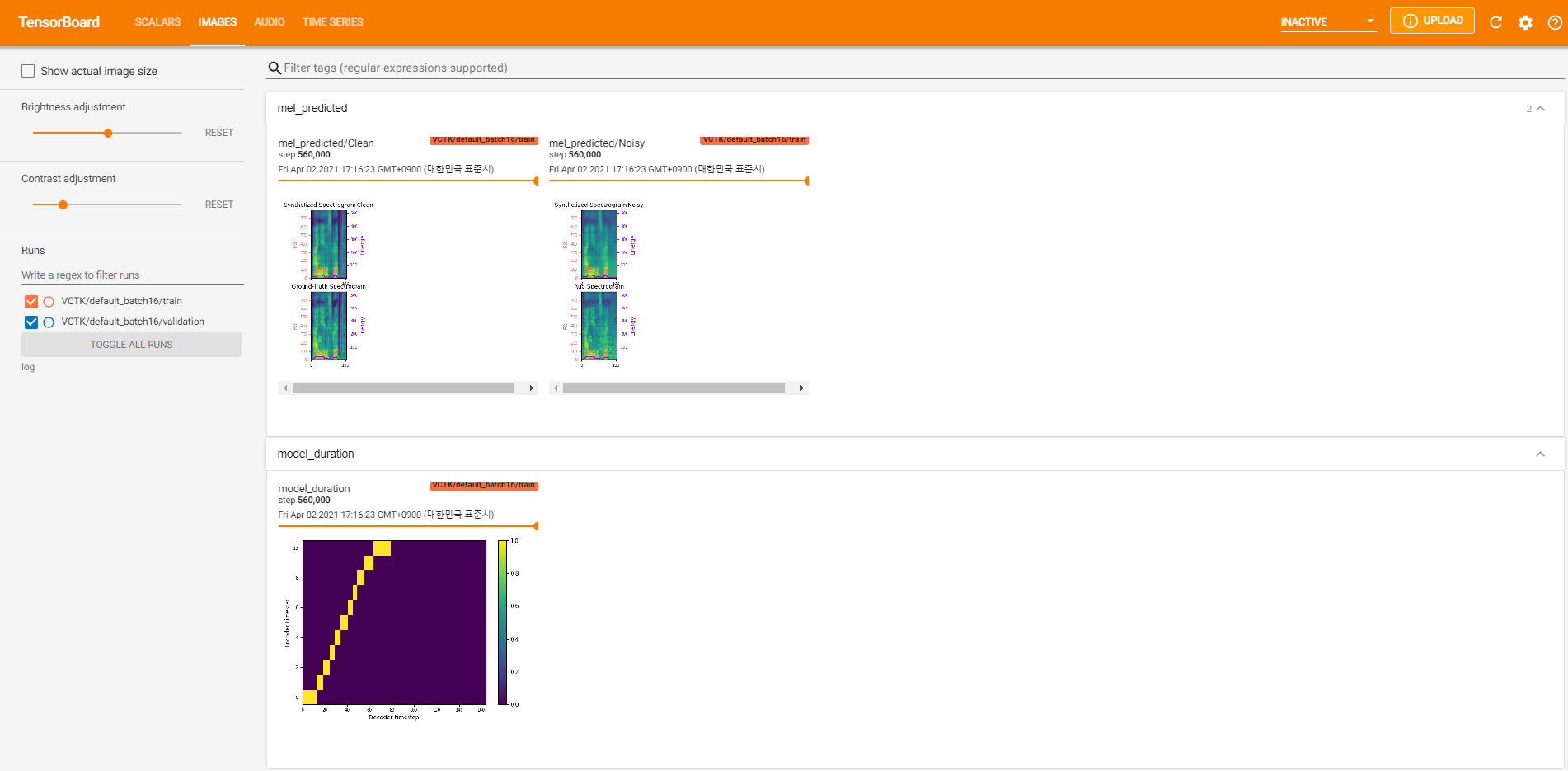
Было слишком много данных о шуме, где извлечение было невозможным через pyworld , как в чистых данных. Чтобы разрешить это, pysptk был применен для извлечения log F0 для фундаментальной частоты шумных данных. Опция --noisy_input будет автоматизировать этот процесс во время синтеза.
Если проблемы, связанные с MFA, возникают во время работы preprocess.py , попробуйте вручную запустить MFA по следующей команде.
# Replace $data_dir and $PREPROCESSED_PATH with ./VCTK-Corpus-92/wav48_silence_trimmed and ./preprocessed/VCTK/TextGrid, for example
./montreal-forced-aligner/bin/mfa_align $YOUR_data_dir montreal-forced-aligner/pretrained_models/librispeech-lexicon.txt english $YOUR_PREPROCESSED_PATH -j 8DeepSpeaker на наборе данных VCTK показывает четкую идентификацию среди ораторов. На следующем рисунке показан график T-SNE извлеченного динамика, внедряющего в наши эксперименты.
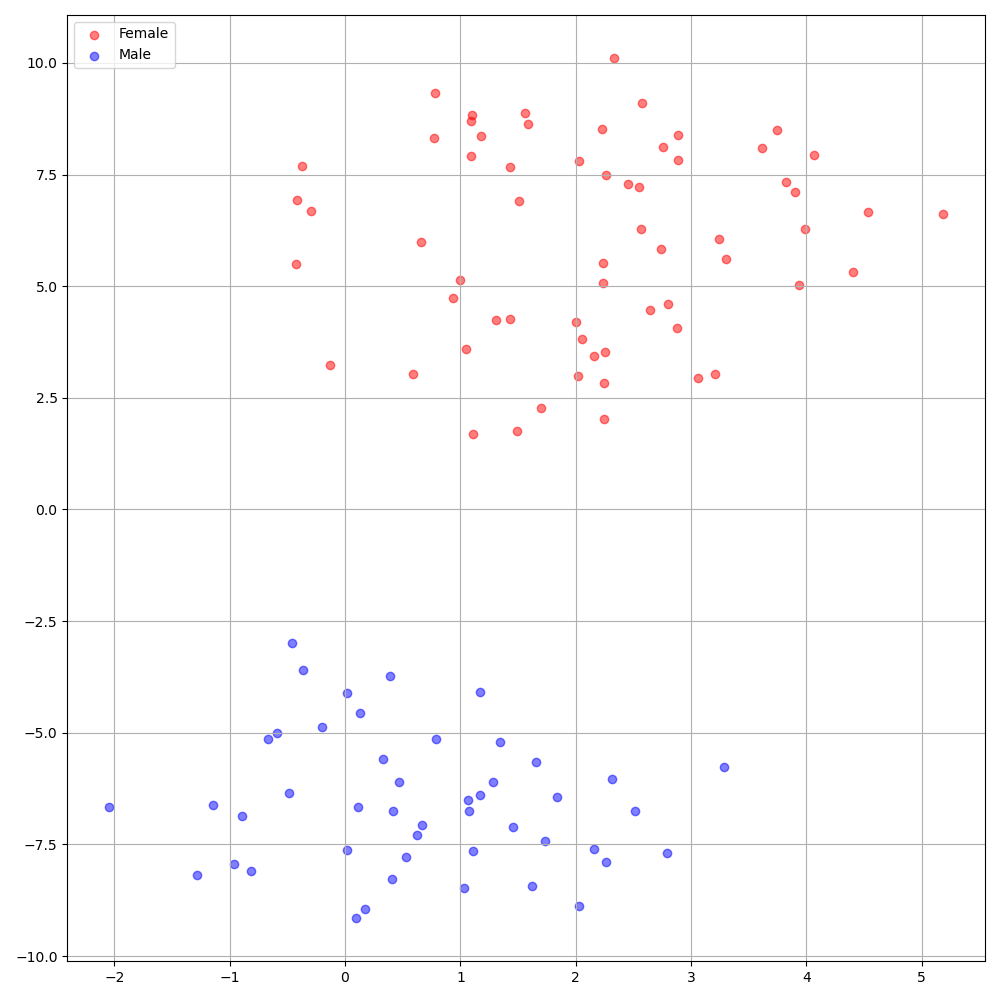
В настоящее время preprocess.py делит набор данных на два подмножества: набор поездов и валидации. Если вам нужны другие наборы, такие как набор тестирования, единственное, что нужно сделать, это изменить текстовые файлы ( train.txt или val.txt ) в hp.preprocessed_path/ .
Если вы хотите использовать или ссылаться на эту реализацию, пожалуйста, сопоставьте нашу статью с помощью репо.
@inproceedings{lee21h_interspeech,
author={Keon Lee and Kyumin Park and Daeyoung Kim},
title={{STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech}},
year=2021,
booktitle={Proc. Interspeech 2021},
pages={4643--4647},
doi={10.21437/Interspeech.2021-838}
}

