dctts pytorch
1.0.0
Pytorch實施爸爸的實施有效地基於深層卷積網絡,具有指導性的注意力。
感謝Kyubyong/DC_TTS,這有助於我克服一些困難。
我已經調整了超級參數,並使用LJ語音數據集訓練了模型。超級參數可能不是最好的參數,並且與原始紙張中使用的參數略有不同。
使用LJ語音數據集訓練模型:
pkg/hyper.py設置目錄 python3 main.py --action preprocess
pkg/hyper.py的text2mel python3 main.py --action train --module Text2Mel
python3 main.py --action train --module SuperRes
一些合成樣品包含在目錄synthesis中。根據句子列出了sentences.txt 。合成時,合成時將加載text2mel和超級訓練的預訓練模型(在logdir/text2mel/pkg/trained.pkg和logdir/superres/pkg/trained.pkg的訓練階段的自動保存)時加載。
您可以在sentences.txt中列出的樣本。
python3 main.py --action synthesis
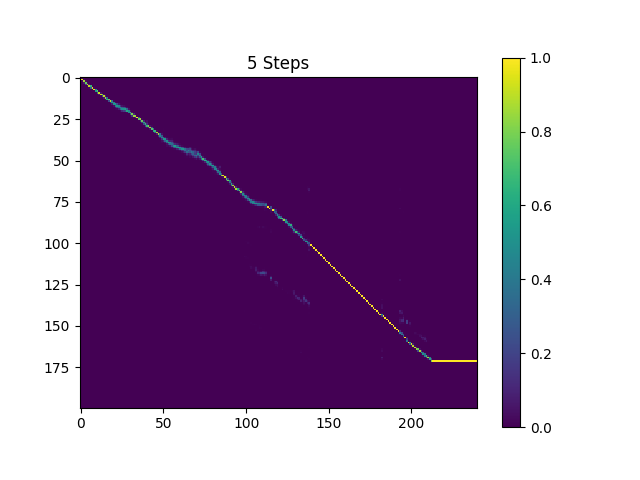
目錄synthesis中的樣品用410k批次訓練的Text2Mel和190K批次訓練的超級批次採樣。
當前的結果不是很令人滿意,通常會跳過一些元音。希望有人可以找到更好的超級參數並訓練更好的模型。請告訴我,您是否能夠獲得出色的模型。
您可以從我的Dropbox下載當前的預訓練模型。
TensorFlow實現:Kyubyong/DC_TTS
如果您有任何疑問或建議,請給我發電子郵件或打開問題。


