dctts pytorch
1.0.0
La mise en œuvre pytorch du système de texte à dispection Papar efficacement formable basé sur des réseaux convolutionnels profonds avec une attention guidée.
Merci pour Kyubyong / DC_TTS, ce qui m'a beaucoup aidé à surmonter certaines difficultés.
J'ai réglé des paramètres hyper et formé un modèle avec l'ensemble de données de la parole LJ. Les paramètres hyper peuvent ne pas être les meilleurs et sont légèrement différents avec ceux utilisés dans le papier d'origine.
Pour former un modèle vous-même avec l'ensemble de données de discours LJ:
pkg/hyper.py python3 main.py --action preprocess
pkg/hyper.py python3 main.py --action train --module Text2Mel
python3 main.py --action train --module SuperRes
Certains échantillons synthétisés sont contenus dans synthesis du répertoire. Les phrases selon les phrases sont répertoriées en sentences.txt . Le modèle pré-formé pour Text2Mel et Superres (Auto-Saved sur logdir/text2mel/pkg/trained.pkg et logdir/superres/pkg/trained.pkg en phase de formation) sera chargé lors de la synthèse.
Vous pouvez synthèse des échantillons répertoriés dans sentences.txt avec
python3 main.py --action synthesis
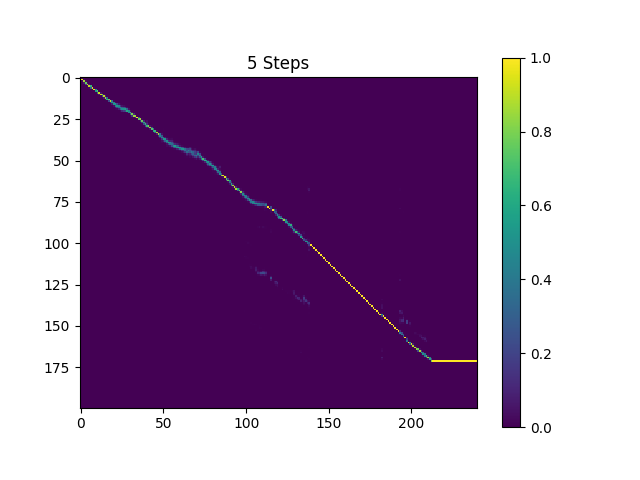
Les échantillons de synthesis des répertoires sont échantillonnés avec des lots de 410 000 lots Text2Mel et 190k de superres formés.
Le résultat actuel n'est pas très satisfaisant, spécialement, certaines voyelles sont ignorées. J'espère que quelqu'un pourra trouver de meilleurs paramètres hyper et former de meilleurs modèles. Veuillez me dire si vous avez pu obtenir un excellent modèle.
Vous pouvez télécharger le modèle pré-formé actuel à partir de ma Dropbox.
Implémentation de TensorFlow: Kyubyong / dc_tts
Veuillez m'envoyer un e-mail ou ouvrir un problème, si vous avez une question ou une suggestion.


