dctts pytorch
1.0.0
การใช้งาน Pytorch ของ Papar อย่างมีประสิทธิภาพระบบ text-to-speech ที่ได้รับการฝึกอบรมอย่างมีประสิทธิภาพโดยใช้เครือข่ายที่ลึกล้ำด้วยความสนใจ
ขอบคุณสำหรับ Kyubyong/DC_TTS ซึ่งช่วยฉันได้มากในการเอาชนะปัญหาบางอย่าง
ฉันได้ปรับพารามิเตอร์ไฮเปอร์และฝึกอบรมแบบจำลองด้วยชุดข้อมูล LJ Speech พารามิเตอร์ไฮเปอร์อาจไม่ดีที่สุดและแตกต่างจากที่ใช้ในกระดาษต้นฉบับเล็กน้อย
เพื่อฝึกอบรมแบบจำลองด้วยชุดข้อมูล LJ Speech:
pkg/hyper.py python3 main.py --action preprocess
pkg/hyper.py python3 main.py --action train --module Text2Mel
python3 main.py --action train --module SuperRes
ตัวอย่างสังเคราะห์บางตัวอย่างมีอยู่ใน synthesis ไดเรกทอรี ประโยคตามแสดงไว้ใน sentences.txt โมเดลที่ผ่านการฝึกอบรมล่วงหน้าสำหรับ Text2Mel และ Superres (ประหยัดอัตโนมัติที่ logdir/text2mel/pkg/trained.pkg และ logdir/superres/pkg/trained.pkg ในขั้นตอนการฝึกอบรม) จะโหลดเมื่อทำการสังเคราะห์
คุณสามารถตัวอย่างการสังเคราะห์ที่ระบุไว้ใน sentences.txt ด้วย
python3 main.py --action synthesis
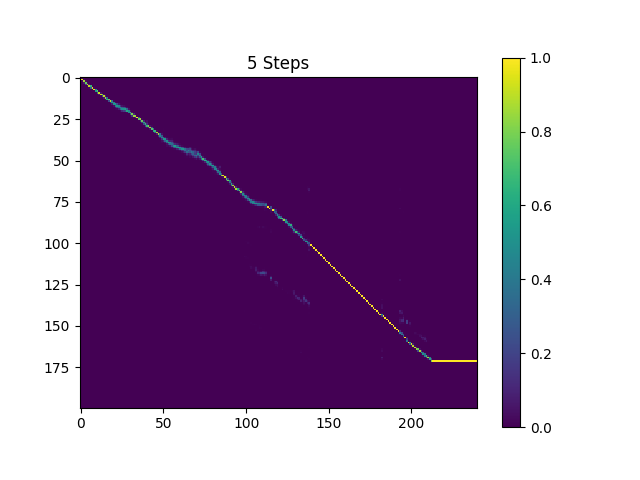
ตัวอย่างใน synthesis ไดเรกทอรีจะถูกสุ่มตัวอย่างด้วย 410K แบทช์ text2mel ที่ผ่านการฝึกอบรม 2 และ 190k แบทช์ที่ผ่านการฝึกอบรมมาแล้ว
ผลลัพธ์ในปัจจุบันไม่น่าพึงพอใจมากสระบางตัวจะถูกข้าม หวังว่าใครบางคนสามารถหาพารามิเตอร์ไฮเปอร์ที่ดีกว่าและฝึกอบรมโมเดลที่ดีกว่า โปรดบอกฉันว่าคุณสามารถเป็นนางแบบที่ยอดเยี่ยมได้หรือไม่
คุณสามารถดาวน์โหลดโมเดลที่ผ่านการฝึกอบรมมาก่อนจาก Dropbox ของฉัน
การใช้งาน Tensorflow: Kyubyong/DC_TTS
โปรดส่งอีเมลถึงฉันหรือเปิดปัญหาหากคุณมีคำถามหรือข้อเสนอแนะใด ๆ


