dctts pytorch
1.0.0
A implementação do Pytorch do sistema de texto em fala com eficientemente treinável com base em redes convolucionais profundas com atenção guiada.
Obrigado pelo Kyubyong/dc_tts, o que me ajudou muito a superar algumas dificuldades.
Eu sintonizei parâmetros hiper e treinei um modelo com o conjunto de dados de fala LJ. Os parâmetros hiper podem não ser os melhores e são um pouco diferentes dos usados no papel original.
Para treinar um modelo sozinho com o conjunto de dados de discurso de LJ:
pkg/hyper.py python3 main.py --action preprocess
pkg/hyper.py python3 main.py --action train --module Text2Mel
python3 main.py --action train --module SuperRes
Algumas amostras sintetizadas estão contidas na synthesis de diretório. As frases conforme estão listadas em sentences.txt . O modelo pré-treinado para text2mel e superres (economizado automaticamente em logdir/text2mel/pkg/trained.pkg e logdir/superres/pkg/trained.pkg na fase de treinamento) será carregado ao sintetizar.
Você pode síntese amostras listadas em sentences.txt com
python3 main.py --action synthesis
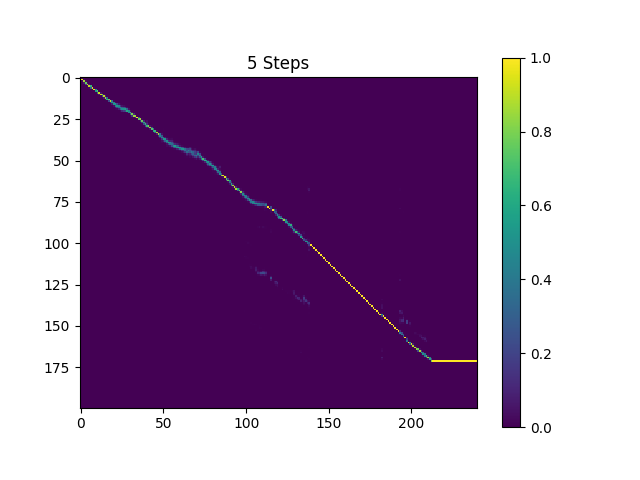
As amostras na synthesis de diretório são amostradas com 410k lotes de texto treinado e lotes de 190K treinaram Superres.
O resultado atual não é muito gratificante, especificamente, algumas vogais são ignoradas. Espero que alguém possa encontrar melhores parâmetros hiper e treinar melhores modelos. Por favor, diga -me se você conseguiu um ótimo modelo.
Você pode baixar o modelo pré-treinado atual do meu Dropbox.
Implementação do TensorFlow: Kyubyong/dc_tts
Envie -me um email ou abra um problema, se você tiver alguma dúvida ou sugestão.


