dctts pytorch
1.0.0
Die Pytorch-Implementierung von Papar trainierbarem Text-zu-Sprach-System basierend auf tiefen Faltungsnetzen mit geführter Aufmerksamkeit.
Danke für Kyubyong/DC_TTS, was mir sehr geholfen hat, einige Schwierigkeiten zu überwinden.
Ich habe Hyperparameter abgestimmt und ein Modell mit dem LJ -Sprachdatensatz trainiert. Die Hyperparameter sind möglicherweise nicht die besten und unterscheiden sich bei den in Originalpapier verwendeten.
Um ein Modell selbst mit dem LJ -Sprachdatensatz zu trainieren:
pkg/hyper.py python3 main.py --action preprocess
pkg/hyper.py trainiert wird python3 main.py --action train --module Text2Mel
python3 main.py --action train --module SuperRes
Einige synthetisierte Proben sind in der synthesis enthalten. Die nach Sätzen in sentences.txt aufgeführten Sätzen. Das vorgebildete Modell für Text2Mel und Superres (automatisch unter logdir/text2mel/pkg/trained.pkg und logdir/superres/pkg/trained.pkg in der Trainingsphase) wird beim Synthese geladen.
Sie können Muster synthese sentences.txt
python3 main.py --action synthesis
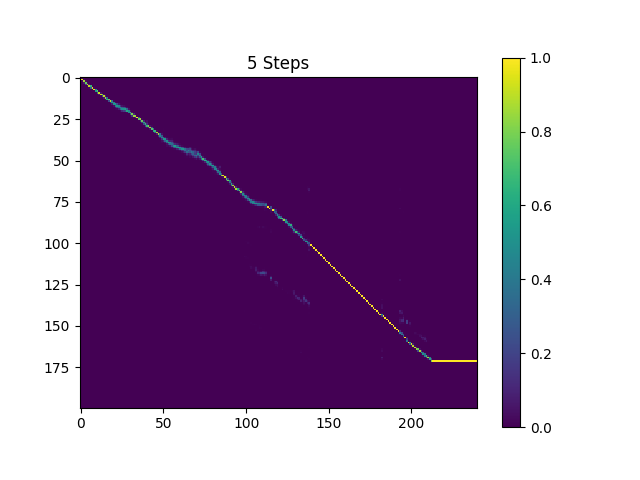
Die Proben in der synthesis sind mit 410K -Chargen ausgebildetem Text2Mel und 190k -Chargen ausgebildeten Superres abgetastet.
Das aktuelle Ergebnis ist nicht sehr zufriedenstellend, insbesondere werden einige Vokale übersprungen. Ich hoffe, jemand kann bessere Hyperparameter finden und bessere Modelle trainieren. Bitte sagen Sie mir, ob Sie ein tolles Modell bekommen konnten.
Sie können das aktuelle vorgebildete Modell aus meinem Dropbox herunterladen.
TensorFlow -Implementierung: Kyubyong/DC_TTS
Bitte senden Sie mir eine E -Mail oder öffnen Sie ein Problem, wenn Sie Fragen oder Vorschläge haben.


