dctts pytorch
1.0.0
Реализация Pytorch эффективно обучаемой системы текста в речь, основанная на глубоких сверточных сетях с вниманием.
Спасибо за kyubyong/dc_tts, что очень помогло мне преодолеть некоторые трудности.
Я настроил гипер -парамеры и обучил модель с набором данных речи LJ. Гипер параметры могут быть не лучшими и немного отличаются от тех, которые используются в оригинальной статье.
Чтобы тренировать модель самостоятельно с набором данных речи LJ:
pkg/hyper.py python3 main.py --action preprocess
pkg/hyper.py python3 main.py --action train --module Text2Mel
python3 main.py --action train --module SuperRes
Некоторые синтезированные образцы содержатся в synthesis каталога. Собственные приговоры перечислены в sentences.txt . Предварительно обученная модель для Text2mel и Superres (автоматическое сочетается с logdir/text2mel/pkg/trained.pkg и logdir/superres/pkg/trained.pkg в тренировочной фазе) будет загружена при синтезе.
Вы можете синтезировать образцы, перечисленные в sentences.txt с
python3 main.py --action synthesis
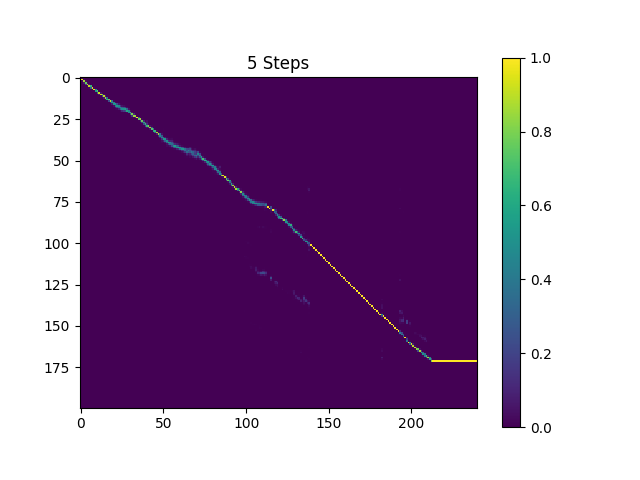
Образцы в synthesis каталога отображаются с 410K -партиями, обученными Text2MEL и 190K, обученными Superres.
Текущий результат не очень приятен, особенно некоторые гласные пропущены. Надеюсь, кто -то сможет найти лучшие гипер -параметры и обучить лучшие модели. Пожалуйста, скажите мне, если вы смогли получить отличную модель.
Вы можете скачать текущую предварительно обученную модель из моего Dropbox.
Реализация TensorFlow: Kyubyong/dc_tts
Пожалуйста, напишите мне или откройте проблему, если у вас есть какие -либо вопросы или предложения.


