dctts pytorch
1.0.0
Papar의 Pytorch 구현은주의를 기울인 깊은 컨볼 루션 네트워크를 기반으로 효율적으로 훈련 가능한 텍스트 음성 연설 시스템을 구현합니다.
Kyubyong/DC_TTS에 감사드립니다. 어려움을 극복하는 데 많은 도움이되었습니다.
하이퍼 매개 변수를 조정하고 LJ Speech 데이터 세트로 모델을 교육했습니다. 하이퍼 매개 변수는 최고가 아니며 원본 용지에 사용 된 것과 약간 다릅니다.
LJ Speech 데이터 세트로 모델을 직접 훈련시키기 위해 :
pkg/hyper.py 로 설정하십시오. python3 main.py --action preprocess
pkg/hyper.py 에서 Text2mel을 교육하도록 장치를 변경할 수 있습니다. python3 main.py --action train --module Text2Mel
python3 main.py --action train --module SuperRes
일부 합성 된 샘플은 디렉토리 synthesis 에 포함되어 있습니다. 이 문장은 sentences.txt 에 나열되어 있습니다. Text2mel 및 Superres에 대한 미리 훈련 된 모델 ( logdir/text2mel/pkg/trained.pkg 및 logdir/superres/pkg/trained.pkg 에서 합성 할 때로드됩니다.
sentences.txt 에 나열된 샘플을 합성 할 수 있습니다
python3 main.py --action synthesis
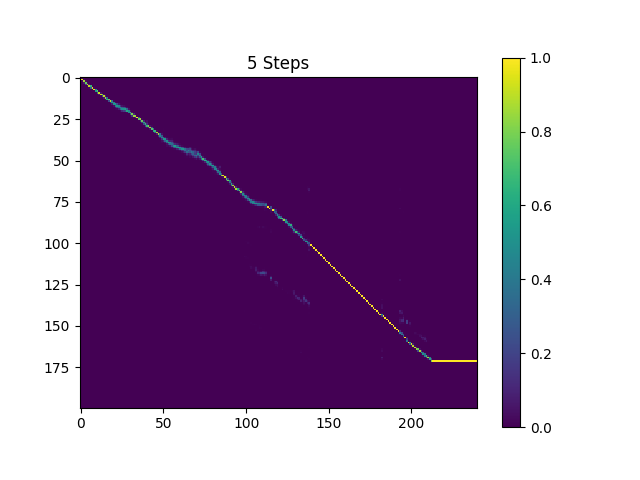
디렉토리 synthesis 의 샘플은 410K 배치 훈련 된 Text2mel 및 190k 배치 훈련 된 슈퍼 레스로 샘플링됩니다.
현재 결과는 그다지 만족스럽지 않으며 구체적으로 일부 모음이 건너 뜁니다. 누군가가 더 나은 하이퍼 매개 변수를 찾고 더 나은 모델을 훈련시킬 수 있기를 바랍니다. 훌륭한 모델을 얻을 수 있는지 알려주세요.
내 Dropbox에서 현재 미리 훈련 된 모델을 다운로드 할 수 있습니다.
텐서 플로 구현 : kyubyong/dc_tts
질문이나 제안이 있으면 저에게 이메일을 보내거나 문제를 열어주십시오.


