dctts pytorch
1.0.0
PaparのPytorchの実装は、誘導された注意を払った深い畳み込みネットワークに基づいて、効率的にトレーニング可能なテキストからスピーチへの実装システムを実装しています。
kyubyong/dc_ttsに感謝します。
ハイパーパラメーターを調整し、LJの音声データセットでモデルをトレーニングしました。ハイパーパラメーターは最良ではなく、元の紙で使用されているものとわずかに異なっています。
LJスピーチデータセットで自分でモデルをトレーニングするには:
pkg/hyper.pyでディレクトリを設定します python3 main.py --action preprocess
pkg/hyper.pyでtext2melをトレーニングできます python3 main.py --action train --module Text2Mel
python3 main.py --action train --module SuperRes
一部の合成サンプルは、ディレクトリsynthesisに含まれています。文章は、 sentences.txtにリストされています。 Text2MelとSuperresの事前に訓練されたモデル( logdir/text2mel/pkg/trained.pkgおよびlogdir/superres/pkg/trained.pkg )は、合成時にロードされます。
sentences.txtにリストされているサンプルを合成できます
python3 main.py --action synthesis
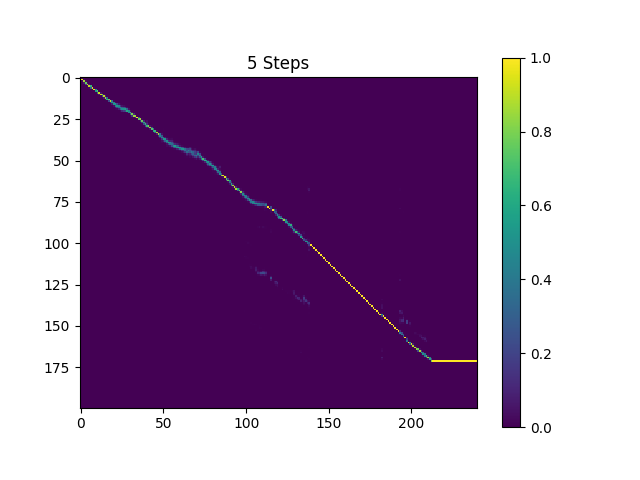
ディレクトリsynthesisのサンプルは、410Kバッチの訓練されたText2Melと190Kバッチトレーニングされたスーパーレスでサンプリングされます。
現在の結果はあまり満足ではなく、具体的には、いくつかの母音がスキップされています。誰かがより良いハイパーパラメーターを見つけ、より良いモデルを訓練できることを願っています。素晴らしいモデルを手に入れることができたら教えてください。
Dropboxから現在の事前訓練モデルをダウンロードできます。
Tensorflowの実装:Kyubyong/DC_TTS
質問や提案がある場合は、私にメールするか、問題を開いてください。


