dctts pytorch
1.0.0
La implementación de Pytorch del sistema de texto a voz de Eficiente y Tapa de PapAR basada en redes convolucionales profundas con atención guiada.
Gracias por Kyubyong/DC_TTS, lo que me ayudó mucho a superar algunas dificultades.
He ajustado los parámetros hiper y entrenado un modelo con el conjunto de datos de discurso LJ. Los hiper parámetros pueden no ser los mejores y son ligeramente diferentes con los utilizados en el papel original.
Para entrenar un modelo usted mismo con el conjunto de datos de discurso LJ:
pkg/hyper.py python3 main.py --action preprocess
pkg/hyper.py python3 main.py --action train --module Text2Mel
python3 main.py --action train --module SuperRes
Algunas muestras sintetizadas están contenidas en synthesis de directorio. Las oraciones según se enumeran en sentences.txt . El modelo previamente capacitado para Text2Mel y SuperRes (ahorro automático en logdir/text2mel/pkg/trained.pkg y logdir/superres/pkg/trained.pkg en fase de entrenamiento) se cargará al sintetizar.
Puede síntesis de muestras enumeradas en sentences.txt con
python3 main.py --action synthesis
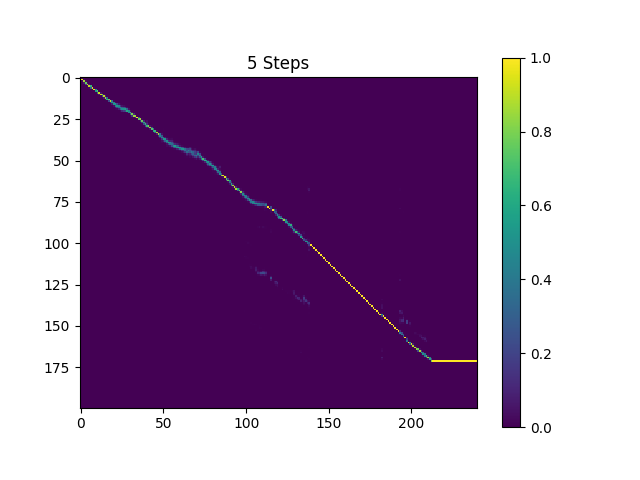
Las muestras en synthesis de directorio se muestrean con 410k lotes de text2mel y 190k Superres entrenados.
El resultado actual no es muy satisfactorio, específicamente, se omiten algunas vocales. Espero que alguien pueda encontrar mejores parámetros hiper y entrenar mejores modelos. Por favor, dígame si pudo obtener un gran modelo.
Puede descargar el modelo pre-entrenado actual de mi Dropbox.
Implementación de TensorFlow: Kyubyong/DC_TTS
Envíeme un correo electrónico o abra un problema, si tiene alguna pregunta o sugerencia.


