dctts pytorch
1.0.0
تنفيذ Pytorch لنظام النصوص إلى الكلام القابل للتدريب بكفاءة استنادًا إلى شبكات تلافيفية عميقة مع اهتمام موجه.
شكرًا على Kyubyong/DC_TTS ، مما ساعدني كثيرًا للتغلب على بعض الصعوبات.
لقد قمت بضبط المعلمات المفرطة ودربت نموذجًا مع مجموعة بيانات الكلام LJ. قد لا تكون المعلمات المفرطة هي الأفضل وتختلف قليلاً مع تلك المستخدمة في الورق الأصلي.
لتدريب نموذج نفسك مع مجموعة بيانات الكلام LJ:
pkg/hyper.py python3 main.py --action preprocess
pkg/hyper.py python3 main.py --action train --module Text2Mel
python3 main.py --action train --module SuperRes
وترد بعض العينات المتراكمة في synthesis الدليل. يتم إدراج الجمل حسب sentences.txt . سيتم تحميل النموذج الذي تم تدريبه مسبقًا لـ Text2mel و Superres (الذي يتم إنشاؤه تلقائيًا في logdir/text2mel/pkg/trained.pkg و logdir/superres/pkg/trained.pkg في مرحلة التدريب) عند التوليف.
يمكنك توليف عينات مدرجة في sentences.txt
python3 main.py --action synthesis
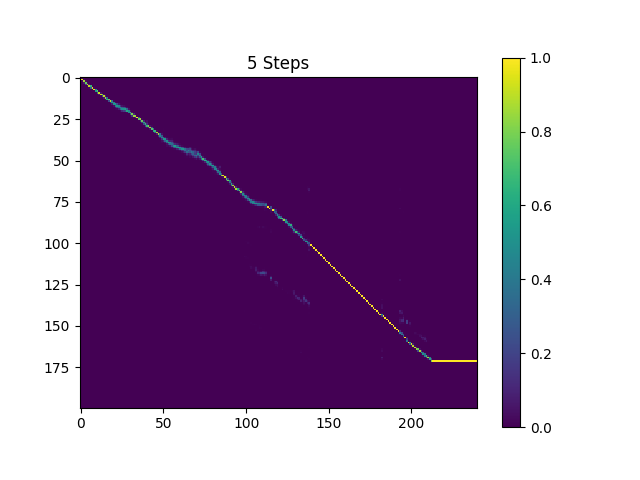
يتم أخذ عينات من العينات في synthesis الدليل مع 410K دفعات مدربة Text2mel و 190k دفعة تدريبية.
النتيجة الحالية ليست مرضية للغاية ، على وجه الخصوص ، يتم تخطي بعض حروف العلة. آمل أن يتمكن شخص ما من العثور على معلمات مفرطة أفضل وتدريب نماذج أفضل. من فضلك قل لي إذا كنت قادرا على الحصول على نموذج رائع.
يمكنك تنزيل النموذج الحالي المدربين مسبقًا من Dropbox.
تنفيذ TensorFlow: Kyubyong/DC_TTS
يرجى مراسلتي عبر البريد الإلكتروني أو فتح مشكلة ، إذا كان لديك أي سؤال أو اقتراح.


