dctts pytorch
1.0.0
Implementasi pytorch dari sistem teks-ke-speech yang dapat dilatih secara efisien berdasarkan jaringan konvolusional yang mendalam dengan perhatian terpandu.
Terima kasih untuk Kyubyong/DC_TTS, yang banyak membantu saya mengatasi beberapa kesulitan.
Saya telah menyetel parameter hiper dan melatih model dengan dataset LJ Speech. Parameter hiper mungkin bukan yang terbaik dan sedikit berbeda dengan yang digunakan dalam kertas asli.
Untuk melatih model diri Anda dengan dataset LJ Speech:
pkg/hyper.py python3 main.py --action preprocess
pkg/hyper.py python3 main.py --action train --module Text2Mel
python3 main.py --action train --module SuperRes
Beberapa sampel yang disintesis terkandung dalam synthesis direktori. Kalimat yang sesuai tercantum dalam sentences.txt . Model pra-terlatih untuk Text2Mel dan SuperRes (Auto-Daved di logdir/text2mel/pkg/trained.pkg dan logdir/superres/pkg/trained.pkg dalam fase pelatihan) akan dimuat saat sintesis.
Anda dapat sintesis sampel yang tercantum dalam sentences.txt dengan
python3 main.py --action synthesis
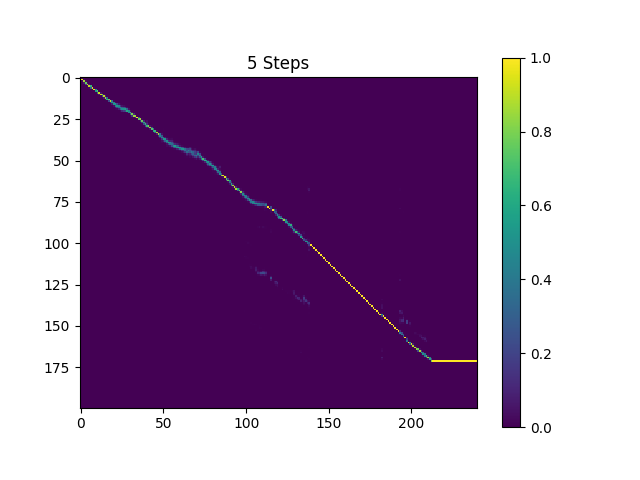
Sampel dalam synthesis direktori diambil sampelnya dengan 410k batch yang terlatih Text2Mel dan 190K batch superres terlatih.
Hasil saat ini tidak terlalu memuaskan, khususnya, beberapa vokal dilewati. Semoga seseorang dapat menemukan parameter hiper yang lebih baik dan melatih model yang lebih baik. Tolong beritahu saya jika Anda bisa mendapatkan model yang hebat.
Anda dapat mengunduh model pra-terlatih saat ini dari Dropbox saya.
Implementasi TensorFlow: Kyubyong/DC_TTS
Silakan email saya atau buka masalah, jika Anda memiliki pertanyaan atau saran.


