ttts
1.0.0
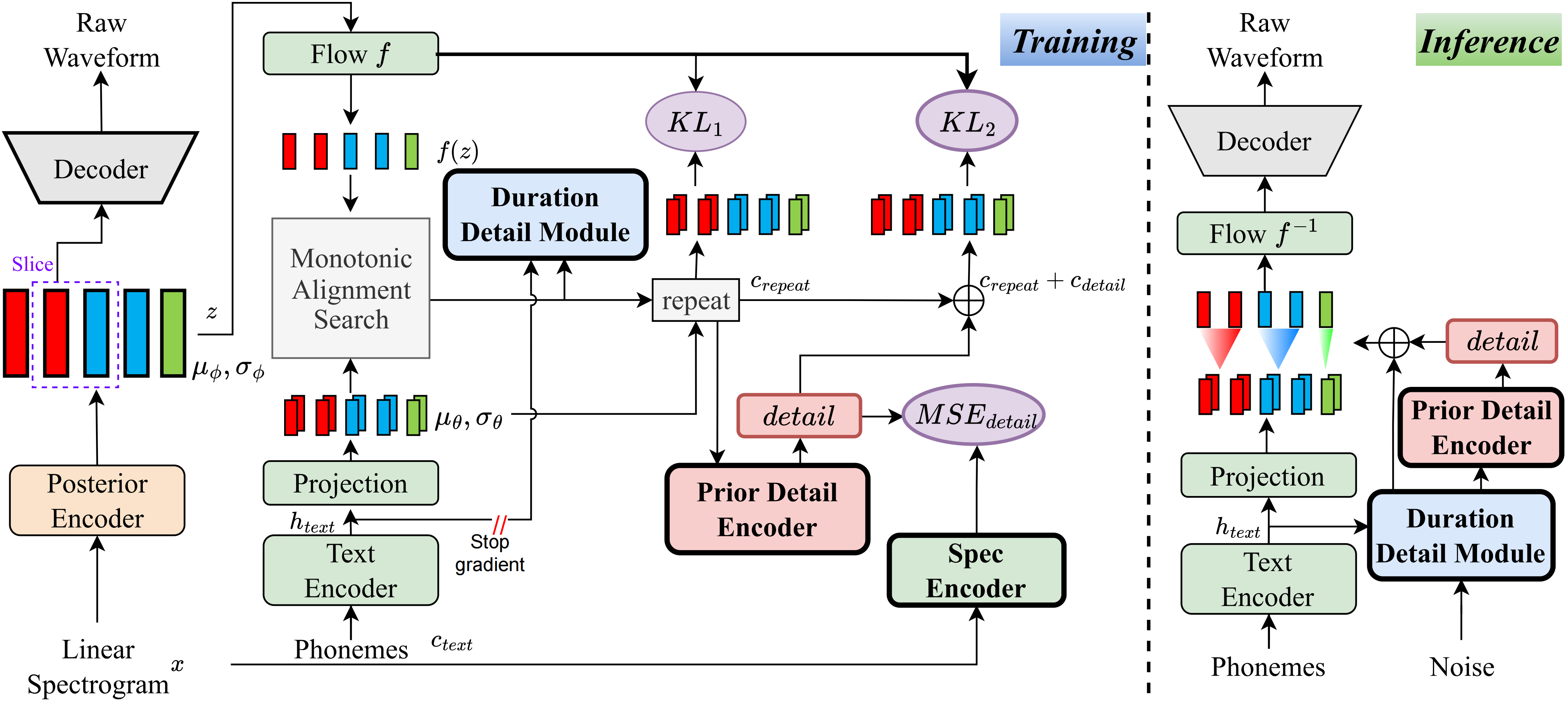
據我所知,該項目的方法是我提出的第一個此類方法。主要思想源於“細節”的建模,因為我對基於VQ(向量量化)方法無法很好地重建音頻的事實感到困擾,並且也沒有辦法對此殘差進行建模。但是,對於傳統的VIT,有一些方法可以創建一些監督信號,例如線性光譜,或者使用可學習的嵌入來學習持續時間。這些觀察結果最終導致了這種方法取得了非常好的結果。
訪問演示頁面
訪問預訓練的模型
pip install -e .
使用ttts/prepare/bpe_all_text_to_one_file.py合併您收集的所有文本。要訓練令牌器,請檢查ttts/gpt/voice_tokenizer以獲取更多信息。
使用1_vad_asr_save_to_jsonl.py和2_romanize_text.py進行預處理數據集。使用以下指令訓練模型。
accelerate launch ttts/vqvae/train_v3.py
現在支持中文,英語,日語,韓語。
您可以使用兩個步驟使用此模型的任何語言。
ttts/gpt/voice_tokenizer獲取字典。對於英語,您可以直接使用文本。但是,對於中文,您需要使用拼音,對於日語,您需要使用romaji,並確保在文本中包含發音信息。
請檢查api.py以獲取推理細節。
使用預估計的模型更改Train_v3.py中的負載路徑,然後訓練它。關於數據集,您應該預處理文本和音頻路徑和拉丁語。您可以參考ttts/prepare/2_romanize_text.py獲取一些信息。


