ttts
1.0.0
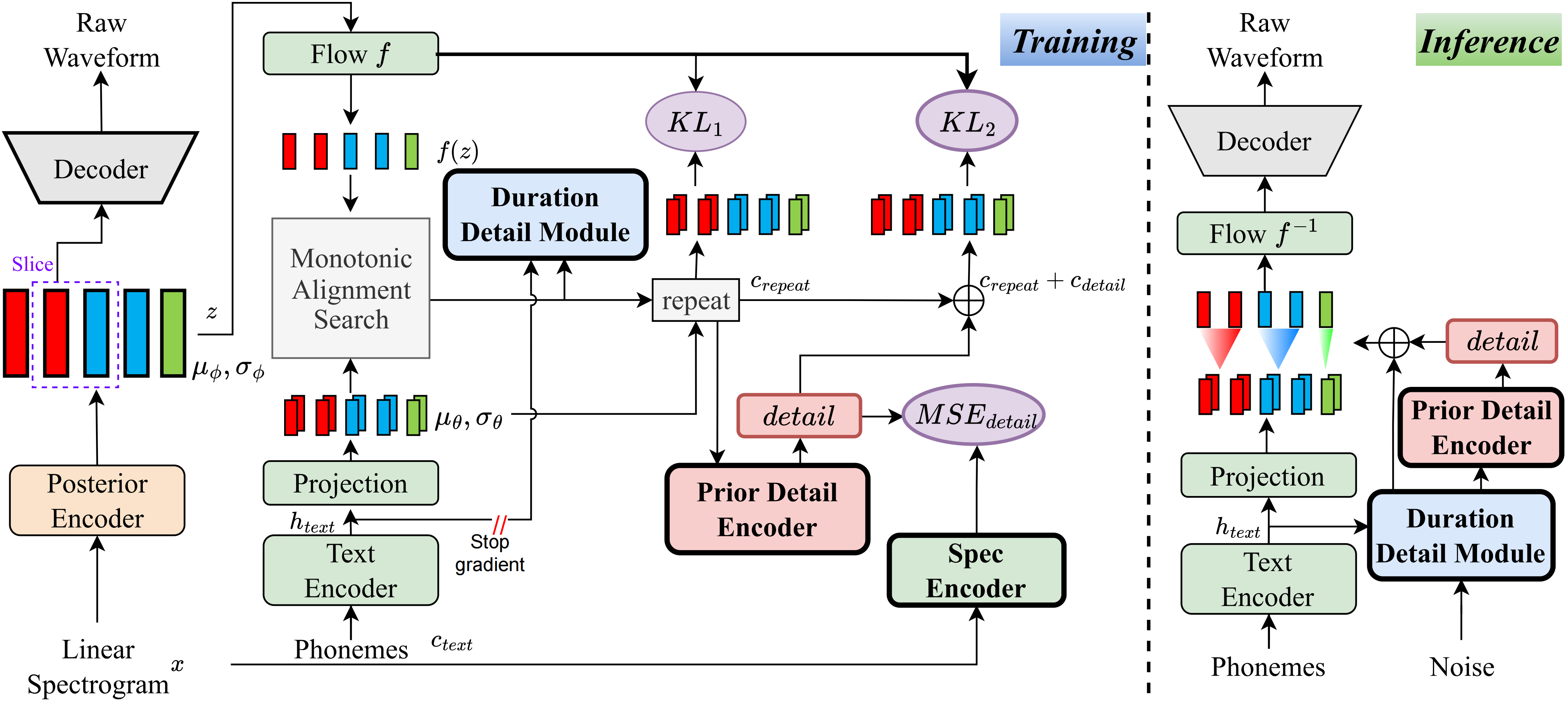
Que yo sepa, el método en este proyecto es el primero de su tipo que he propuesto. La idea principal proviene del modelado de 'detalle', ya que me ha preocupado el hecho de que los métodos basados en VQ (cuantificación vectorial) no pueden reconstruir muy bien el audio, y tampoco hay forma de modelar este residuo. Sin embargo, para los VIT tradicionales, hay formas de crear algunas señales de supervisión, como espectros lineales o mediante el uso de embebidos aprendices para aprender la duración. Estas observaciones finalmente llevaron a este método a lograr muy buenos resultados.
Visite la página de demostración
Visite los modelos previamente capacitados
pip install -e .
Use el ttts/prepare/bpe_all_text_to_one_file.py para fusionar todo el texto que haya recopilado. Para entrenar el tokenizador, consulte el ttts/gpt/voice_tokenizer para obtener más información.
Use 1_vad_asr_save_to_jsonl.py y 2_romanize_text.py para preprocess DataSet. Use las siguientes instrucciones para entrenar el modelo.
accelerate launch ttts/vqvae/train_v3.py
Ahora apoya chino, inglés, japonés, coreano.
Puede usar cualquier idioma con este modelo con dos pasos.
ttts/gpt/voice_tokenizer para obtener un diccionario.Para el inglés, puede usar directamente el texto. Sin embargo, para el chino, debe usar pinyin y para japonés, debe usar romaji, asegurarse de incluir información de pronunciación en el texto.
Consulte la api.py para obtener detalles de inferencia.
Cambie la ruta de carga en Train_V3.py con el modelo previamente petrano, luego entrene. Sobre el conjunto de datos, debe preprocesar el texto y la ruta de audio y el latín. Puede consultar ttts/prepare/2_romanize_text.py para obtener información.


