ttts
1.0.0
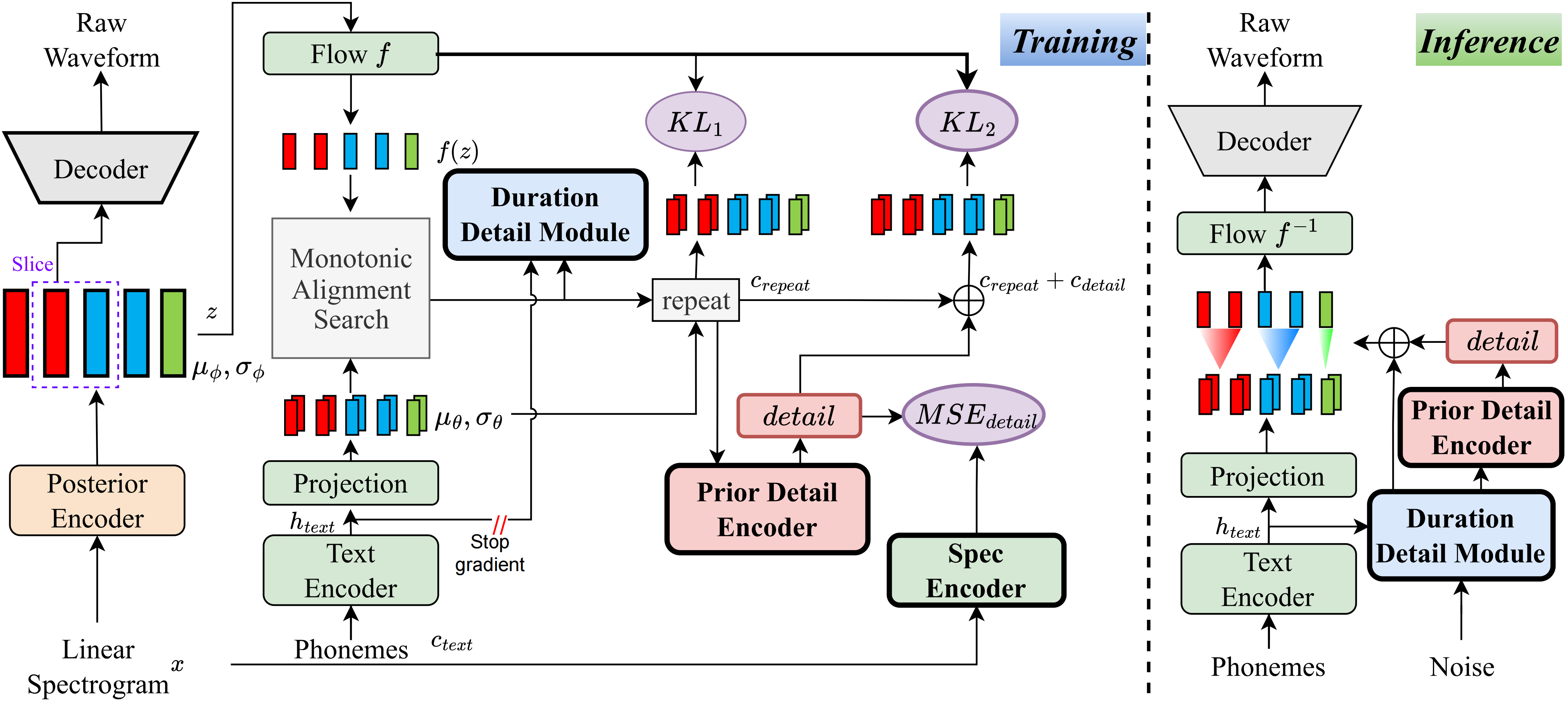
私の知る限り、このプロジェクトの方法は、私が提案した最初の方法です。主なアイデアは、VQ(Vector量子化)ベースの方法がオーディオを非常にうまく再構築できず、この残差をモデル化する方法もありません。ただし、従来のVITの場合、線形スペクトルなどの監督信号を作成する方法、または学習可能な埋め込みを使用して期間を学習する方法があります。これらの観察結果は、最終的にこの方法が非常に良い結果を達成することにつながりました。
デモページにアクセスしてください
事前に訓練されたモデルにアクセスしてください
pip install -e .
ttts/prepare/bpe_all_text_to_one_file.pyを使用して、収集したすべてのテキストをマージします。トークンザーをトレーニングするには、詳細についてはttts/gpt/voice_tokenizerを確認してください。
1_vad_asr_save_to_jsonl.pyと2_romanize_text.pyを使用して、プレースセットを使用してください。次の命令を使用して、モデルをトレーニングします。
accelerate launch ttts/vqvae/train_v3.py
現在、中国語、英語、日本語、韓国語をサポートしています。
このモデルでは、2つのステップで任意の言語を使用できます。
ttts/gpt/voice_tokenizerをトレーニングします。英語の場合、テキストを直接使用できます。ただし、中国語の場合はPinyinを使用する必要があり、日本語にはRomajiを使用して、テキストに発音情報を必ず含める必要があります。
推論の詳細については、 api.py確認してください。
Train_V3.pyのロードパスを前処理されたモデルで変更してから、トレーニングします。データセットについて、テキストとオーディオパスとラテン語を事前に処理する必要があります。いくつかの情報についてはttts/prepare/2_romanize_text.pyを参照できます。


