ttts
1.0.0
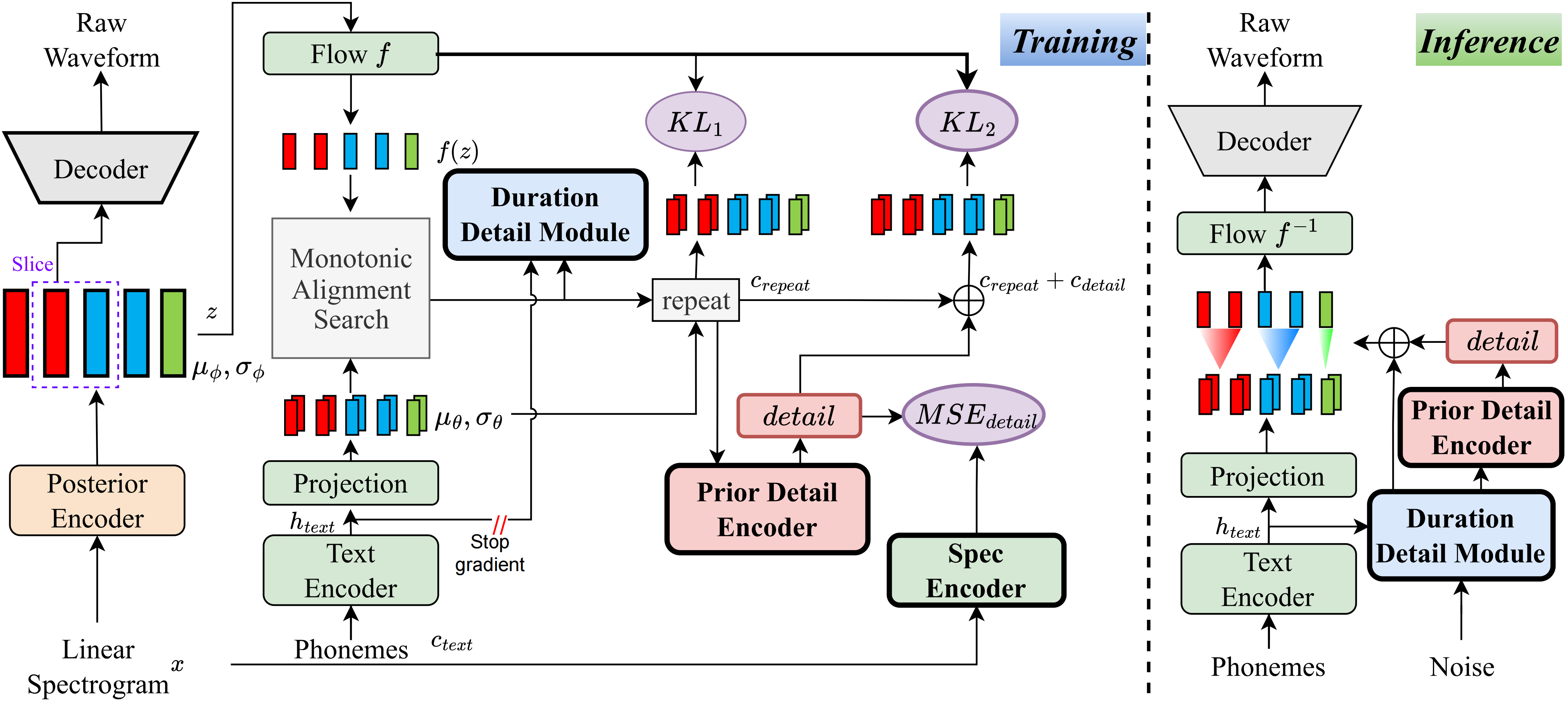
Nach meinem besten Wissen ist die Methode in diesem Projekt die erste ihrer Art, die ich vorgeschlagen habe. Die Hauptidee beruht auf der Modellierung von "Details", da ich durch die Tatsache beunruhigt bin, dass VQ -Methoden (Vector Quantization) Audio nicht sehr gut rekonstruieren können, und es gibt auch keine Möglichkeit, diesen Rest zu modellieren. Für herkömmliche Vits gibt es jedoch Möglichkeiten, einige aufsichtsrechtliche Signale wie lineare Spektren zu erstellen oder lernbare Einbettungen zu verwenden, um die Dauer zu erlernen. Diese Beobachtungen führten letztendlich dazu, dass diese Methode sehr gute Ergebnisse erzielte.
Besuchen Sie die Demo -Seite
Besuchen Sie die vorgebildeten Modelle
pip install -e .
Verwenden Sie die ttts/prepare/bpe_all_text_to_one_file.py um den gesamten von Ihnen gesammelten Text zusammenzuführen. Um den Tokenizer zu trainieren, überprüfen Sie die ttts/gpt/voice_tokenizer um weitere Informationen zu erhalten.
Verwenden Sie die 1_vad_asr_save_to_jsonl.py und 2_romanize_text.py um den Datensatz vorzubereiten. Verwenden Sie die folgende Anweisung, um das Modell zu trainieren.
accelerate launch ttts/vqvae/train_v3.py
Unterstützen Sie jetzt Chinesisch, Englisch, Japanisch, Koreanisch.
Sie können jede Sprache mit diesem Modell mit zwei Schritt verwenden.
ttts/gpt/voice_tokenizer um ein Wörterbuch zu erhalten.Für Englisch können Sie den Text direkt verwenden. Für Chinesen müssen Sie jedoch Pinyin verwenden, und für Japanisch müssen Sie Romaji verwenden, um sicherzustellen, dass Ausspracheinformationen in den Text aufgenommen werden.
Bitte überprüfen Sie die api.py auf Inferenzdetail.
Ändern Sie den Lastpfad in train_v3.py mit vorbereitetem Modell und trainieren Sie ihn. Über den Datensatz sollten Sie den Text und den Audiopfad und das Latein vorbereiten. Sie können sich auf ttts/prepare/2_romanize_text.py beziehen, um einige Informationen zu erhalten.


