ttts
1.0.0
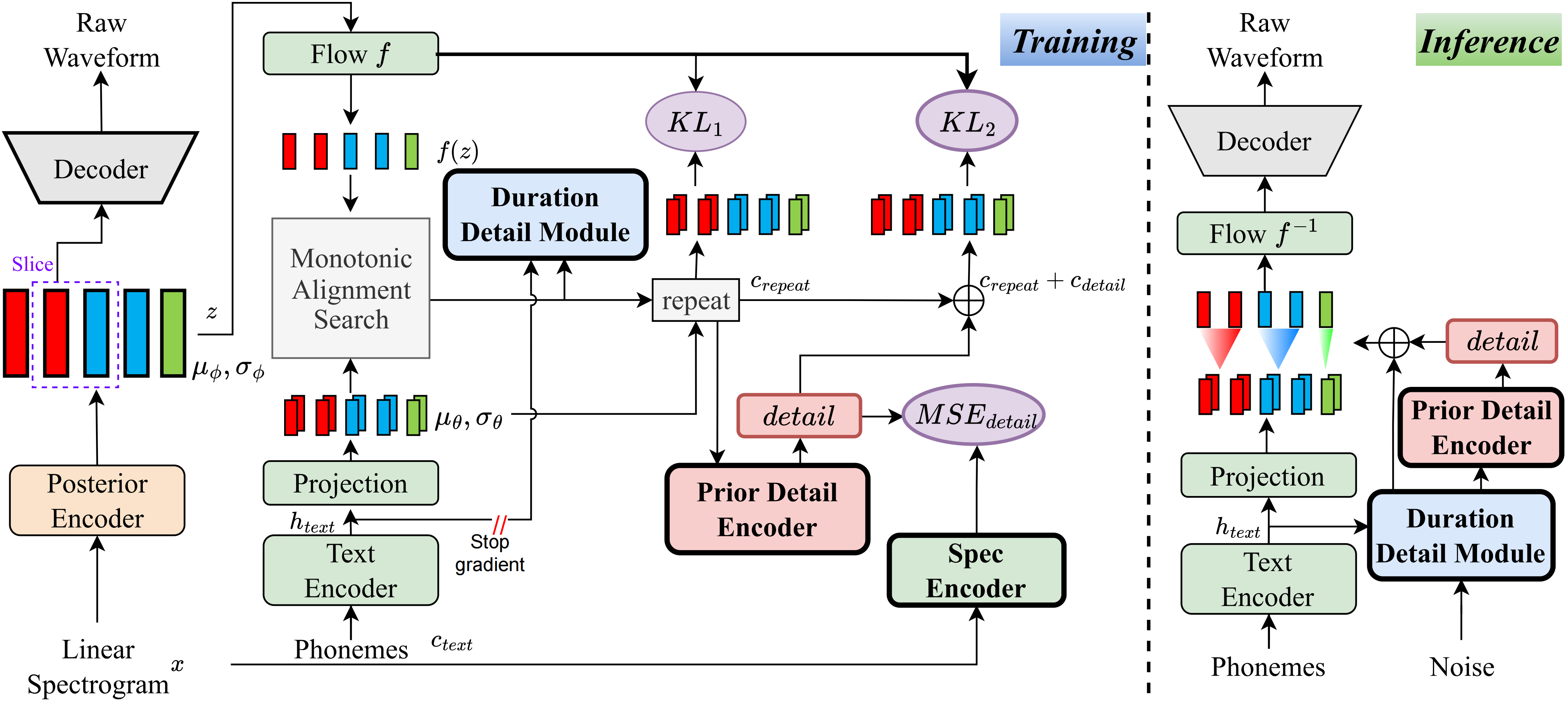
Насколько мне известно, метод в этом проекте является первым в своем роде, который я предложил. Основная идея проистекает из моделирования «детализации», так как я был обеспокоен тем фактом, что методы, основанные на VQ (векторный квантизация), не могут очень хорошо реконструировать аудио, а также нет способа смоделировать этот остаток. Тем не менее, для традиционных VIT есть способы создать некоторые надзорные сигналы, такие как линейные спектры, или с использованием обучаемых встраиваний для изучения продолжительности. Эти наблюдения в конечном итоге привели к тому, что этот метод достиг очень хороших результатов.
Посетите демо -страницу
Посетите предварительно обученные модели
pip install -e .
Используйте ttts/prepare/bpe_all_text_to_one_file.py чтобы объединить весь текст, который вы собрали. Чтобы тренировать токенизатор, проверьте ttts/gpt/voice_tokenizer для получения дополнительной информации.
Используйте 1_vad_asr_save_to_jsonl.py и 2_romanize_text.py для набора данных PREP -FROCESS. Используйте следующую инструкцию для обучения модели.
accelerate launch ttts/vqvae/train_v3.py
Теперь поддерживайте китайский, английский, японский, корейский.
Вы можете использовать любой язык с этой моделью с двумя шагами.
ttts/gpt/voice_tokenizer чтобы получить словарь.Для английского вы можете напрямую использовать текст. Тем не менее, для китайцев вам нужно использовать Pinyin, а для японского необходимо использовать ромаджи, чтобы включить информацию об произношении в тексте.
Пожалуйста, проверьте api.py для получения подробностей.
Измените путь нагрузки в Train_v3.py с предварительной моделью, затем тренируйте его. О наборе данных вы должны предварительно обрабатывать текст и аудио -путь и латинский. Вы можете обратиться к ttts/prepare/2_romanize_text.py для некоторой информации.


