ttts
1.0.0
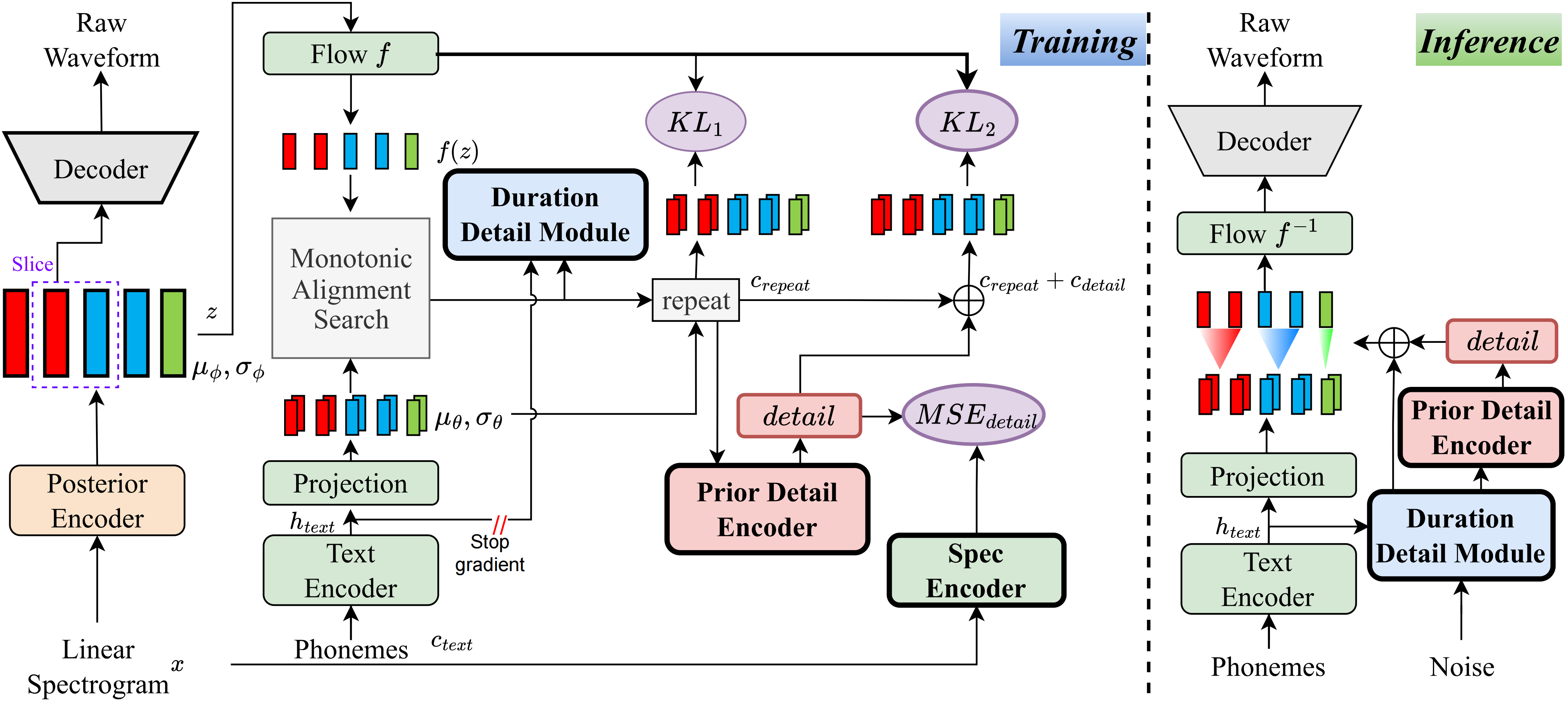
À ma connaissance, la méthode de ce projet est la première du genre que j'ai proposée. L'idée principale découle de la modélisation des «détails», car j'ai été troublé par le fait que les méthodes basées sur VQ (quantification vectorielle) ne peuvent pas très bien reconstruire l'audio, et il n'y a également aucun moyen de modéliser ce résidu. Cependant, pour les vites traditionnelles, il existe des moyens de créer des signaux de supervision, tels que des spectres linéaires, ou en utilisant des intégres apprenables pour apprendre la durée. Ces observations ont finalement conduit à cette méthode d'obtenir de très bons résultats.
Visitez la page Demo
Visitez les modèles pré-formés
pip install -e .
Utilisez le ttts/prepare/bpe_all_text_to_one_file.py pour fusionner tout le texte que vous avez collecté. Pour former le tokenizer, consultez le ttts/gpt/voice_tokenizer pour plus d'informations.
Utilisez le 1_vad_asr_save_to_jsonl.py et 2_romanize_text.py vers le jeu de données de prétraitement. Utilisez l'instruction suivante pour former le modèle.
accelerate launch ttts/vqvae/train_v3.py
Soutenez maintenant chinois, anglais, japonais, coréen.
Vous pouvez utiliser n'importe quelle langue avec ce modèle avec deux étapes.
ttts/gpt/voice_tokenizer pour obtenir un dictionnaire.Pour l'anglais, vous pouvez utiliser directement le texte. Cependant, pour le chinois, vous devez utiliser Pinyin et pour le japonais, vous devez utiliser Romaji, en vous assurant d'inclure des informations de prononciation dans le texte.
Veuillez vérifier l' api.py pour les détails d'inférence.
Changez le chemin de charge dans Train_v3.py avec un modèle pré-entraîné, puis entraînez-le. À propos de l'ensemble de données, vous devez prétraiter le texte et le chemin audio et le latin. Vous pouvez vous référer à ttts/prepare/2_romanize_text.py pour quelques informations.


