ttts
1.0.0
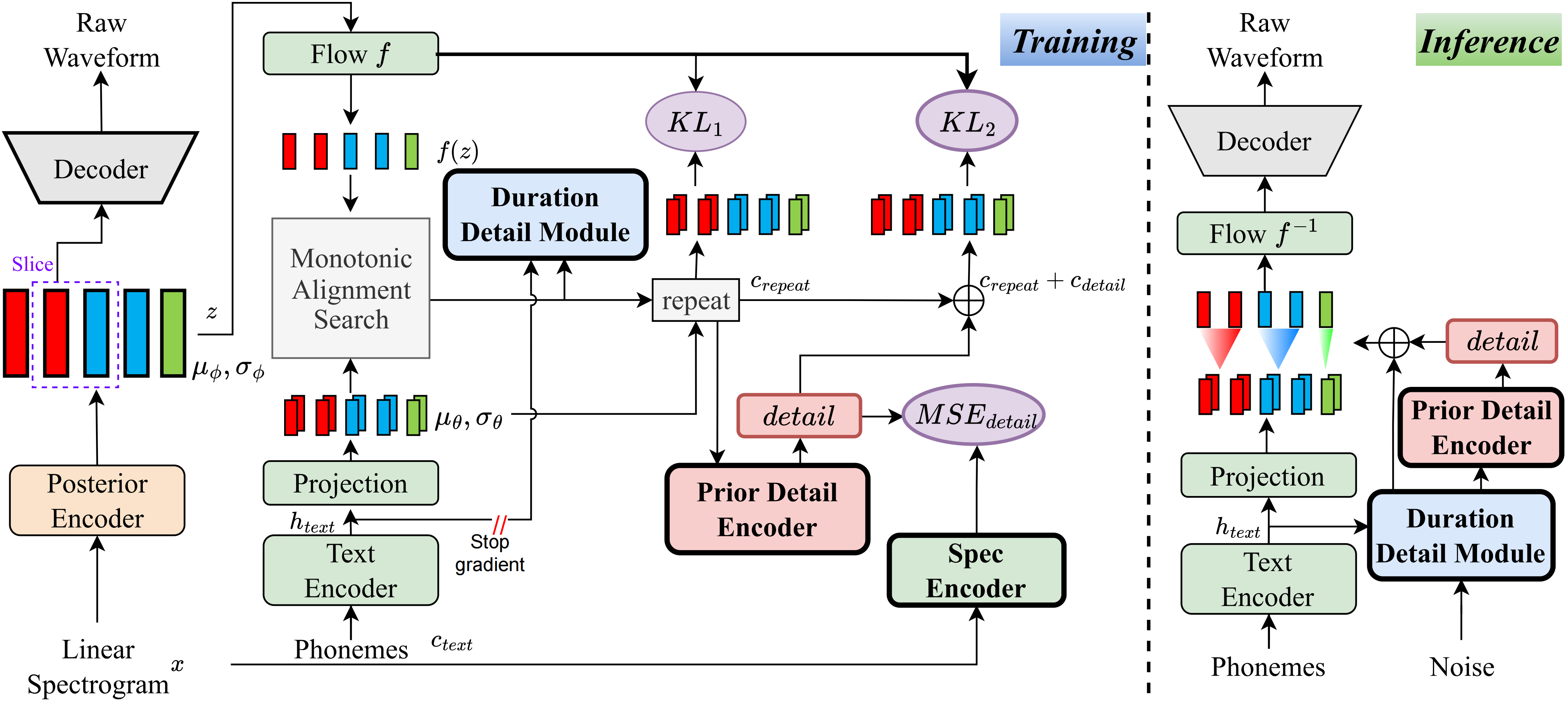
เพื่อความรู้ที่ดีที่สุดของฉันวิธีการในโครงการนี้เป็นครั้งแรกที่ฉันเสนอ แนวคิดหลักเกิดจากการสร้างแบบจำลองของ 'รายละเอียด' เนื่องจากฉันมีปัญหากับความจริงที่ว่าวิธีการที่ใช้ VQ (Vector Quantization) ไม่สามารถสร้างเสียงได้เป็นอย่างดีและยังไม่มีวิธีการจำลองที่เหลือนี้ อย่างไรก็ตามสำหรับ VITS แบบดั้งเดิมมีวิธีการสร้างสัญญาณกำกับดูแลบางอย่างเช่นสเปกตรัมเชิงเส้นหรือโดยใช้การฝังที่เรียนรู้ได้เพื่อเรียนรู้ระยะเวลา ในที่สุดการสังเกตเหล่านี้นำไปสู่วิธีนี้เพื่อให้ได้ผลลัพธ์ที่ดีมาก
เยี่ยมชมหน้าสาธิต
เยี่ยมชมรุ่นที่ผ่านการฝึกอบรมมาก่อน
pip install -e .
ใช้ ttts/prepare/bpe_all_text_to_one_file.py เพื่อรวมข้อความทั้งหมดที่คุณรวบรวม ในการฝึกอบรมโทเค็นให้ตรวจสอบ ttts/gpt/voice_tokenizer สำหรับข้อมูลเพิ่มเติม
ใช้ 1_vad_asr_save_to_jsonl.py และ 2_romanize_text.py ไปยังชุดข้อมูลล่วงหน้า ใช้คำแนะนำต่อไปนี้เพื่อฝึกอบรมแบบจำลอง
accelerate launch ttts/vqvae/train_v3.py
ตอนนี้สนับสนุนจีน, อังกฤษ, ญี่ปุ่น, เกาหลี
คุณสามารถใช้ภาษาใดก็ได้กับโมเดลนี้ด้วยสองขั้นตอน
ttts/gpt/voice_tokenizer เพื่อรับพจนานุกรมสำหรับภาษาอังกฤษคุณสามารถใช้ข้อความได้โดยตรง อย่างไรก็ตามสำหรับภาษาจีนคุณต้องใช้พินอินและสำหรับญี่ปุ่นคุณต้องใช้ Romaji ตรวจสอบให้แน่ใจว่าได้รวมข้อมูลการออกเสียงในข้อความ
โปรดตรวจสอบ api.py สำหรับรายละเอียดการอนุมาน
เปลี่ยนเส้นทางโหลดใน train_v3.py ด้วยรุ่นที่ผ่านการฝึกอบรมแล้วฝึกซ้อม เกี่ยวกับชุดข้อมูลคุณควรประมวลผลข้อความและเสียงและละตินล่วงหน้า คุณสามารถอ้างถึง ttts/prepare/2_romanize_text.py สำหรับข้อมูลบางอย่าง


