ttts
1.0.0
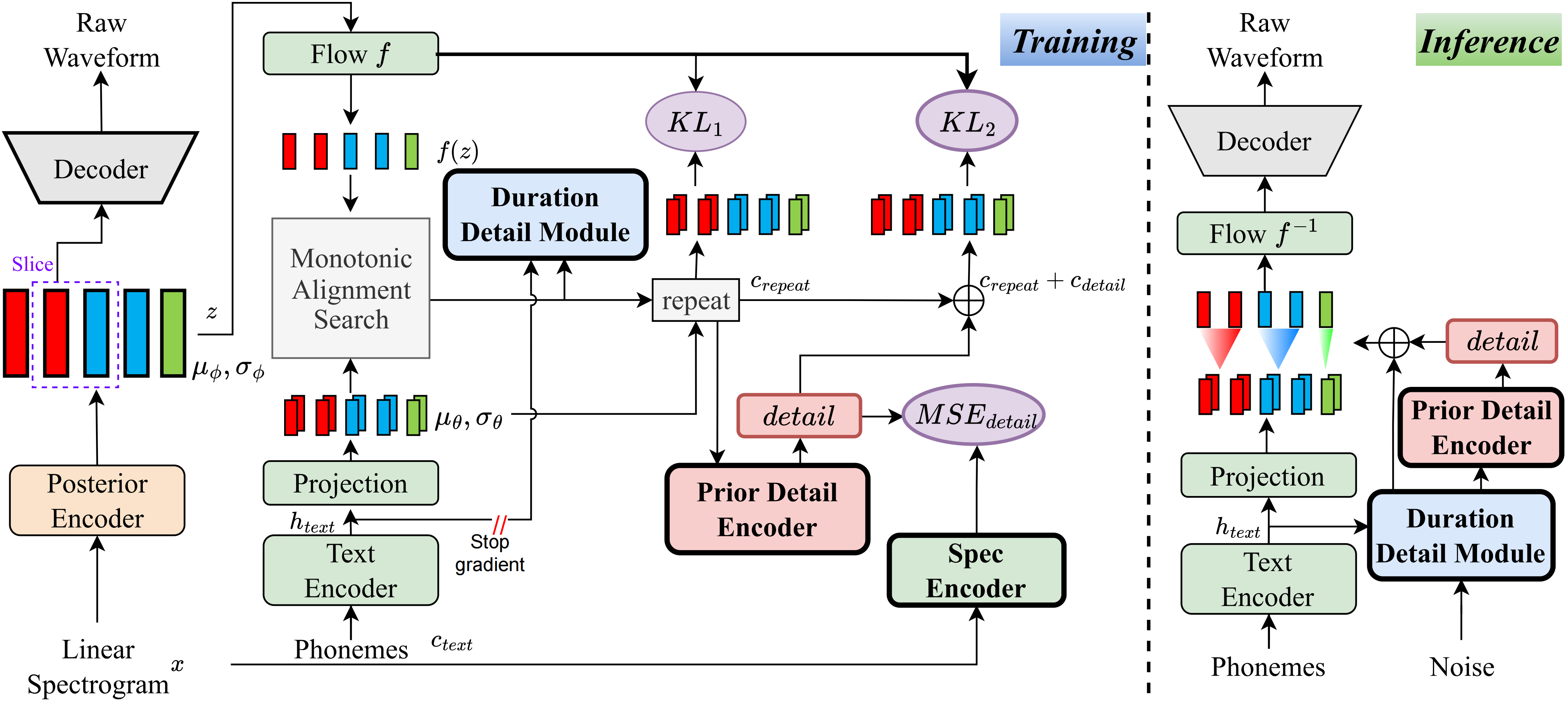
내가 아는 한,이 프로젝트의 방법은 내가 제안한 첫 번째 종류입니다. VQ (Vector Quantization) 기반 방법이 오디오를 잘 재구성 할 수 없으며이 잔차를 모델링 할 수있는 방법이 없기 때문에 주요 아이디어는 '세부 사항'모델링에서 비롯됩니다. 그러나 전통적인 VIT의 경우 선형 스펙트럼과 같은 감독 신호를 만들거나 학습 가능한 임베딩을 사용하여 지속 시간을 배우는 방법이 있습니다. 이러한 관찰은 궁극적 으로이 방법으로 이어졌습니다.
데모 페이지를 방문하십시오
미리 훈련 된 모델을 방문하십시오
pip install -e .
수집 한 모든 텍스트를 병합하려면 ttts/prepare/bpe_all_text_to_one_file.py 사용하십시오. Tokenizer를 훈련 시키려면 자세한 내용은 ttts/gpt/voice_tokenizer 확인하십시오.
1_vad_asr_save_to_jsonl.py 및 2_romanize_text.py 를 사용하여 사전 프로세스 데이터 세트를 사용하십시오. 다음 지침을 사용하여 모델을 교육하십시오.
accelerate launch ttts/vqvae/train_v3.py
이제 중국어, 영어, 일본어, 한국을 지원하십시오.
이 모델에서는 두 단계로 모든 언어를 사용할 수 있습니다.
ttts/gpt/voice_tokenizer 훈련시켜 사전을 얻으십시오.영어의 경우 텍스트를 직접 사용할 수 있습니다. 그러나 중국어의 경우 Pinyin을 사용해야하며 일본어의 경우 로마지를 사용하여 텍스트에 발음 정보를 포함해야합니다.
추론에 대해서는 api.py 확인하십시오.
사전 각인 모델로 train_v3.py에서로드 경로를 변경 한 다음 훈련하십시오. 데이터 세트에 대해, 텍스트와 오디오 경로와 라틴어를 전제해야합니다. 정보는 ttts/prepare/2_romanize_text.py 를 참조 할 수 있습니다.


