ttts
1.0.0
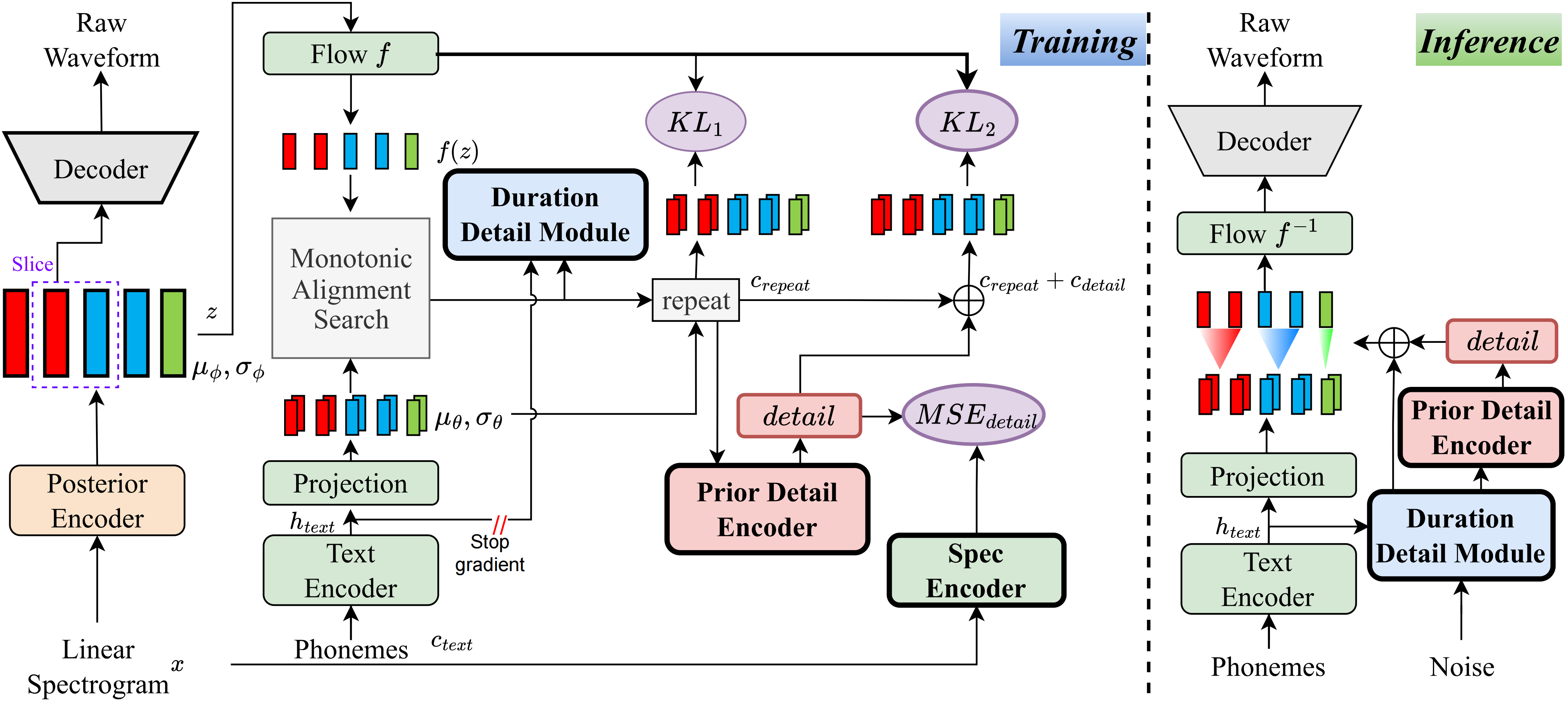
Que eu saiba, o método deste projeto é o primeiro do gênero que propus. A idéia principal decorre da modelagem de 'detalhes', pois me incomodei com o fato de que os métodos baseados em VQ (quantização do vetor) não podem reconstruir muito bem o áudio, e também não há como modelar esse resíduo. No entanto, para os Vits tradicionais, existem maneiras de criar alguns sinais de supervisão, como espectros lineares ou usando incorporações aprendidas para aprender a duração. Essas observações levaram a esse método alcançar resultados muito bons.
Visite a página de demonstração
Visite os modelos pré-treinados
pip install -e .
Use o ttts/prepare/bpe_all_text_to_one_file.py para mesclar todo o texto que você coletou. Para treinar o tokenizer, verifique o ttts/gpt/voice_tokenizer para obter mais informações.
Use o 1_vad_asr_save_to_jsonl.py e 2_romanize_text.py para pré -processar o conjunto de dados. Use a seguinte instrução para treinar o modelo.
accelerate launch ttts/vqvae/train_v3.py
Agora apoie chinês, inglês, japonês, coreano.
Você pode usar qualquer idioma com este modelo com duas etapas.
ttts/gpt/voice_tokenizer para obter um dicionário.Para o inglês, você pode usar diretamente o texto. No entanto, para chinês, você precisa usar o pinyin e, para japonês, precisa usar Romaji, certificando -se de incluir informações de pronúncia no texto.
Por favor, verifique o api.py para obter detalhes de inferência.
Altere o caminho de carga em trens_v3.py com modelo pré -criado e treine -o. Sobre o conjunto de dados, você deve pré -processar o texto e o caminho de áudio e o latim. Você pode consultar ttts/prepare/2_romanize_text.py para obter algumas informações.


