ttts
1.0.0
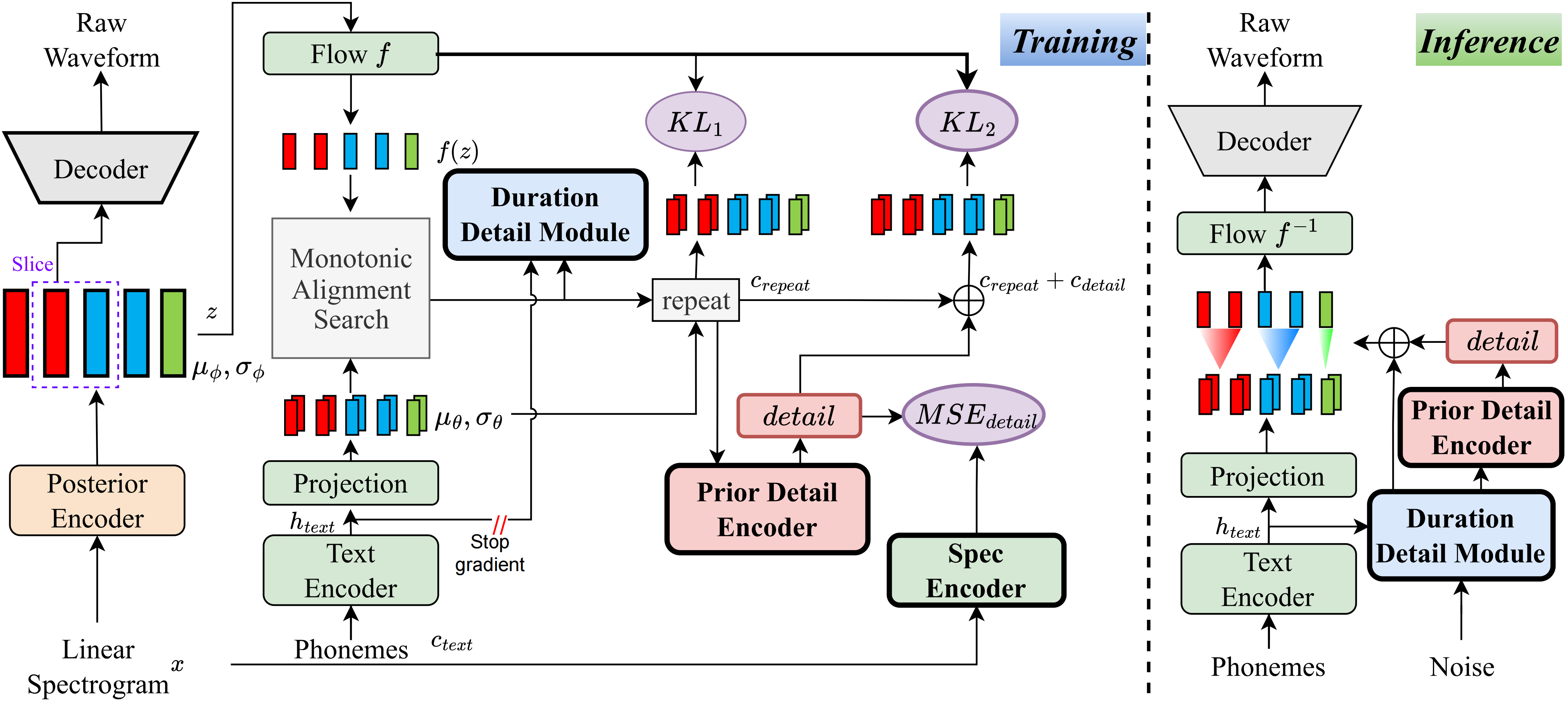
Sepengetahuan saya, metode dalam proyek ini adalah yang pertama dari jenisnya yang telah saya usulkan. Gagasan utama berasal dari pemodelan 'detail', karena saya telah bermasalah dengan fakta bahwa metode berbasis VQ (kuantisasi vektor) tidak dapat merekonstruksi audio dengan sangat baik, dan juga tidak ada cara untuk memodelkan residu ini. Namun, untuk VIT tradisional, ada cara untuk membuat beberapa sinyal pengawasan, seperti spektrum linier, atau dengan menggunakan embeddings yang dapat dipelajari untuk mempelajari durasi. Pengamatan ini pada akhirnya menyebabkan metode ini mencapai hasil yang sangat baik.
Kunjungi Halaman Demo
Kunjungi model pra-terlatih
pip install -e .
Gunakan ttts/prepare/bpe_all_text_to_one_file.py untuk menggabungkan semua teks yang telah Anda kumpulkan. Untuk melatih tokenizer, periksa ttts/gpt/voice_tokenizer untuk info lebih lanjut.
Gunakan 1_vad_asr_save_to_jsonl.py dan 2_romanize_text.py ke dataset preprocess. Gunakan instruksi berikut untuk melatih model.
accelerate launch ttts/vqvae/train_v3.py
Sekarang mendukung Cina, Inggris, Jepang, Korea.
Anda dapat menggunakan bahasa apa pun dengan model ini dengan dua langkah.
ttts/gpt/voice_tokenizer untuk mendapatkan kamus.Untuk bahasa Inggris, Anda dapat langsung menggunakan teks. Namun, untuk orang Cina, Anda perlu menggunakan pinyin, dan untuk bahasa Jepang, Anda perlu menggunakan romaji, memastikan untuk memasukkan informasi pengucapan dalam teks.
Silakan periksa detail inferensi api.py
Ubah jalur beban di train_v3.py dengan model pretrained, lalu latih. Tentang dataset, Anda harus preprocess teks dan jalur audio dan Latin. Anda dapat merujuk ke ttts/prepare/2_romanize_text.py untuk beberapa info.


