TTS Tacotron Pytorch
1.0.0
Google的Tacotron語音合成網絡的Pytorch實現。
該實現還包括對位置敏感的關注以及Tacotron 2的停止令牌功能。
此外,使用訓練的模型在LJ語音數據集上進行了培訓。
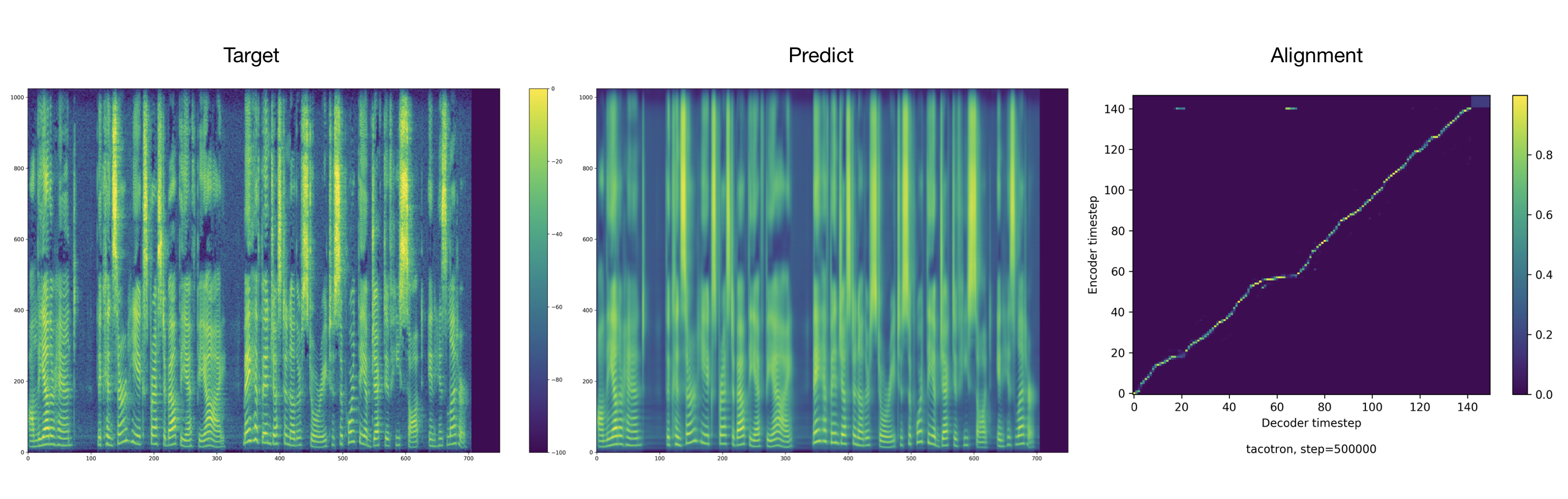
可以在結果目錄中找到音頻樣本。
該實現基於R9Y9/Tacotron_pytorch,主要區別是:
此外,與原始的Tacotron紙有一些差異是:
音頻質量還不如Google的演示,但希望最終會有所改善。歡迎拉動請求!
git clone [email protected]:andi611/Tacotron-Pytorch.gitcd Tacotron-Pytorch安裝Python 3。
根據您的平台安裝最新版本的Pytorch 。為了獲得更好的性能,請在可行的情況下使用GPU支持(CUDA)安裝。該代碼可與Pytorch 0.4及更高版本一起使用。
安裝要求:
pip3 install -r requirements.txt
警告:您需要根據平台安裝火炬。這裡列出構建此項目時使用的Pytorch版本。
下載LJ語音數據集。
如果將其他數據集轉換為正確的格式,則可以使用其他數據集。有關更多信息,請參見triaze_data.md。
將數據集解開為~/Tacotron-Pytorch/data data
解開包裝後,您的樹應該像這樣的LJ演講:
|- Tacotron-Pytorch
|- data
|- LJSpeech-1.1
|- metadata.csv
|- wavs
預處理LJ語音數據集,並使用Preprocess.py製作模型的元文件:
python3 preprocess.py --mode make
預處理後,您的樹看起來像這樣:
|- Tacotron-Pytorch
|- data
|- LJSpeech-1.1 (The downloaded dataset)
|- metadata.csv
|- wavs
|- meta (generate by preprocessing)
|- meta_text.txt
|- meta_mel_xxxxx.npy ...
|- meta_spec_xxxxx.npy ...
|- test_transcripts.txt (provided)
使用train.py訓練模型
python3 train.py --ckpt_dir ckpt/ --log_dir log/
從以前的檢查站恢復培訓:
python3 train.py --ckpt_dir ckpt/ --log_dir log/ --model_name 500000
可調超參數可在config.py中找到。
您可以通過編輯文件來調整這些參數並設置設置,建議使用默認的超參數用於LJ語音。
用張板監視(可選)
tensorboard --logdir 'path to log_dir'
培訓師默認情況下每2000個步驟一次傾倒音頻和對齊。您可以在tacotron/ckpt/中找到這些。
python3 test.py --interactive --plot --model_name 500000
python3 test.py --plot --model_name 500000 --test_file_path ./data/test_transcripts.txt
Yamamoto Ryuichi的歸功於Tacotron的出色pytorch實施,這項工作主要基於。這項工作還受到NVIDIA的Tacotron 2 Pytorch實施的啟發。


