TTS Tacotron Pytorch
1.0.0
Una implementación de Pytorch de la red de síntesis de discurso Tacotron de Google.
Esta implementación también incluye la atención sensible a la ubicación y las características del token de parada de Tacotron 2.
Además, el modelo está capacitado en el conjunto de datos de discurso LJ, con un modelo capacitado proporcionado.
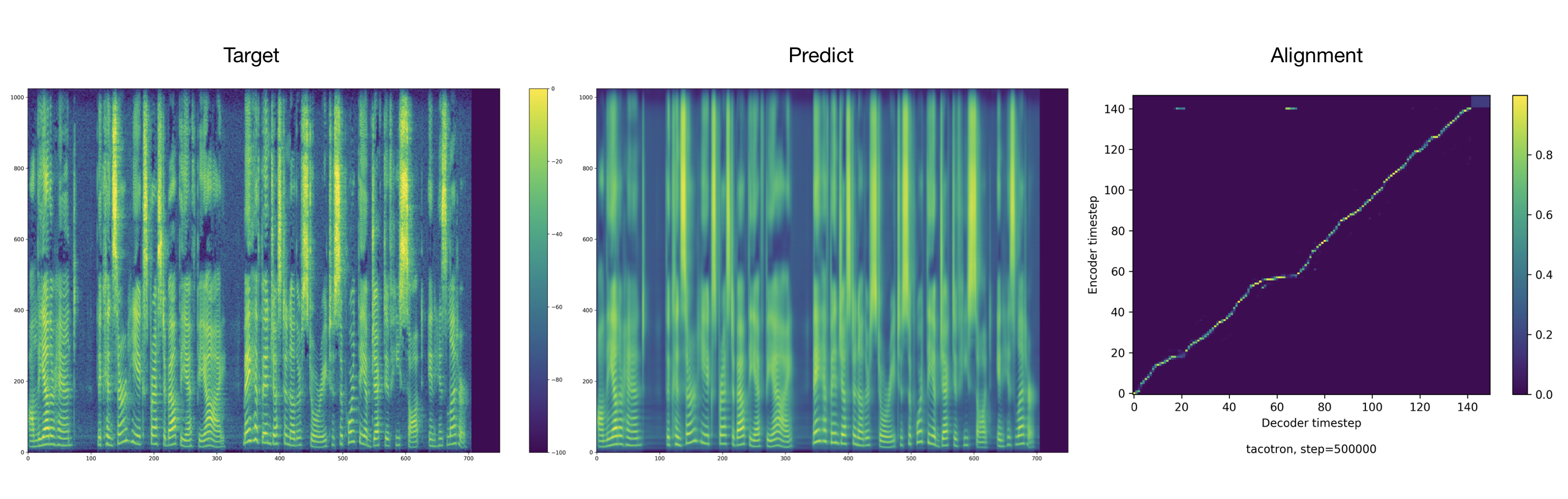
Las muestras de audio se pueden encontrar en el directorio de resultados.
Esta implementación se basa en r9y9/tacotron_pytorch, las principales diferencias son:
Además, algunas diferencias con respecto al papel tacotrón original son:
La calidad de audio aún no es tan buena como la demostración de Google, pero con suerte mejorará eventualmente. ¡Las solicitudes de extracción son bienvenidas!
git clone [email protected]:andi611/Tacotron-Pytorch.gitcd Tacotron-PytorchInstale Python 3.
Instale la última versión de Pytorch de acuerdo con su plataforma. Para un mejor rendimiento, instale con soporte de GPU (CUDA) si es viable. Este código funciona con Pytorch 0.4 y posterior.
Requisitos de instalación:
pip3 install -r requirements.txt
Advertencia: debe instalar antorcha dependiendo de su plataforma. Aquí enumere la versión de Pytorch utilizada cuando se crea, este proyecto fue construido.
Descargue el conjunto de datos de discurso LJ.
Puede usar otros conjuntos de datos si los convierte en el formato correcto. Vea el entrenamiento_data.md para obtener más información.
Desempaqué el conjunto de datos en ~/Tacotron-Pytorch/data
Después de desempacar, su árbol debería verse así para el discurso LJ:
|- Tacotron-Pytorch
|- data
|- LJSpeech-1.1
|- metadata.csv
|- wavs
Preprocese el conjunto de datos de discurso LJ y haga archivos meta listos para el modelo usando preprocess.py:
python3 preprocess.py --mode make
Después del preprocesamiento, su árbol se verá así:
|- Tacotron-Pytorch
|- data
|- LJSpeech-1.1 (The downloaded dataset)
|- metadata.csv
|- wavs
|- meta (generate by preprocessing)
|- meta_text.txt
|- meta_mel_xxxxx.npy ...
|- meta_spec_xxxxx.npy ...
|- test_transcripts.txt (provided)
Entrena un modelo usando Train.py
python3 train.py --ckpt_dir ckpt/ --log_dir log/
Restaurar la capacitación desde un punto de control anterior:
python3 train.py --ckpt_dir ckpt/ --log_dir log/ --model_name 500000
Los hiperparámetros sintonizables se encuentran en config.py.
Puede ajustar estos parámetros y la configuración editando el archivo, se recomiendan los hiperparámetros predeterminados para el discurso LJ.
Monitorear con TensorBoard (opcional)
tensorboard --logdir 'path to log_dir'
El entrenador arroja audio y alineaciones cada 2000 pasos por defecto. Puede encontrarlos en tacotron/ckpt/ .
python3 test.py --interactive --plot --model_name 500000
python3 test.py --plot --model_name 500000 --test_file_path ./data/test_transcripts.txt
Créditos a Ryuichi Yamamoto para una maravillosa implementación de Pytorch de Tacotron, en la que este trabajo se basa principalmente. Este trabajo también está inspirado en la implementación de Nvidia Tacotron 2 Pytorch.


