TTS Tacotron Pytorch
1.0.0
تطبيق Pytorch لشبكة توليف الكلام Tacotron من Google.
يتضمن هذا التنفيذ أيضًا الاهتمام الحساس للموقع وميزات التوقف الرمزية من Tacotron 2.
علاوة على ذلك ، يتم تدريب النموذج على مجموعة بيانات الكلام LJ ، مع توفير نموذج مدرب.
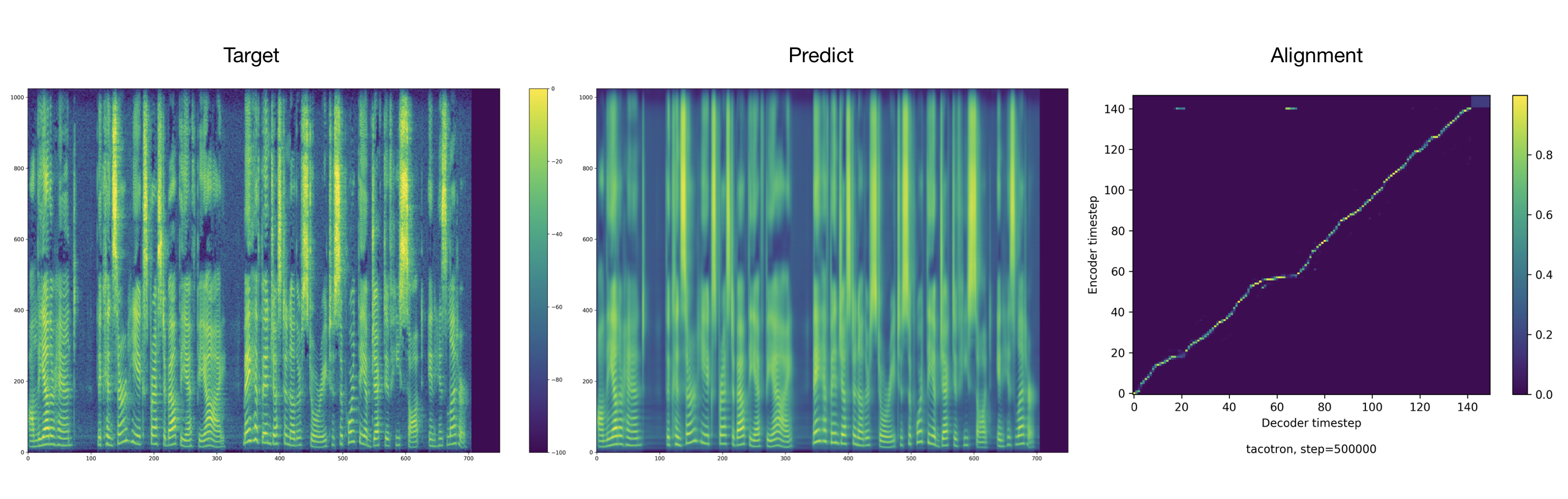
يمكن العثور على عينات الصوت في دليل النتائج.
يعتمد هذا التنفيذ على r9y9/tacotron_pytorch ، والاختلافات الرئيسية هي:
علاوة على ذلك ، بعض الاختلافات عن ورقة تاكوترون الأصلية هي:
جودة الصوت ليست جيدة مثل عرض Google حتى الآن ، ولكن نأمل أن تتحسن في النهاية. طلبات السحب موضع ترحيب!
git clone [email protected]:andi611/Tacotron-Pytorch.gitcd Tacotron-Pytorchتثبيت بيثون 3.
قم بتثبيت أحدث إصدار من Pytorch وفقًا للمنصة. لتحسين الأداء ، قم بالتثبيت باستخدام دعم GPU (CUDA) إذا كان قابلاً للتطبيق. يعمل هذا الرمز مع Pytorch 0.4 وبعد ذلك.
متطلبات التثبيت:
pip3 install -r requirements.txt
تحذير: تحتاج إلى تثبيت الشعلة اعتمادًا على النظام الأساسي الخاص بك. هنا اذكر نسخة Pytorch المستخدمة عند بناء هذا المشروع.
قم بتنزيل مجموعة بيانات الكلام LJ.
يمكنك استخدام مجموعات البيانات الأخرى إذا قمت بتحويلها إلى التنسيق الصحيح. انظر التدريب_data.md لمزيد من المعلومات.
قم بفك مجموعة البيانات في ~/Tacotron-Pytorch/data
بعد التفريغ ، يجب أن تبدو شجرتك هكذا لخطاب LJ:
|- Tacotron-Pytorch
|- data
|- LJSpeech-1.1
|- metadata.csv
|- wavs
المعالجة المسبقة مجموعة بيانات الكلام LJ وجعل ملفات التعريف جاهزة للمواصفات باستخدام preprocess.py:
python3 preprocess.py --mode make
بعد المعالجة المسبقة ، ستبدو شجرتك هكذا:
|- Tacotron-Pytorch
|- data
|- LJSpeech-1.1 (The downloaded dataset)
|- metadata.csv
|- wavs
|- meta (generate by preprocessing)
|- meta_text.txt
|- meta_mel_xxxxx.npy ...
|- meta_spec_xxxxx.npy ...
|- test_transcripts.txt (provided)
تدريب نموذج باستخدام Train.py
python3 train.py --ckpt_dir ckpt/ --log_dir log/
استعادة التدريب من نقطة تفتيش سابقة:
python3 train.py --ckpt_dir ckpt/ --log_dir log/ --model_name 500000
تم العثور على فرط المسموحات القابلة للضبط في config.py.
يمكنك ضبط هذه المعلمات والإعداد عن طريق تحرير الملف ، ويوصى على فرطاميرات الافتراضية لخطاب LJ.
شاشة مع Tensorboard (اختياري)
tensorboard --logdir 'path to log_dir'
يقوم المدرب بتفريغ الصوت والمحاذاة كل 2000 خطوة بشكل افتراضي. يمكنك العثور على هذه في tacotron/ckpt/ .
python3 test.py --interactive --plot --model_name 500000
python3 test.py --plot --model_name 500000 --test_file_path ./data/test_transcripts.txt
اعتمادات إلى Ryuichi Yamamoto لتنفيذ Pytorch رائع لـ Tacotron ، والذي يعتمد هذا العمل بشكل أساسي. هذا العمل مستوحى أيضًا من تطبيق Tacotron 2 Pytorch في Nvidia.


