TTS Tacotron Pytorch
1.0.0
Uma implementação de Pytorch da rede de síntese de fala tacotron do Google.
Essa implementação também inclui a atenção sensível ao local e os recursos de token de parada do Tacotron 2.
Além disso, o modelo é treinado no conjunto de dados de fala do LJ, com o modelo treinado fornecido.
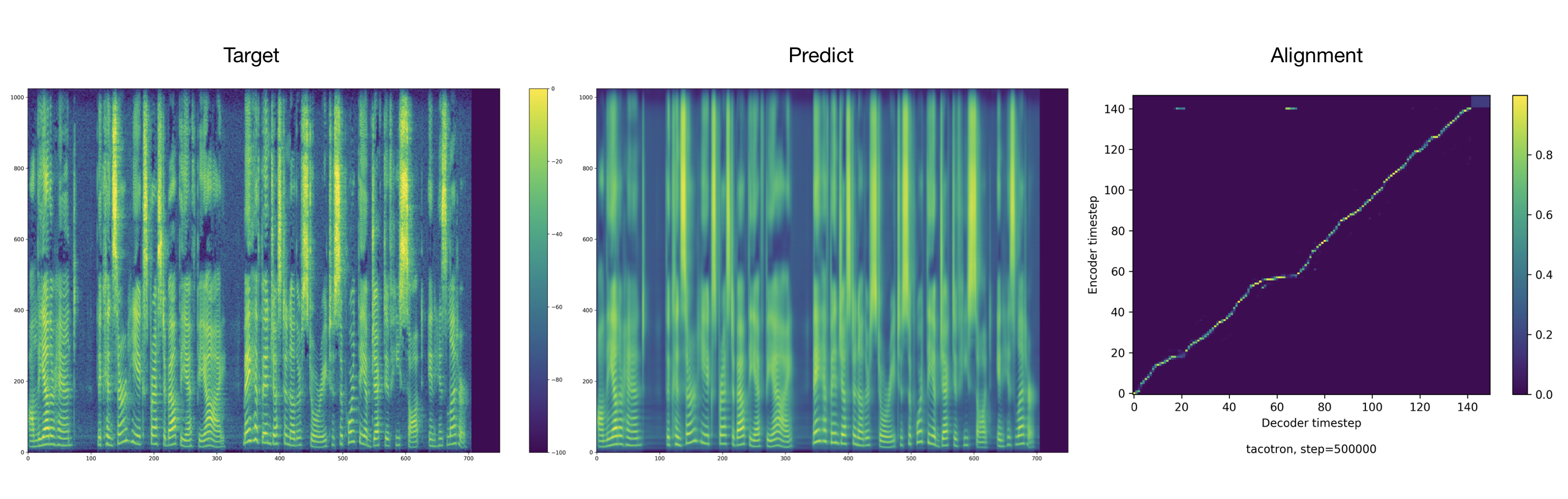
Amostras de áudio podem ser encontradas no diretório de resultados.
Esta implementação é baseada em R9Y9/TACOTRON_PYTORCH, as principais diferenças são:
Além disso, algumas diferenças em relação ao papel original do tacotron são:
A qualidade do áudio ainda não é tão boa quanto a demonstração do Google, mas espero que isso melhore eventualmente. Os pedidos de puxão são bem -vindos!
git clone [email protected]:andi611/Tacotron-Pytorch.gitcd Tacotron-PytorchInstale o Python 3.
Instale a versão mais recente do Pytorch de acordo com sua plataforma. Para melhor desempenho, instale com o suporte da GPU (CUDA) se viável. Este código funciona com Pytorch 0.4 e posterior.
Instalar requisitos:
pip3 install -r requirements.txt
Aviso: você precisa instalar a tocha, dependendo da sua plataforma. Liste aqui a versão pytorch usada quando construída este projeto foi construída.
Faça o download do conjunto de dados de discursos LJ.
Você pode usar outros conjuntos de dados se convertê -los no formato certo. Consulte Training_Data.md para obter mais informações.
Desembale o conjunto de dados em ~/Tacotron-Pytorch/data
Depois de desembalar, sua árvore deve ficar assim para o discurso de LJ:
|- Tacotron-Pytorch
|- data
|- LJSpeech-1.1
|- metadata.csv
|- wavs
Pré-processo o conjunto de dados de fala LJ e faça meta arquivos prontos para o modelo usando preprocess.py:
python3 preprocess.py --mode make
Após o pré -processamento, sua árvore ficará assim:
|- Tacotron-Pytorch
|- data
|- LJSpeech-1.1 (The downloaded dataset)
|- metadata.csv
|- wavs
|- meta (generate by preprocessing)
|- meta_text.txt
|- meta_mel_xxxxx.npy ...
|- meta_spec_xxxxx.npy ...
|- test_transcripts.txt (provided)
Treine um modelo usando trem.py
python3 train.py --ckpt_dir ckpt/ --log_dir log/
Restaurar o treinamento do ponto de verificação anterior:
python3 train.py --ckpt_dir ckpt/ --log_dir log/ --model_name 500000
Os hiperparâmetros ajustáveis são encontrados em config.py.
Você pode ajustar esses parâmetros e definir editando o arquivo, os hyperparameters padrão são recomendados para o discurso de LJ.
Monitor com Tensorboard (opcional)
tensorboard --logdir 'path to log_dir'
O treinador despeja áudio e alinhamentos a cada 2000 etapas por padrão. Você pode encontrá -los em tacotron/ckpt/ .
python3 test.py --interactive --plot --model_name 500000
python3 test.py --plot --model_name 500000 --test_file_path ./data/test_transcripts.txt
Créditos a Ryuichi Yamamoto por uma maravilhosa implementação de Pytorch do Tacotron, na qual este trabalho é baseado principalmente. Este trabalho também é inspirado na implementação do Tacotron 2 da NVIDIA.


