TTS Tacotron Pytorch
1.0.0
Google의 Tacotron Speech Synthesis Network의 Pytorch 구현.
이 구현에는 또한 위치에 민감한 관심 과 Tacotron 2의 스톱 토큰 기능이 포함됩니다.
또한이 모델은 LJ 음성 데이터 세트에서 훈련 된 모델과 함께 교육을받습니다.
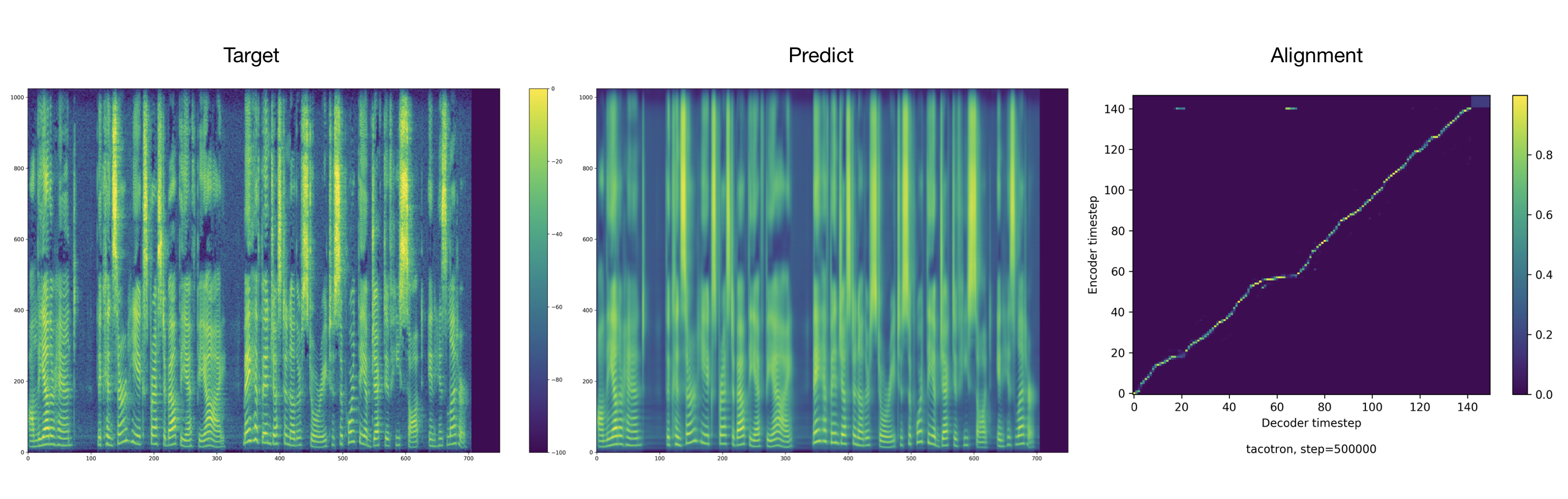
오디오 샘플은 결과 디렉토리에서 찾을 수 있습니다.
이 구현은 r9y9/tacotron_pytorch를 기반으로하며 주요 차이점은 다음과 같습니다.
또한 원래 타코트론 용지와의 일부 차이점은 다음과 같습니다.
오디오 품질은 아직 Google의 데모만큼 좋지는 않지만 결국에는 개선되기를 바랍니다. 풀 요청을 환영합니다!
git clone [email protected]:andi611/Tacotron-Pytorch.gitcd Tacotron-Pytorch파이썬 3을 설치하십시오.
플랫폼에 따라 최신 버전의 Pytorch를 설치하십시오. 더 나은 성능을 보려면 GPU 지원 (CUDA)으로 실행 가능한 경우 설치하십시오. 이 코드는 Pytorch 0.4 이상에서 작동합니다.
요구 사항 설치 :
pip3 install -r requirements.txt
경고 : 플랫폼에 따라 토치를 설치해야합니다. 다음은이 프로젝트를 구축 할 때 사용 된 Pytorch 버전을 나열합니다.
LJ 음성 데이터 세트를 다운로드하십시오.
올바른 형식으로 변환하면 다른 데이터 세트를 사용할 수 있습니다. 자세한 내용은 Training_Data.md를 참조하십시오.
데이터 세트를 ~/Tacotron-Pytorch/data 로 포장하십시오
포장을 풀고 나면 LJ 연설의 경우 나무가 이와 같이 보일 것입니다.
|- Tacotron-Pytorch
|- data
|- LJSpeech-1.1
|- metadata.csv
|- wavs
LJ Speech DataSet을 전처리하고 preprocess.py를 사용하여 모델 지원 메타 파일을 만듭니다.
python3 preprocess.py --mode make
전처리 후에는 나무가 다음과 같습니다.
|- Tacotron-Pytorch
|- data
|- LJSpeech-1.1 (The downloaded dataset)
|- metadata.csv
|- wavs
|- meta (generate by preprocessing)
|- meta_text.txt
|- meta_mel_xxxxx.npy ...
|- meta_spec_xxxxx.npy ...
|- test_transcripts.txt (provided)
Train.py를 사용하여 모델을 훈련하십시오
python3 train.py --ckpt_dir ckpt/ --log_dir log/
이전 검문소에서 교육을 복원하십시오.
python3 train.py --ckpt_dir ckpt/ --log_dir log/ --model_name 500000
조정 가능한 하이퍼 파라미터는 config.py에서 발견됩니다.
파일을 편집하여 이러한 매개 변수를 조정하고 설정할 수 있으며 LJ Speech에는 기본 하이퍼 파라미터가 권장됩니다.
텐서 보드로 모니터링 (선택 사항)
tensorboard --logdir 'path to log_dir'
트레이너는 기본적으로 2000 단계마다 오디오 및 정렬을 덤프합니다. tacotron/ckpt/ 에서 찾을 수 있습니다.
python3 test.py --interactive --plot --model_name 500000
python3 test.py --plot --model_name 500000 --test_file_path ./data/test_transcripts.txt
타코트론의 멋진 파이토치 구현에 대한 Ryuichi Yamamoto에 대한 크레딧은 주로 기반을 둔다. 이 작업은 NVIDIA의 Tacotron 2 Pytorch 구현에서도 영감을 받았습니다.


