TTS Tacotron Pytorch
1.0.0
Une implémentation Pytorch du réseau de synthèse de la parole Tacotron de Google.
Cette implémentation comprend également l' attention sensible à l'emplacement et les fonctionnalités de jeton d'arrêt de Tacotron 2.
En outre, le modèle est formé sur le jeu de données de la parole LJ, avec un modèle formé fourni.
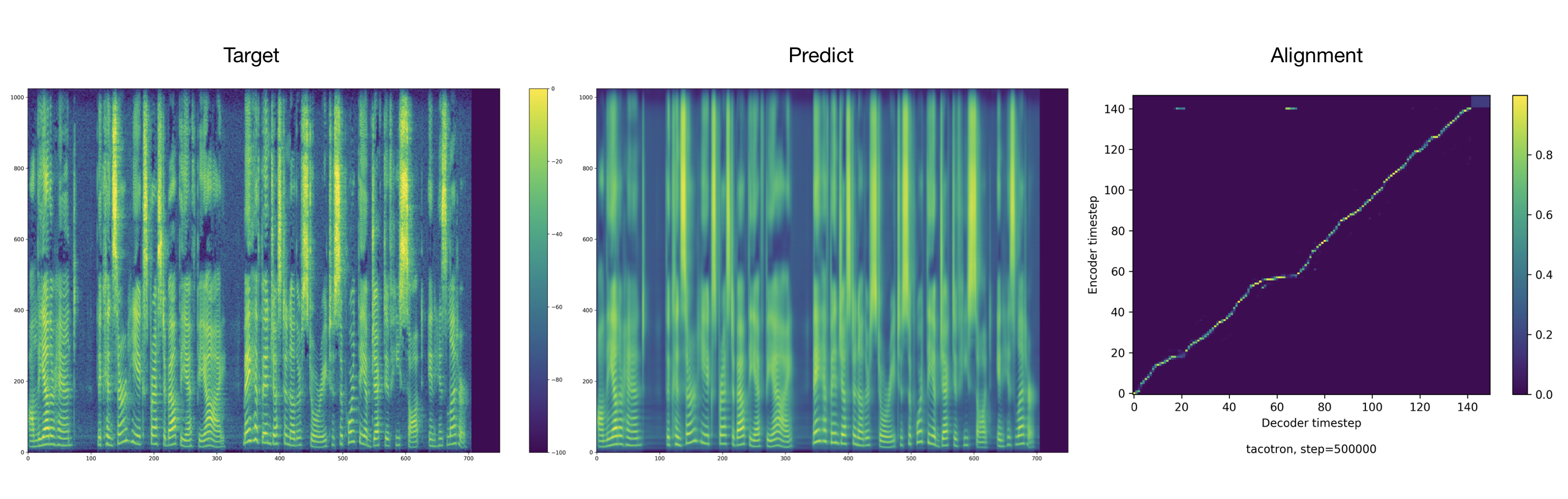
Des échantillons audio peuvent être trouvés dans le répertoire de résultat.
Cette implémentation est basée sur R9Y9 / Tacotron_Pytorch, les principales différences sont:
De plus, certaines différences par rapport au papier tacotron d'origine sont:
La qualité audio n'est pas aussi bonne que la démo de Google, mais j'espère que cela s'améliorera finalement. Les demandes de traction sont les bienvenues!
git clone [email protected]:andi611/Tacotron-Pytorch.gitcd Tacotron-PytorchInstallez Python 3.
Installez la dernière version de Pytorch selon votre plateforme. Pour de meilleures performances, installez avec GPU Support (CUDA) si viable. Ce code fonctionne avec Pytorch 0.4 et plus tard.
Installation des exigences:
pip3 install -r requirements.txt
AVERTISSEMENT: vous devez installer Torch en fonction de votre plate-forme. Ici, énumérez la version Pytorch utilisée lors de la construction de ce projet.
Téléchargez l'ensemble de données LJ Speech.
Vous pouvez utiliser d'autres ensembles de données si vous les convertissez au bon format. Voir Training_data.md pour plus d'informations.
Déballer l'ensemble de données dans ~/Tacotron-Pytorch/data
Après avoir déballé, votre arbre devrait ressembler à ceci pour le discours LJ:
|- Tacotron-Pytorch
|- data
|- LJSpeech-1.1
|- metadata.csv
|- wavs
Prétraitement de l'ensemble de données LJ Speech et créez des fichiers Meta prêts pour les modèles à l'aide de Preprocess.py:
python3 preprocess.py --mode make
Après le prétraitement, votre arbre ressemblera à ceci:
|- Tacotron-Pytorch
|- data
|- LJSpeech-1.1 (The downloaded dataset)
|- metadata.csv
|- wavs
|- meta (generate by preprocessing)
|- meta_text.txt
|- meta_mel_xxxxx.npy ...
|- meta_spec_xxxxx.npy ...
|- test_transcripts.txt (provided)
Train un modèle en utilisant Train.py
python3 train.py --ckpt_dir ckpt/ --log_dir log/
Restaurer la formation d'un point de contrôle précédent:
python3 train.py --ckpt_dir ckpt/ --log_dir log/ --model_name 500000
Des hyperparamètres accordables se trouvent dans config.py.
Vous pouvez ajuster ces paramètres et définir en modifiant le fichier, les hyperparamètres par défaut sont recommandés pour la parole LJ.
Moniteur avec Tensorboard (facultatif)
tensorboard --logdir 'path to log_dir'
Le formateur déverse l'audio et les alignements toutes les 2000 étapes par défaut. Vous pouvez les trouver dans tacotron/ckpt/ .
python3 test.py --interactive --plot --model_name 500000
python3 test.py --plot --model_name 500000 --test_file_path ./data/test_transcripts.txt
Crédits à Ryuichi Yamamoto pour une merveilleuse mise en œuvre en pytorch de Tacotron, sur laquelle ce travail est principalement basé. Ce travail est également inspiré par la mise en œuvre de Pytorch de Nvidia Tacotron 2.


