TTS Tacotron Pytorch
1.0.0
Реализация Pytorch сети синтеза речи Google.
Эта реализация также включает в себя чувствительное внимание на местоположение и функции стоп-тона от Tacotron 2.
Кроме того, модель обучается на наборе данных речевых данных LJ с предоставленной обученной моделью.
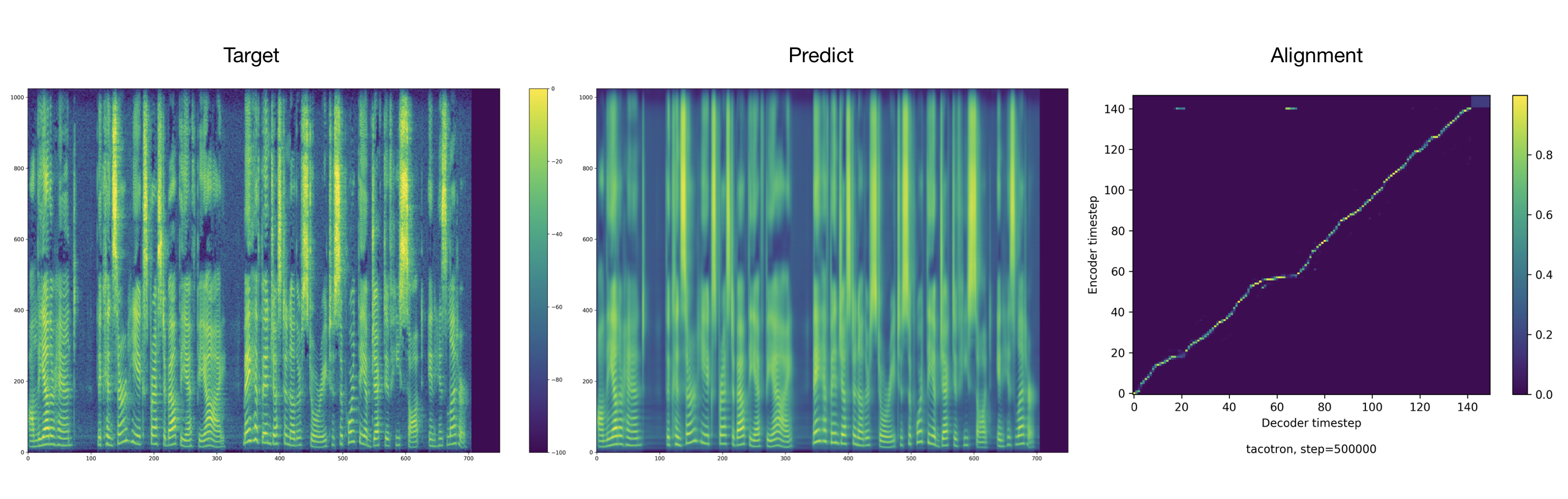
Образцы аудио можно найти в каталоге результатов.
Эта реализация основана на r9y9/tacotron_pytorch, основные различия:
Кроме того, некоторые отличия от исходной такотронной бумаги:
Качество звука пока не так хорошо, как демонстрация Google, но, надеюсь, в конце концов он улучшится. Приглашаются запросы на вытягивание!
git clone [email protected]:andi611/Tacotron-Pytorch.gitcd Tacotron-PytorchУстановите Python 3.
Установите последнюю версию Pytorch в соответствии с вашей платформой. Для лучшей производительности установите с помощью поддержки GPU (CUDA), если он является жизнеспособной. Этот код работает с Pytorch 0,4 и позже.
Установить требования:
pip3 install -r requirements.txt
Предупреждение: вам нужно установить факел в зависимости от вашей платформы. Здесь перечислите версию Pytorch, используемая при создании этого проекта.
Загрузите набор данных речи LJ.
Вы можете использовать другие наборы данных, если конвертируете их в правильный формат. См. Training_data.md для получения дополнительной информации.
Распаковать набор данных в ~/Tacotron-Pytorch/data
После распаковки ваше дерево должно выглядеть так для речи LJ:
|- Tacotron-Pytorch
|- data
|- LJSpeech-1.1
|- metadata.csv
|- wavs
Предварительно обрабатывать набор данных речи LJ и сделать готовые к модели мета-файлы с использованием preprocess.py:
python3 preprocess.py --mode make
После предварительной обработки ваше дерево будет выглядеть так:
|- Tacotron-Pytorch
|- data
|- LJSpeech-1.1 (The downloaded dataset)
|- metadata.csv
|- wavs
|- meta (generate by preprocessing)
|- meta_text.txt
|- meta_mel_xxxxx.npy ...
|- meta_spec_xxxxx.npy ...
|- test_transcripts.txt (provided)
Обучить модель с помощью train.py
python3 train.py --ckpt_dir ckpt/ --log_dir log/
Восстановите обучение с предыдущей контрольной точки:
python3 train.py --ckpt_dir ckpt/ --log_dir log/ --model_name 500000
Настраиваемые гиперпараметры находятся в config.py.
Вы можете настроить эти параметры и настройки, редактируя файл, для речи рекомендуется гиперпараметры по умолчанию.
Мониторинг с помощью Tensorboard (необязательно)
tensorboard --logdir 'path to log_dir'
Тренер сдает аудио и выравнивания каждые 2000 шагов по умолчанию. Вы можете найти их в tacotron/ckpt/ .
python3 test.py --interactive --plot --model_name 500000
python3 test.py --plot --model_name 500000 --test_file_path ./data/test_transcripts.txt
Кредиты Рюичи Ямамото за замечательную внедрение такотрона Pytorch, на которой эта работа в основном основана. Эта работа также вдохновлена реализацией Nvidia Tacotron 2 Pytorch.


