TTS Tacotron Pytorch
1.0.0
Eine Pytorch -Implementierung des Tacotron -Sprachsynthese -Netzwerks von Google.
Diese Implementierung umfasst auch die ortsempfindliche Aufmerksamkeit und die Stop-Token -Merkmale von Tacotron 2.
Darüber hinaus wird das Modell auf dem LJ -Sprachdatensatz mit geschultem Modell ausgebildet.
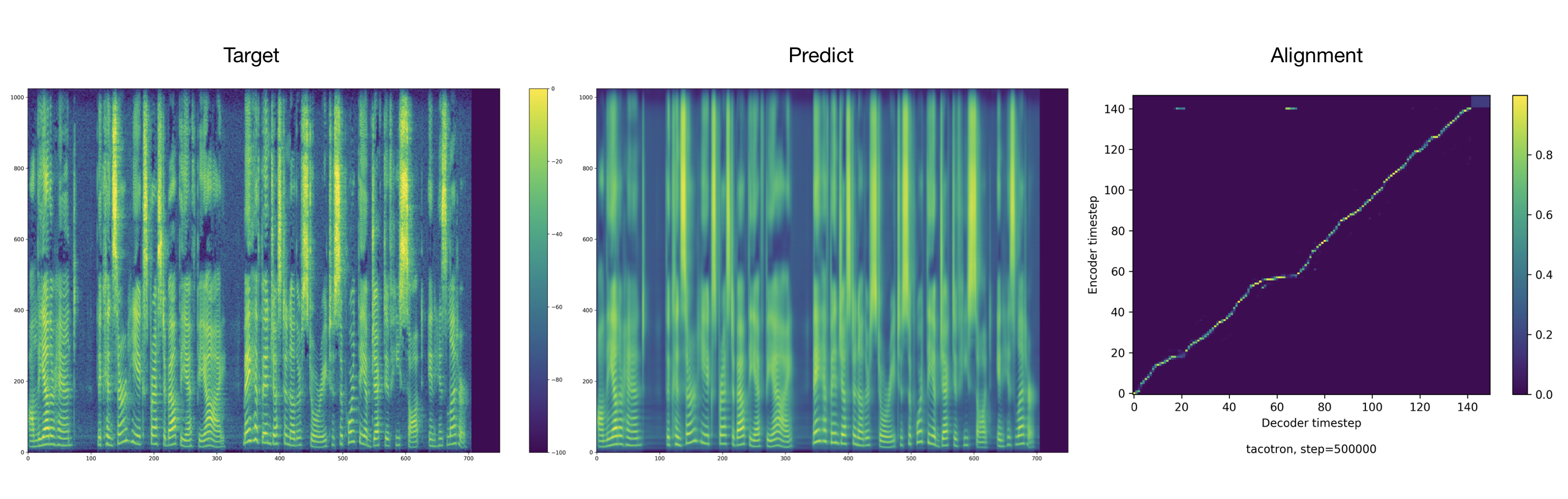
Audioproben finden Sie im Ergebnisverzeichnis.
Diese Implementierung basiert auf R9Y9/tacotron_pytorch. Die Hauptunterschiede sind:
Darüber hinaus sind einige Unterschiede zum ursprünglichen Tacotronpapier::
Audioqualität ist noch nicht so gut wie die Demo von Google, aber hoffentlich wird sie sich irgendwann verbessern. Pull -Anfragen sind willkommen!
git clone [email protected]:andi611/Tacotron-Pytorch.gitcd Tacotron-PytorchInstallieren Sie Python 3.
Installieren Sie die neueste Version von Pytorch gemäß Ihrer Plattform. Um eine bessere Leistung zu erzielen, installieren Sie bei der GPU -Unterstützung (CUDA), wenn sie lebensfähig sind. Dieser Code funktioniert mit Pytorch 0.4 und später.
Anforderungen installieren:
pip3 install -r requirements.txt
WARNUNG: Sie müssen den Torch je nach Plattform installieren. Hier finden Sie die Pytorch -Version, die bei der Erstellung verwendet wurde. Dieses Projekt wurde erstellt.
Laden Sie den LJ -Sprachdatensatz herunter.
Sie können andere Datensätze verwenden, wenn Sie sie in das richtige Format konvertieren. Weitere Informationen finden Sie unter Training_data.md.
Packen Sie den Datensatz in ~/Tacotron-Pytorch/data aus
Nach dem Auspacken sollte Ihr Baum für die LJ -Rede so aussehen:
|- Tacotron-Pytorch
|- data
|- LJSpeech-1.1
|- metadata.csv
|- wavs
Preprozess des LJ-Sprachdatensatzes und erstellen Sie mit Precess.py modellbereitete Meta-Dateien:
python3 preprocess.py --mode make
Nach der Vorverarbeitung sieht Ihr Baum wie folgt aus:
|- Tacotron-Pytorch
|- data
|- LJSpeech-1.1 (The downloaded dataset)
|- metadata.csv
|- wavs
|- meta (generate by preprocessing)
|- meta_text.txt
|- meta_mel_xxxxx.npy ...
|- meta_spec_xxxxx.npy ...
|- test_transcripts.txt (provided)
Trainieren Sie ein Modell mit Train.py
python3 train.py --ckpt_dir ckpt/ --log_dir log/
Stellen Sie das Training von einem vorherigen Kontrollpunkt aus:
python3 train.py --ckpt_dir ckpt/ --log_dir log/ --model_name 500000
Einstellbare Hyperparameter finden Sie in config.py.
Sie können diese Parameter anpassen und einstellen, indem Sie die Datei bearbeiten. Die Standard -Hyperparameter werden für die LJ -Sprache empfohlen.
Überwachen Sie mit Tensorboard (optional)
tensorboard --logdir 'path to log_dir'
Der Trainer entfällt standardmäßig Audio und Ausrichtungen alle 2000 Schritte. Sie finden diese in tacotron/ckpt/ .
python3 test.py --interactive --plot --model_name 500000
python3 test.py --plot --model_name 500000 --test_file_path ./data/test_transcripts.txt
Credits an Ryuichi Yamamoto für eine wunderbare Pytorch -Implementierung von Tacotron, auf der diese Arbeit hauptsächlich basiert. Diese Arbeit ist auch von der Tacotron 2 -Pytorch -Implementierung von Nvidia inspiriert.


