TTS Tacotron Pytorch
1.0.0
Googleのタコトロン音声合成ネットワークのPytorch実装。
この実装には、場所に敏感な注意とタコトロン2の停止トークン機能も含まれます。
さらに、モデルはLJ音声データセットでトレーニングされ、訓練されたモデルが提供されます。
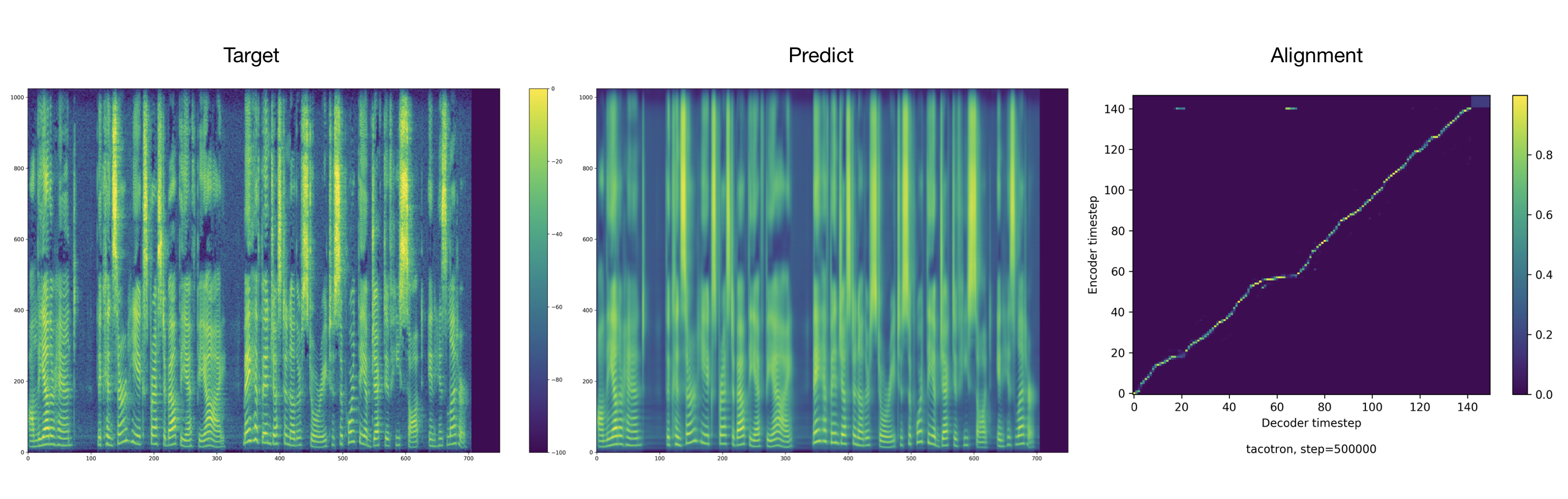
オーディオサンプルは、結果ディレクトリにあります。
この実装はR9Y9/Tacotron_Pytorchに基づいています。主な違いは次のとおりです。
さらに、元のタコトロン紙とのいくつかの違いは次のとおりです。
オーディオの品質はまだGoogleのデモほど良くありませんが、最終的に改善されることを願っています。プルリクエストは大歓迎です!
git clone [email protected]:andi611/Tacotron-Pytorch.gitcd Tacotron-PytorchPython 3をインストールします。
プラットフォームに応じて、 Pytorchの最新バージョンをインストールします。パフォーマンスを向上させるには、実行可能な場合はGPUサポート(CUDA)でインストールします。このコードは、Pytorch 0.4以降で動作します。
要件をインストールする:
pip3 install -r requirements.txt
警告:プラットフォームに応じてトーチをインストールする必要があります。ここに、このプロジェクトが構築されたときに使用されるPytorchバージョンをリストします。
LJスピーチデータセットをダウンロードします。
他のデータセットを適切な形式に変換する場合は、他のデータセットを使用できます。詳細については、training_data.mdを参照してください。
データセットを~/Tacotron-Pytorch/dataに解除します
開梱後、LJのスピーチのためにツリーは次のようになるはずです:
|- Tacotron-Pytorch
|- data
|- LJSpeech-1.1
|- metadata.csv
|- wavs
PREPROCESS.pyを使用して、LJスピーチデータセットを事前に処理し、モデル対応メタファイルを作成します:
python3 preprocess.py --mode make
前処理後、あなたの木は次のようになります:
|- Tacotron-Pytorch
|- data
|- LJSpeech-1.1 (The downloaded dataset)
|- metadata.csv
|- wavs
|- meta (generate by preprocessing)
|- meta_text.txt
|- meta_mel_xxxxx.npy ...
|- meta_spec_xxxxx.npy ...
|- test_transcripts.txt (provided)
train.pyを使用してモデルをトレーニングします
python3 train.py --ckpt_dir ckpt/ --log_dir log/
前のチェックポイントからトレーニングを復元します:
python3 train.py --ckpt_dir ckpt/ --log_dir log/ --model_name 500000
調整可能なハイパーパラメーターは、config.pyにあります。
これらのパラメーターと設定を調整し、ファイルを編集することで、デフォルトのハイパーパラメーターをLJスピーチに推奨します。
テンソルボードで監視する(オプション)
tensorboard --logdir 'path to log_dir'
トレーナーは、デフォルトで2000ステップごとにオーディオとアライメントをダンプします。これらはtacotron/ckpt/で見つけることができます。
python3 test.py --interactive --plot --model_name 500000
python3 test.py --plot --model_name 500000 --test_file_path ./data/test_transcripts.txt
この作業は主に基づいているタコトロンの素晴らしいピトルチの実装について、ヤマモト龍子のクレジット。この作品は、NvidiaのTacotron 2 Pytorchの実装にも触発されています。


