TTS Tacotron Pytorch
1.0.0
Implementasi Pytorch dari Jaringan Sintesis Pidato Tacotron Google.
Implementasi ini juga mencakup perhatian yang peka terhadap lokasi dan fitur stop token dari Tacotron 2.
Selain itu, model ini dilatih pada dataset ucapan LJ, dengan model terlatih disediakan.
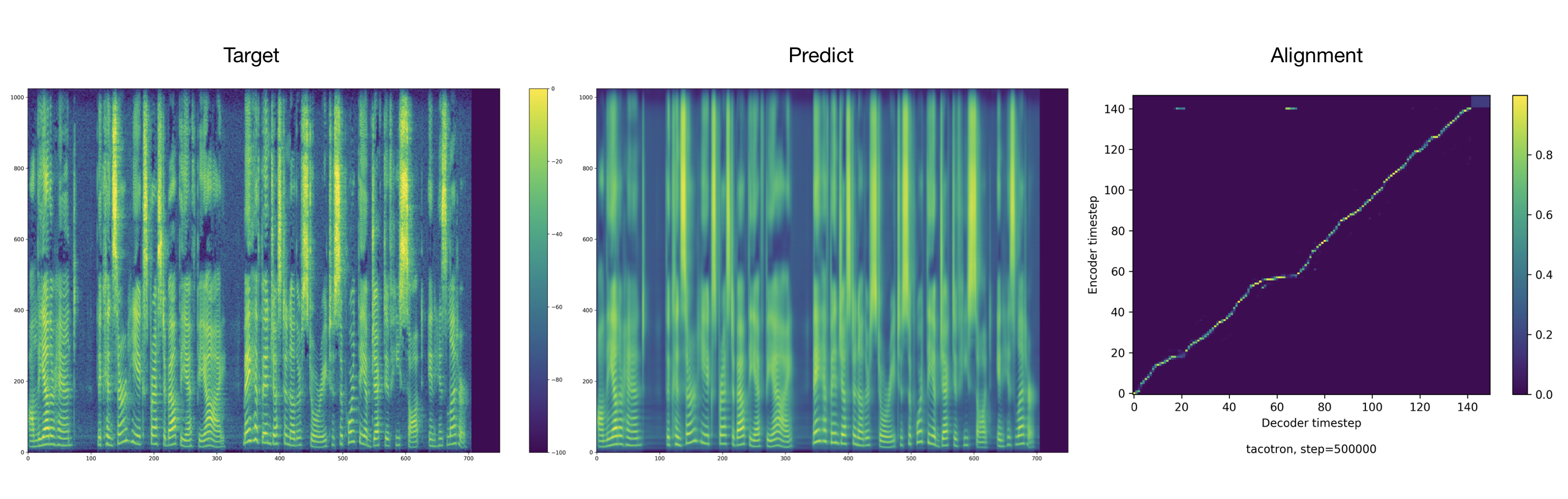
Sampel audio dapat ditemukan di direktori hasil.
Implementasi ini didasarkan pada r9y9/tacotron_pytorch, perbedaan utamanya adalah:
Selain itu, beberapa perbedaan dari kertas tacotron asli adalah:
Kualitas audio belum sebagus demo Google, tapi semoga akhirnya akan membaik. Permintaan tarik dipersilakan!
git clone [email protected]:andi611/Tacotron-Pytorch.gitcd Tacotron-PytorchPasang Python 3.
Instal versi terbaru Pytorch sesuai dengan platform Anda. Untuk kinerja yang lebih baik, instal dengan dukungan GPU (CUDA) jika layak. Kode ini berfungsi dengan Pytorch 0.4 dan yang lebih baru.
Instal Persyaratan:
pip3 install -r requirements.txt
Peringatan: Anda perlu menginstal obor tergantung pada platform Anda. Di sini daftar versi Pytorch yang digunakan saat dibangun proyek ini dibangun.
Unduh dataset LJ Speech.
Anda dapat menggunakan set data lain jika Anda mengonversinya ke format yang tepat. Lihat pelatihan_data.md untuk info lebih lanjut.
Buka kumpulan dataset menjadi ~/Tacotron-Pytorch/data
Setelah membongkar, pohon Anda harus terlihat seperti ini untuk pidato LJ:
|- Tacotron-Pytorch
|- data
|- LJSpeech-1.1
|- metadata.csv
|- wavs
Preprocess The LJ Speech Dataset dan buat file meta siap-model menggunakan preprocess.py:
python3 preprocess.py --mode make
Setelah preprocessing, pohon Anda akan terlihat seperti ini:
|- Tacotron-Pytorch
|- data
|- LJSpeech-1.1 (The downloaded dataset)
|- metadata.csv
|- wavs
|- meta (generate by preprocessing)
|- meta_text.txt
|- meta_mel_xxxxx.npy ...
|- meta_spec_xxxxx.npy ...
|- test_transcripts.txt (provided)
Latih model menggunakan train.py
python3 train.py --ckpt_dir ckpt/ --log_dir log/
Kembalikan pelatihan dari pos pemeriksaan sebelumnya:
python3 train.py --ckpt_dir ckpt/ --log_dir log/ --model_name 500000
Hyperparameters Tunable ditemukan di config.py.
Anda dapat menyesuaikan parameter ini dan pengaturan dengan mengedit file, hyperparameter default direkomendasikan untuk pidato LJ.
Monitor dengan Tensorboard (Opsional)
tensorboard --logdir 'path to log_dir'
Pelatih membuang audio dan keselarasan setiap 2000 langkah secara default. Anda dapat menemukannya di tacotron/ckpt/ .
python3 test.py --interactive --plot --model_name 500000
python3 test.py --plot --model_name 500000 --test_file_path ./data/test_transcripts.txt
Kredit untuk Ryuichi Yamamoto untuk implementasi Pytorch yang indah dari Tacotron, yang sebagian besar didasarkan pada karya ini. Pekerjaan ini juga terinspirasi oleh implementasi Pytorch Tacotron 2 NVIDIA.


