TTS Tacotron Pytorch
1.0.0
Google的Tacotron语音合成网络的Pytorch实现。
该实现还包括对位置敏感的关注以及Tacotron 2的停止令牌功能。
此外,使用训练的模型在LJ语音数据集上进行了培训。
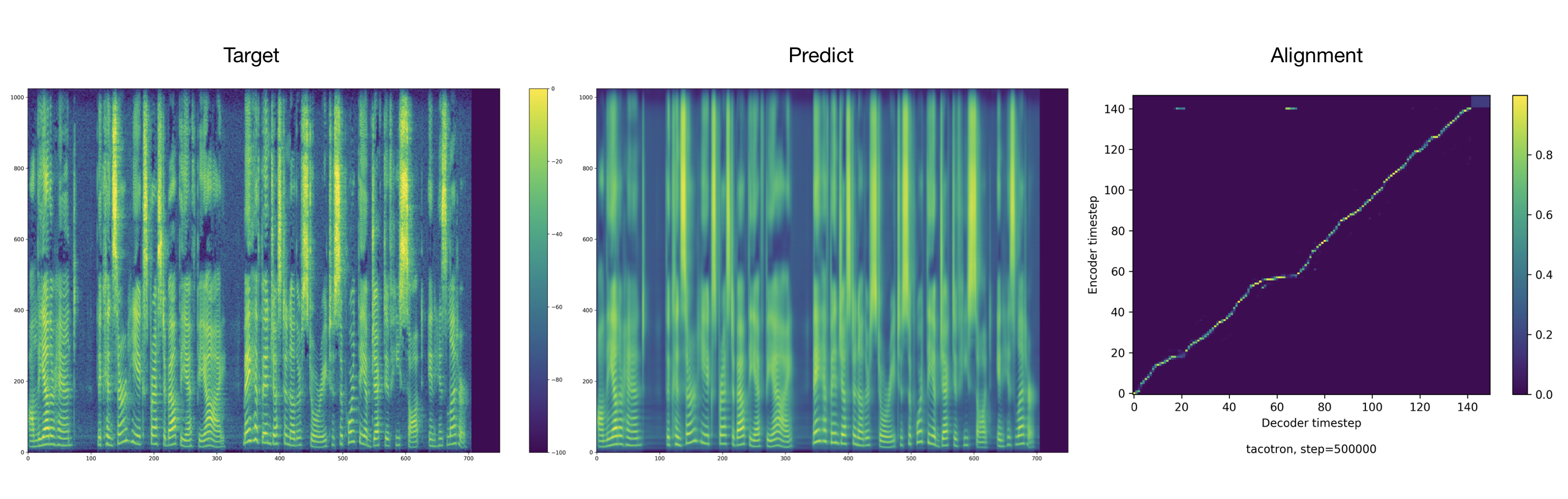
可以在结果目录中找到音频样本。
该实现基于R9Y9/Tacotron_pytorch,主要区别是:
此外,与原始的Tacotron纸有一些差异是:
音频质量还不如Google的演示,但希望最终会有所改善。欢迎拉动请求!
git clone [email protected]:andi611/Tacotron-Pytorch.gitcd Tacotron-Pytorch安装Python 3。
根据您的平台安装最新版本的Pytorch 。为了获得更好的性能,请在可行的情况下使用GPU支持(CUDA)安装。该代码可与Pytorch 0.4及更高版本一起使用。
安装要求:
pip3 install -r requirements.txt
警告:您需要根据平台安装火炬。这里列出构建此项目时使用的Pytorch版本。
下载LJ语音数据集。
如果将其他数据集转换为正确的格式,则可以使用其他数据集。有关更多信息,请参见triaze_data.md。
将数据集解开为~/Tacotron-Pytorch/data
解开包装后,您的树应该像这样的LJ演讲:
|- Tacotron-Pytorch
|- data
|- LJSpeech-1.1
|- metadata.csv
|- wavs
预处理LJ语音数据集,并使用Preprocess.py制作模型的元文件:
python3 preprocess.py --mode make
预处理后,您的树看起来像这样:
|- Tacotron-Pytorch
|- data
|- LJSpeech-1.1 (The downloaded dataset)
|- metadata.csv
|- wavs
|- meta (generate by preprocessing)
|- meta_text.txt
|- meta_mel_xxxxx.npy ...
|- meta_spec_xxxxx.npy ...
|- test_transcripts.txt (provided)
使用train.py训练模型
python3 train.py --ckpt_dir ckpt/ --log_dir log/
从以前的检查站恢复培训:
python3 train.py --ckpt_dir ckpt/ --log_dir log/ --model_name 500000
可调超参数可在config.py中找到。
您可以通过编辑文件来调整这些参数并设置设置,建议使用默认的超参数用于LJ语音。
用张板监视(可选)
tensorboard --logdir 'path to log_dir'
培训师默认情况下每2000个步骤一次倾倒音频和对齐。您可以在tacotron/ckpt/中找到这些。
python3 test.py --interactive --plot --model_name 500000
python3 test.py --plot --model_name 500000 --test_file_path ./data/test_transcripts.txt
Yamamoto Ryuichi的归功于Tacotron的出色pytorch实施,这项工作主要基于。这项工作还受到NVIDIA的Tacotron 2 Pytorch实施的启发。


