TTS Tacotron Pytorch
1.0.0
A Pytorch implementation of Google's Tacotron speech synthesis network.
This implementation also includes the Location-Sensitive Attention and the Stop Token features from Tacotron 2.
Furthermore, the model is trained on the LJ Speech dataset, with trained model provided.
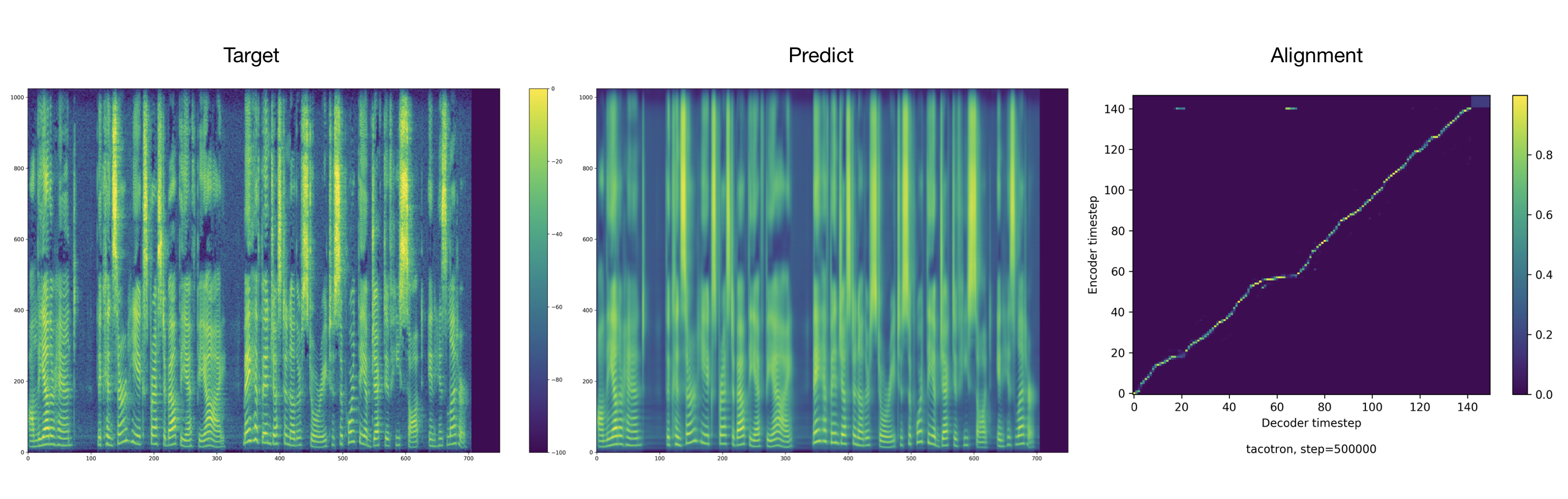
Audio samples can be found in the result directory.
This implementation is based on r9y9/tacotron_pytorch, the main differences are:
Furthermore, some differences from the original Tacotron paper are:
Audio quality isn't as good as Google's demo yet, but hopefully it will improve eventually. Pull requests are welcome!
git clone [email protected]:andi611/Tacotron-Pytorch.gitcd Tacotron-PytorchInstall Python 3.
Install the latest version of Pytorch according to your platform. For better performance, install with GPU support (CUDA) if viable. This code works with Pytorch 0.4 and later.
Install requirements:
pip3 install -r requirements.txt
Warning: you need to install torch depending on your platform. Here list the Pytorch version used when built this project was built.
Download the LJ Speech dataset.
You can use other datasets if you convert them to the right format. See TRAINING_DATA.md for more info.
Unpack the dataset into ~/Tacotron-Pytorch/data
After unpacking, your tree should look like this for LJ Speech:
|- Tacotron-Pytorch
|- data
|- LJSpeech-1.1
|- metadata.csv
|- wavs
Preprocess the LJ Speech dataset and make model-ready meta files using preprocess.py:
python3 preprocess.py --mode make
After preprocessing, your tree will look like this:
|- Tacotron-Pytorch
|- data
|- LJSpeech-1.1 (The downloaded dataset)
|- metadata.csv
|- wavs
|- meta (generate by preprocessing)
|- meta_text.txt
|- meta_mel_xxxxx.npy ...
|- meta_spec_xxxxx.npy ...
|- test_transcripts.txt (provided)
Train a model using train.py
python3 train.py --ckpt_dir ckpt/ --log_dir log/
Restore training from a previous checkpoint:
python3 train.py --ckpt_dir ckpt/ --log_dir log/ --model_name 500000
Tunable hyperparameters are found in config.py.
You can adjust these parameters and setting by editing the file, the default hyperparameters are recommended for LJ Speech.
Monitor with Tensorboard (OPTIONAL)
tensorboard --logdir 'path to log_dir'
The trainer dumps audio and alignments every 2000 steps by default. You can find these in tacotron/ckpt/.
python3 test.py --interactive --plot --model_name 500000
python3 test.py --plot --model_name 500000 --test_file_path ./data/test_transcripts.txt
Credits to Ryuichi Yamamoto for a wonderful Pytorch implementation of Tacotron, which this work is mainly based on. This work is also inspired by NVIDIA's Tacotron 2 PyTorch implementation.


