Narrator
1.0.0
====================================================
該API和服務的創建是為了幫助內容創建者獲得AI生成的聽覺描述,以使他們可以使用這些場景和圖像,以使其內容更容易為視力障礙的人使用。
敘述者API使用Pytorch中開發的兩個CNN-RNN神經網絡為提供的圖像和視頻生成音頻描述:1)基於展示和講述網絡的文本描述網絡的圖像,以及2)將此網絡擴展到文本描述中。視頻描述網絡還可以用於在視頻中每個場景中生成描述。
敘述者的整體弧結可以在這裡看到: 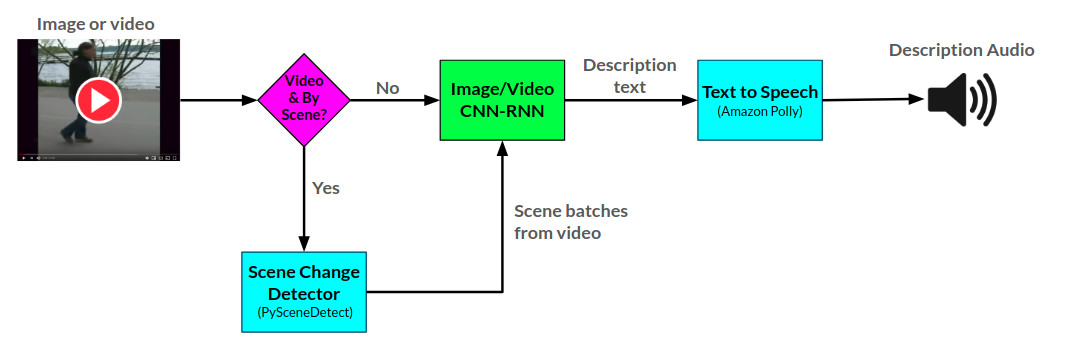
圖像描述模型體系結構可以在此處看到: 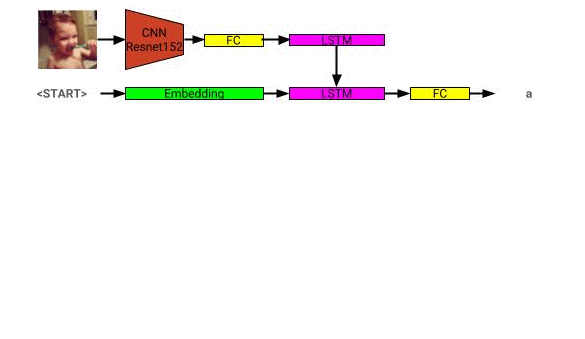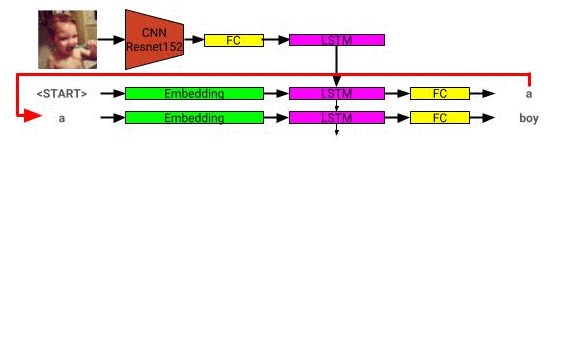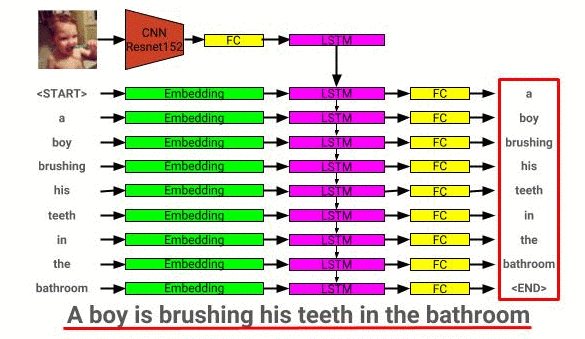
視頻說明模型體系結構可以在此處看到: 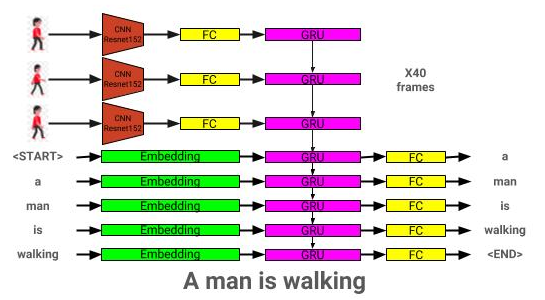
目前,敘述者以兩種方式提供敘述者:1)當前在AWS上託管並通過網站提供的燒瓶Web應用程序,以及2)獨立的API:Nornator.py。網站使用的示例可以在網站上看到,並且可以在筆記本/敘述者用法示例中看到使用API的示例。
敘述者API使用Amazon Polly從文本中生成音頻描述,並使用Pyscenedect檢測視頻中的場景更改。
圖像描述網絡是使用可可2014數據集訓練的。
視頻描述網絡是使用MSR-VTT數據集訓練的。
當前最佳的預培訓圖像描述模型可以從此處下載。
當前最佳的預訓練視頻說明模型可以從此處下載。
將這些模型放在模型目錄中。
├── LICENSE
├── README.md <- The top-level README for developers using this project.
├── data
│ ├── interim <- Intermediate data that has been transformed.
│ ├── processed <- The final, canonical data sets for modeling.
│ └── raw <- The original, immutable data dump.
│
├── models <- Location to store trained models to be used by Narrator
│
├── notebooks <- Example Jupyter notebook + notebooks for validation
│ ├── Narrator-Usage-Examples.ipynb <- Examples of how to use Narrator independently of the web interface
│ ├── Image-Captioner-Validation.ipynb <- Notebook for validating image captioner model
│ ├── Video-Captioner-Validation.ipynb <- Notebook for validating video captioner model
│ └── Data-Analysis.ipynb <- Notebook for analyzing image/data analysis
│
├── results <- Directory to store results
│
├── samples <- Image and video samples to use with Narrator.
│
├── src <- Source code for use in this project.
│ ├── __init__.py <- Makes src a Python module
│ ├── ic_trainer.py <- Module for training image description model
│ ├── ic_validate.py <- Module for evaluating image description model
│ ├── Narrator.py <- Python class for deploying trained image/video description models
│ ├── vc_trainer.py <- Module for training video description model
│ ├── vc_validate.py <- Module for evaluating video description model
│ │
│ ├── models <- Scripts to prepare COCO/MSR-VTT datasets for training
│ │ ├── EncoderCNN.py <-- Pre-trained CNN PyTorch model
│ │ ├── ImageCaptioner.py <- Image Captioner Show-and-tell PyTorch Model
│ │ ├── VideoCaptioner.py <- Video Captioner PyTorch Model
│ │ ├── S2VTCaptioner.py <- S2VT PyTorch PyTorch Model
│ │ ├── YoloObjectDetector.py <- Wrapper for yolo submodule
│ │ └── pytorch-yolo-v3 <- git submodule: https://github.com/ayooshkathuria/pytorch-yolo-v3
│ │
│ ├── prepare <- Scripts to prepare COCO/MSR-VTT datasets for training
│ │ ├── build_coco_vocabulary.py
│ │ ├── build_msrvtt_vocabulary.py
│ │ ├── make_coco_dataset.py
│ │ ├── make_msrvtt_dataset.py
│ │ ├── preprocess_coco_images.py
│ │ ├── preprocess_coco_objects.py
│ │ ├── preprocess_msrvtt_objects.py
│ │ └── preprocess_msrvtt_videos.py
│ │
│ └── utils <- Assistance classes and modules
│ ├── create_transformer.py <- Create image transformer with torchvision
│ ├── TTS.py <- Amazon Polly wrapper
│ ├── ImageDataloader.py <- Torch dataloader for the COCO dataset
│ ├── VideoDataloader.py <- Torch dataloader for the MSR-VTT dataset
│ └── Vocabulary.py <- Vocabulary class
│
│
└── web <- Scripts/templates related to deploying web app with Flask
依賴項可以使用:
pip install -r requirements.txt
| 建築學 | CNN | 初始化 | 貪婪的 | 梁= 3 |
|---|---|---|---|---|
| LSTM(嵌入:256) | RESNET152 | 隨機的 | 0.123 | 0.132 |
| gru(嵌入:256) | RESNET152 | 隨機的 | 0.122 | 0.131 |
| LSTM(嵌入:256) | VGG16 | 隨機的 | 0.108 | 0.117 |
| 建築學 | CNN | 初始化 | 貪婪的 | 梁= 3 |
|---|---|---|---|---|
| gru(嵌入:256) | RESNET152 | 隨機的 | 0.317 | 0.351 |
| LSTM(嵌入:256) | RESNET152 | 隨機的 | 0.305 | 0.320 |
| LSTM(嵌入:256) | VGG16 | 隨機的 | 0.283 | 0.318 |
| LSTM(嵌入:512) | RESNET152 | 隨機的 | 0.270 | 0.317 |
| LSTM(嵌入:256) | RESNET152 | 預訓練的可可 | 0.278 | 0.310 |
本節將展示如何訓練自己的圖像描述模型。
首先,需要預處理可可的數據集圖像和標題進行培訓。
python3 src/prepare/make_coco_dataset.py
--coco_path <path_to_cocoapi>
--interim_results_path <interim_results_path>
--results_path <final_results_path>
-coco_path:通往可可api路徑的路徑(可以從此處下載)
-interm_results_path:存儲臨時結果的路徑(默認:數據/臨時/)
-Results_path:存儲最終結果的路徑(默認:數據/處理/)
這還將組合字幕數據集存儲在<coco_path>/annotations/coco_captions.csv中。
python3 src/prepare/build_coco_vocabulary.py
--coco_path <path_to_cocoapi>
--vocab_path <desired_path_of_vocab>
--threshold <min_word_threshold>
--sets <coco_sets_to_include>
-coco_path:通往可可api路徑的路徑(可以從此處下載)
-Vocab_path:存儲可可詞彙的路徑(默認到數據/padected/coco_vocab.pkl)
- 閾值:添加到詞彙中的最小單詞發生(默認值:5)
- 集合:可可套裝以包括在詞彙結構中(默認:'Train2014','Train2017')
python3 src/prepare/preprocess_coco_images.py
--model <base_model_type>
--dir <path_to_images_to_encode>
--continue_preprocessing <continue_preprocessing?>
- 模型:用於預處理的基本CNN模型(選項:['resnet18','resnet50','resnet152','vgg11','vgg11_bn','vgg16','vgg16','vgg16_bn','vgg16_bn','vgg19'vgg19'vgg19'vgg19'''vgg19_bn'bn's speree'' 'densenet121','densenet201','inpection']))
- dir:使用選定模型編碼可可圖像的路徑
-Continue_processing:目錄中的剩餘圖像
編碼的文件將放置在DIR中。
python3 src/ic_trainer.py
--models_path <path_to_store_models>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_coco_vocab>
--captions_path <path_to_coco_captions_file>
--images_path <path_to_coco_image_embeddings>
--lr <learning_rate>
--val_interval <epoch_interval_to_validate_models>
--save_interval <epoch_inteval_to_save_model_checkpoints>
--num_epochs <epochs_to_train_for>
--initial_checkpoint_file <starting_model_checkpoint>
--version <model_version_number>
--batch_size <batch_size>
--coco_set <coco_set>
--load_features <load_or_construct_image_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_image_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-models_path:存儲最終模型的路徑(默認:型號/)
- beam_size:驗證的光束大小(默認:3)
-vocab_path:可可詞詞的路徑(默認:data/pasgented/coco_vocab.pkl)
-captions_path:通往可可標題的路徑(默認:os.environ ['home'] +'/programs/cocoapi/annotations/coco_captions.csv')
-images_path:通往可可的路徑(默認:os.environ ['home'] +'/database/coco/images/')
-lr:使用的學習率(默認:0.001)
-val_interval:驗證時期頻率(默認值:10)
-save_interval:保存檢查點頻率(默認值:10)
-num_epochs:要訓練的時期數(默認值:1000)
-initial_checkpoint_file:檢查點要從(默認:無)開始培訓
- Version:型號版本號(默認:11)
-batch_size:批處理大小(默認:64)
-coco_set:使用(默認:2014)訓練的可可數據集
-load_features:加載或構造圖像嵌入的選項(默認:true)
-load_captions:加載或構造字幕嵌入的選項(默認:true)
- 預計:在培訓之前將數據預加載到系統內存的選項(默認:true)
-base_model:用於預處理的基本CNN模型(選項:['resnet18','resnet50','resnet152','vgg11','vgg11_bn','vgg1_bn','vgg16','vgg16_bn',vgg16_bn','vgg19'vgg19'vgg19',vgg19' 'densenet121','densenet201','inpection']))
-embedding_size:圖像嵌入的大小(默認:2048)
-embed_size:RNN輸入的大小(默認:256)
-hidden_size:RNN隱藏層的大小(默認:512)
-rnn_type:rnn類型(默認:'lstm')
python3 src/ic_validate.py
--model_path <path_to_trained_ic_model>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_coco_vocab>
--captions_path <path_to_coco_captions_file>
--images_path <path_to_coco_image_embeddings>
--batch_size <batch_size>
--coco_set <coco_set>
--load_features <load_or_construct_image_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_image_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-Model_path:訓練IC模型的路徑
- beam_size:驗證的光束尺寸
-vocab_path:可可詞詞的路徑(默認:data/pasgented/coco_vocab.pkl)
-captions_path:通往可可標題的路徑(默認:os.environ ['home'] +'/programs/cocoapi/annotations/coco_captions.csv')
-images_path:通往可可圖像的路徑(默認:os.environ ['home'] +'/database/coco/images/')
-batch_size:批處理大小(默認:64)
-coco_set:使用(默認:2014)訓練的可可數據集
-load_features:加載或構造圖像嵌入的選項(默認:true)
-load_captions:加載或構造字幕嵌入的選項(默認:true)
- 預計:在培訓之前將數據預加載到系統內存的選項(默認:true)
-base_model:用於預處理的基本CNN模型(選項:['resnet18','resnet50','resnet152','vgg11','vgg11_bn','vgg1_bn','vgg16','vgg16_bn',vgg16_bn','vgg19'vgg19'vgg19',vgg19' 'densenet121','densenet201','inpection']))
-embedding_size:圖像嵌入的大小(默認:2048)
-embed_size:RNN輸入的大小(默認:256)
-hidden_size:RNN隱藏層的大小(默認:512)
-rnn_type:rnn類型(默認:'lstm')
本節將展示如何訓練自己的視頻描述模型。
首先,需要預處理MSR-VTT數據集視頻和標題進行培訓。
python3 src/prepare/make_msrvtt_dataset.py
--raw_data_path <path_to_raw_msrvtt_data>
--interim_data_path <path_to_store_interim_data>
--final_data_path <path_to_store_final_data>
--continue_converting <continue_conversion>
--train_pct <percentage_to_allocate_to_training_set>
--dev_pct <percentage_to_allocate_to_development_set>
-raw_data_path:RAW MSRVTT數據文件的路徑(默認值:'Data/raw/videodatainfo_2017_ustc.json')
-interim_data_path:存儲臨時結果的路徑(默認值:'data/intrim/')
-final_data_path:存儲最終結果的路徑(默認值:'data/processed/')
-Continue_converting:繼續轉換MSR-VTT數據集的路徑(默認:true)
-train_pct:用於培訓的數據集的百分比(默認:0.8)
-DEV_PCT:用於開發的數據集的百分比(默認:0.15)
python3 src/prepare/build_msrvtt_vocabulary.py
--captions_path <path_to_captions>
--vocab_path <desired_path_of_vocab>
--threshold <min_word_threshold>
--sets <coco_sets_to_include>
-coco_path: make_msrvtt_dataset.py生成的MSR-VTT字幕的路徑(默認:'data/processed/msrvtt_captions.csv')
-Vocab_path:存儲MSR-VTT詞彙的路徑(默認為數據/處理/msrvtt_vocab.pkl)
- 閾值:添加到詞彙中的最小單詞發生(默認值:5)
python3 src/prepare/preprocess_msrvtt_videos.py
--model <base_model_type>
--dir <path_to_images_to_encode>
--continue_preprocessing <continue_preprocessing?>
--resolution <CNN_input_resolution>
--num_frames <number_of_frames_to_encode>
--frames_interval <interval_between_frames>
--embedding_size <frame_embedding_size>
- 模型:用於預處理的基本CNN模型(選項:['resnet18','resnet50','resnet152','vgg11','vgg11_bn','vgg16','vgg16','vgg16_bn','vgg16_bn','vgg19'vgg19'vgg19'vgg19'''vgg19_bn'bn's speree'' 'densenet121','densenet201','inpection']))
- dir:使用選定模型進行編碼的MSR-VTT視頻路徑(默認:OS.Environ ['HOME'] +'/database/MSR-VTT/Train-Video/')
-Continue_processing:目錄中的剩餘視頻(默認:true)
- 分辨率:CNN輸入分辨率(默認:224)
-num_frames:編碼的幀數(默認值:40)
-frames_interval:幀之間的間隔(默認:1)
-embedding_size:CNN OUPUT分辨率(默認:2048)
編碼的文件將放置在DIR中。
python3 src/vc_trainer.py
--models_path <path_to_store_models>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_msrvtt_vocab>
--captions_path <path_to_msrvtt_captions_file>
--videos_path <path_to_msrvtt_video_embeddings>
--lr <learning_rate>
--val_interval <epoch_interval_to_validate_models>
--save_interval <epoch_inteval_to_save_model_checkpoints>
--num_epochs <epochs_to_train_for>
--initial_checkpoint_file <starting_model_checkpoint>
--version <model_version_number>
--batch_size <batch_size>
--load_features <load_or_construct_video_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_frame_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-models_path:存儲最終模型的路徑(默認:型號/)
- beam_size:驗證的光束大小(默認:3)
-Vocab_path:通往MSR-VTT詞彙的路徑(默認:數據/processed/msrvtt_vocab.pkl)
-captions_path:通往MSR-VTT字幕的路徑(默認:data/processed/msrvtt_captions.csv)
-videos_path:通往MSR-VTT視頻的路徑(默認:os.environ ['home'] +'/database/msr-vtt/train-video/')
-lr:使用的學習率(默認:0.001)
-val_interval:驗證時期頻率(默認值:10)
-save_interval:保存檢查點頻率(默認值:10)
-num_epochs:要訓練的時期數(默認值:1000)
-initial_checkpoint_file:檢查點要從(默認:無)開始培訓
- Version:型號版本號(默認:11)
-batch_size:批處理大小(默認:64)
-load_features:加載或構造視頻嵌入的選項(默認:true)
-load_captions:加載或構造字幕嵌入的選項(默認:true)
- 預計:在培訓之前將數據預加載到系統內存的選項(默認:true)
-base_model:用於預處理的基本CNN模型(選項:['resnet18','resnet50','resnet152','vgg11','vgg11_bn','vgg1_bn','vgg16','vgg16_bn',vgg16_bn','vgg19'vgg19'vgg19',vgg19' 'densenet121','densenet201','inpection']))
-embedding_size:框架嵌入的大小(默認:2048)
-embed_size:RNN輸入的大小(默認:256)
-hidden_size:RNN隱藏層的大小(默認:512)
-rnn_type:rnn類型(默認:'lstm')
python3 src/vc_validate.py
--model_path <path_to_trained_vc_model>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_msrvtt_vocab>
--captions_path <path_to_msrvtt_captions_file>
--videos_path <path_to_msrvtt_video_embeddings>
--batch_size <batch_size>
--load_features <load_or_construct_video_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_frame_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-model_path:訓練有素的視頻說明模型
- beam_size:驗證的光束尺寸
-Vocab_path:通往MSR-VTT詞彙的路徑(默認:數據/processed/msrvtt_vocab.pkl)
-captions_path:通往MSR-VTT字幕的路徑(默認:data/processed/msrvtt_captions.csv)
-videos_path:通往MSR-VTT視頻的路徑(默認:os.environ ['home'] +'/database/msr-vtt/train-video/')
-batch_size:批處理大小(默認:64)
-load_features:加載或構造視頻嵌入的選項(默認:true)
-load_captions:加載或構造字幕嵌入的選項(默認:true)
- 預計:在培訓之前將數據預加載到系統內存的選項(默認:true)
-base_model:用於預處理的基本CNN模型(選項:['resnet18','resnet50','resnet152','vgg11','vgg11_bn','vgg1_bn','vgg16','vgg16_bn',vgg16_bn','vgg19'vgg19'vgg19',vgg19' 'densenet121','densenet201','inpection']))
-embedding_size:框架嵌入的大小(默認:2048)
-embed_size:RNN輸入的大小(默認:256)
-hidden_size:RNN隱藏層的大小(默認:512)
-rnn_type:rnn類型(默認:'lstm')


