Narrator
1.0.0
===============================================.
Cet API et cet service ont été créés avec l'intention d'aider les créateurs de contenu à obtenir des descriptions auditives générées par l'IA des scènes et des images qu'ils peuvent utiliser pour rendre leur contenu plus accessible aux personnes ayant une déficience visuelle.
L'API du narrateur génère des descriptions audio pour les images et vidéos fournies à l'aide de deux réseaux de neurones CNN-RNN développés dans Pytorch: 1) une image à un réseau de description de texte basée sur le réseau Show-and-Tell, et 2) une extension de ce réseau en vidéo à la description du texte. Le réseau de description vidéo peut en outre être utilisé pour générer des descriptions par scène dans une vidéo.
L'architecture globale du narrateur peut être vue ici: 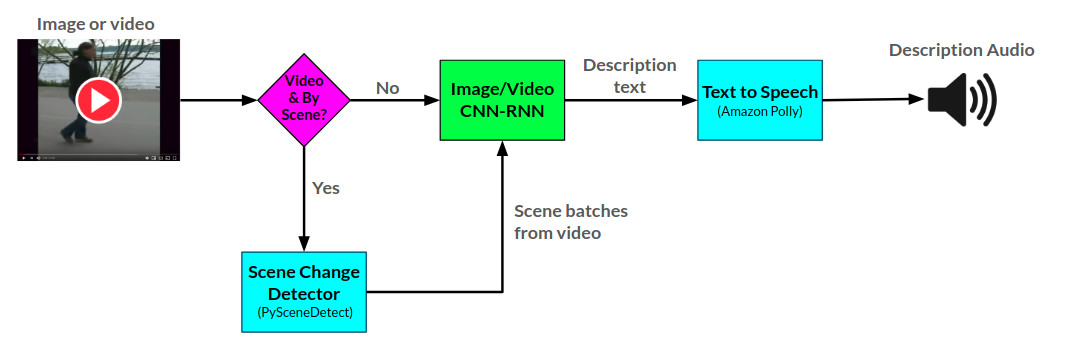
L'architecture du modèle de description de l'image peut être vue ici: 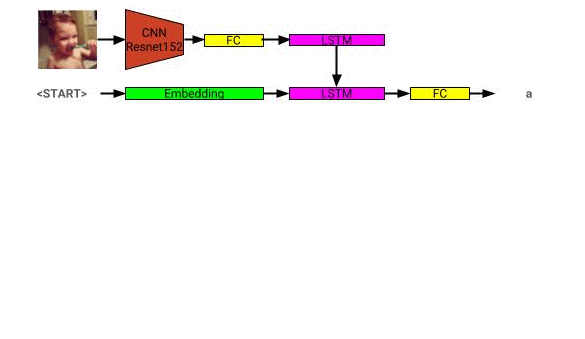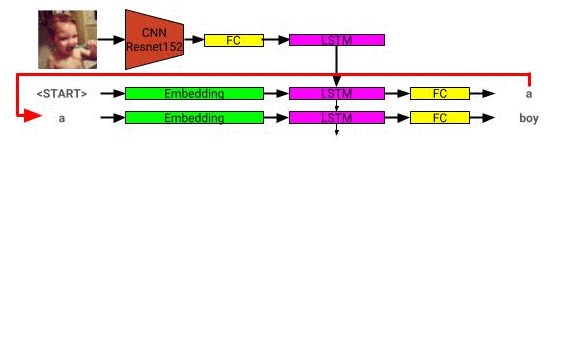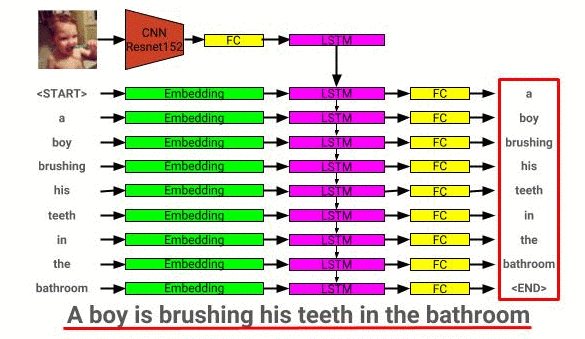
L'architecture du modèle de description vidéo peut être vue ici: 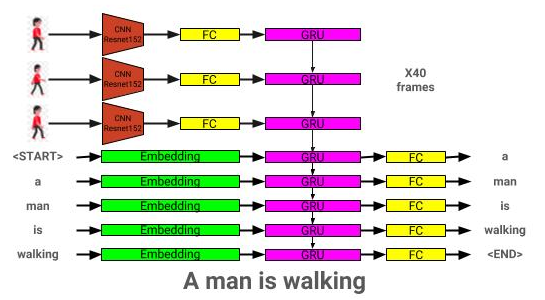
Le narrateur est actuellement servi de deux manières: 1) une application Web Flask actuellement hébergée sur AWS et servie via un site Web, et 2) une API autonome: narrator.py. Des exemples d'utilisation du site Web peuvent être vus sur le site Web, et des exemples d'utilisation de l'API peuvent être vus dans des cahiers / narrateur Exemples.ipynb.
L'API Narrator utilise Amazon Polly pour générer des descriptions audio à partir de texte, et pysceneDetect pour détecter les changements de scène dans une vidéo.
Le réseau de description d'image est formé à l'aide de l'ensemble de données CoCo 2014.
Le réseau de description vidéo est formé à l'aide de l'ensemble de données MSR-VTT.
Le modèle de description d'image pré-formé actuel peut être téléchargé à partir d'ici.
Le modèle de description vidéo pré-formé actuel peut être téléchargé à partir d'ici.
Placez ces modèles dans le répertoire des modèles.
├── LICENSE
├── README.md <- The top-level README for developers using this project.
├── data
│ ├── interim <- Intermediate data that has been transformed.
│ ├── processed <- The final, canonical data sets for modeling.
│ └── raw <- The original, immutable data dump.
│
├── models <- Location to store trained models to be used by Narrator
│
├── notebooks <- Example Jupyter notebook + notebooks for validation
│ ├── Narrator-Usage-Examples.ipynb <- Examples of how to use Narrator independently of the web interface
│ ├── Image-Captioner-Validation.ipynb <- Notebook for validating image captioner model
│ ├── Video-Captioner-Validation.ipynb <- Notebook for validating video captioner model
│ └── Data-Analysis.ipynb <- Notebook for analyzing image/data analysis
│
├── results <- Directory to store results
│
├── samples <- Image and video samples to use with Narrator.
│
├── src <- Source code for use in this project.
│ ├── __init__.py <- Makes src a Python module
│ ├── ic_trainer.py <- Module for training image description model
│ ├── ic_validate.py <- Module for evaluating image description model
│ ├── Narrator.py <- Python class for deploying trained image/video description models
│ ├── vc_trainer.py <- Module for training video description model
│ ├── vc_validate.py <- Module for evaluating video description model
│ │
│ ├── models <- Scripts to prepare COCO/MSR-VTT datasets for training
│ │ ├── EncoderCNN.py <-- Pre-trained CNN PyTorch model
│ │ ├── ImageCaptioner.py <- Image Captioner Show-and-tell PyTorch Model
│ │ ├── VideoCaptioner.py <- Video Captioner PyTorch Model
│ │ ├── S2VTCaptioner.py <- S2VT PyTorch PyTorch Model
│ │ ├── YoloObjectDetector.py <- Wrapper for yolo submodule
│ │ └── pytorch-yolo-v3 <- git submodule: https://github.com/ayooshkathuria/pytorch-yolo-v3
│ │
│ ├── prepare <- Scripts to prepare COCO/MSR-VTT datasets for training
│ │ ├── build_coco_vocabulary.py
│ │ ├── build_msrvtt_vocabulary.py
│ │ ├── make_coco_dataset.py
│ │ ├── make_msrvtt_dataset.py
│ │ ├── preprocess_coco_images.py
│ │ ├── preprocess_coco_objects.py
│ │ ├── preprocess_msrvtt_objects.py
│ │ └── preprocess_msrvtt_videos.py
│ │
│ └── utils <- Assistance classes and modules
│ ├── create_transformer.py <- Create image transformer with torchvision
│ ├── TTS.py <- Amazon Polly wrapper
│ ├── ImageDataloader.py <- Torch dataloader for the COCO dataset
│ ├── VideoDataloader.py <- Torch dataloader for the MSR-VTT dataset
│ └── Vocabulary.py <- Vocabulary class
│
│
└── web <- Scripts/templates related to deploying web app with Flask
Les dépendances peuvent être téléchargées en utilisant:
pip install -r requirements.txt
| Architecture | CNN | Initialisation | Cupide | Poutre = 3 |
|---|---|---|---|---|
| LSTM (intégration: 256) | Resnet152 | Aléatoire | 0,123 | 0,132 |
| Gru (intégration: 256) | Resnet152 | Aléatoire | 0,122 | 0,131 |
| LSTM (intégration: 256) | VGG16 | Aléatoire | 0.108 | 0,117 |
| Architecture | CNN | Initialisation | Cupide | Poutre = 3 |
|---|---|---|---|---|
| Gru (intégration: 256) | Resnet152 | Aléatoire | 0,317 | 0,351 |
| LSTM (intégration: 256) | Resnet152 | Aléatoire | 0,305 | 0,320 |
| LSTM (intégration: 256) | VGG16 | Aléatoire | 0,283 | 0,318 |
| LSTM (intégration: 512) | Resnet152 | Aléatoire | 0,270 | 0,317 |
| LSTM (intégration: 256) | Resnet152 | Coco pré-formé | 0,278 | 0,310 |
Cette section montrera comment on peut former son propre modèle de description d'image.
Premièrement, les images et les légendes de l'ensemble de données CoCo doivent être prétraitées pour la formation.
python3 src/prepare/make_coco_dataset.py
--coco_path <path_to_cocoapi>
--interim_results_path <interim_results_path>
--results_path <final_results_path>
--coco_path: chemin vers le chemin de cocoapi (peut télécharger à partir d'ici)
--interm_results_path: chemin pour stocker les résultats provisoires (par défaut: données / intérimaires /)
--Results_path: chemin pour stocker les résultats finaux (par défaut: données / traitées /)
Cela stocke en outre l'ensemble de données de légendes combinées dans <coco_path> /annotations/coco_captions.csv.
python3 src/prepare/build_coco_vocabulary.py
--coco_path <path_to_cocoapi>
--vocab_path <desired_path_of_vocab>
--threshold <min_word_threshold>
--sets <coco_sets_to_include>
--coco_path: chemin vers le chemin de cocoapi (peut télécharger à partir d'ici)
--vocab_path: chemin pour stocker le vocabulaire coco (par défaut, les données / traitées / coco_vocab.pkl)
--Threshold: Min Word Occurance à ajouter au vocabulaire (par défaut: 5)
- Sets: Coco set à inclure dans la construction du vocabulaire (par défaut: «Train2014», «Train2017»)
python3 src/prepare/preprocess_coco_images.py
--model <base_model_type>
--dir <path_to_images_to_encode>
--continue_preprocessing <continue_preprocessing?>
--model: modèle CNN de base à utiliser pour le prétraitement (options: [«resnet18», «resnet50», «resnet152», «vgg11», «vgg11_bn», «vgg16», «vgg16_bn», «vgg19». «densenet121», «densenet201», «Inception»])
--Dir: chemin vers les images de Coco à coder en utilisant le modèle choisi
--Continue_processing: codez les images restantes dans le répertoire
Les fichiers codés seront placés dans DIR.
python3 src/ic_trainer.py
--models_path <path_to_store_models>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_coco_vocab>
--captions_path <path_to_coco_captions_file>
--images_path <path_to_coco_image_embeddings>
--lr <learning_rate>
--val_interval <epoch_interval_to_validate_models>
--save_interval <epoch_inteval_to_save_model_checkpoints>
--num_epochs <epochs_to_train_for>
--initial_checkpoint_file <starting_model_checkpoint>
--version <model_version_number>
--batch_size <batch_size>
--coco_set <coco_set>
--load_features <load_or_construct_image_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_image_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
--models_path: chemin pour stocker le modèle final (par défaut: modèles /)
--Bream_Size: Taille du faisceau pour la validation (par défaut: 3)
--vocab_path: Chemin vers Coco Vocab (par défaut: données / traitées / coco_vocab.pkl)
--Captions_Path: Path to CoCo Légendes (par défaut: os.environ ['home'] + '/programs/cocoapi/annotations/coco_captions.csv')
--images_path: chemin vers Coco Iamges (par défaut: OS.environ ['Home'] + '/ base de données / Coco / Images /')
- LR: Taux d'apprentissage à utiliser (par défaut: 0,001)
--val_interval: fréquence de l'époque de validation (par défaut: 10)
--Save_Interval: Enregistrer la fréquence de l'époque de point de contrôle (par défaut: 10)
--NUM_EPOCHS: Nombre d'époques pour s'entraîner (par défaut: 1000)
- initial_checkpoint_file: Checkpoint pour démarrer la formation (par défaut: aucun)
--Version: numéro de version du modèle (par défaut: 11)
- Batch_size: Taille du lot (par défaut: 64)
--coco_set: ensemble de données coco pour s'entraîner avec (par défaut: 2014)
--Load_Features: option pour charger ou construire des incorporations d'image (par défaut: true)
--Load_captions: Option pour charger ou construire des légendes intégrées (par défaut: true)
--preload: option pour précharger les données à la mémoire du système avant la formation (par défaut: true)
--base_model: modèle CNN de base à utiliser pour le prétraitement (options: [«resnet18», «resnet50», «resnet152», `` vgg11 '', `` vgg10_bn '', 'vgg16', 'vgg16_bn', 'vgg19', ',' VGG19_BN ',' «densenet121», «densenet201», «Inception»])
--edding_size: taille de l'intégration d'image (par défaut: 2048)
--embed_size: Taille de l'entrée RNN (par défaut: 256)
--HIDDEN_SIZE: Taille de la couche cachée RNN (par défaut: 512)
--rnn_type: type RNN (par défaut: 'lstm')
python3 src/ic_validate.py
--model_path <path_to_trained_ic_model>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_coco_vocab>
--captions_path <path_to_coco_captions_file>
--images_path <path_to_coco_image_embeddings>
--batch_size <batch_size>
--coco_set <coco_set>
--load_features <load_or_construct_image_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_image_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
--model_path: chemin vers le modèle IC formé
--Bream_Size: Taille du faisceau pour la validation
--vocab_path: Chemin vers Coco Vocab (par défaut: données / traitées / coco_vocab.pkl)
--Captions_Path: Path to CoCo Légendes (par défaut: os.environ ['home'] + '/programs/cocoapi/annotations/coco_captions.csv')
--images_path: Path to Coco Images (par défaut: os.environ ['home'] + '/ base de données / coco / images /')
- Batch_size: Taille du lot (par défaut: 64)
--coco_set: ensemble de données coco pour s'entraîner avec (par défaut: 2014)
--Load_Features: option pour charger ou construire des incorporations d'image (par défaut: true)
--Load_captions: Option pour charger ou construire des légendes intégrées (par défaut: true)
--preload: option pour précharger les données à la mémoire du système avant la formation (par défaut: true)
--base_model: modèle CNN de base à utiliser pour le prétraitement (options: [«resnet18», «resnet50», «resnet152», `` vgg11 '', `` vgg10_bn '', 'vgg16', 'vgg16_bn', 'vgg19', ',' VGG19_BN ',' «densenet121», «densenet201», «Inception»])
--edding_size: taille de l'intégration d'image (par défaut: 2048)
--embed_size: Taille de l'entrée RNN (par défaut: 256)
--HIDDEN_SIZE: Taille de la couche cachée RNN (par défaut: 512)
--rnn_type: type RNN (par défaut: 'lstm')
Cette section montrera comment on peut former son propre modèle de description vidéo.
Premièrement, les vidéos et les légendes de l'ensemble de données MSR-VTT doivent être prétraitées pour la formation.
python3 src/prepare/make_msrvtt_dataset.py
--raw_data_path <path_to_raw_msrvtt_data>
--interim_data_path <path_to_store_interim_data>
--final_data_path <path_to_store_final_data>
--continue_converting <continue_conversion>
--train_pct <percentage_to_allocate_to_training_set>
--dev_pct <percentage_to_allocate_to_development_set>
--RAW_DATA_PATH: Chemin vers les fichiers de données MSRVTT bruts (par défaut: 'Données / Raw / VideodatainFO_2017_USTC.JSON')
- Interim_data_path: chemin pour stocker les résultats intérimaires (par défaut: 'data / intérim /')
--Final_data_path: chemin pour stocker les résultats finaux (par défaut: 'Données / traitées /')
--Continue_Converting: Path pour continuer à convertir un ensemble de données MSR-VTT (par défaut: true)
--train_pct: pourcentage de l'ensemble de données à utiliser pour la formation (par défaut: 0,8)
--Dev_pct: pourcentage de l'ensemble de données à utiliser pour le développement (par défaut: 0,15)
python3 src/prepare/build_msrvtt_vocabulary.py
--captions_path <path_to_captions>
--vocab_path <desired_path_of_vocab>
--threshold <min_word_threshold>
--sets <coco_sets_to_include>
--coco_path: Chemin vers les lésions MSR-VTT générées par make_msrvtt_dataset.py (par défaut: 'Données / traitées / msrvtt_captions.csv')
--vocab_path: chemin pour stocker le vocabulaire MSR-VTT (par défaut, les données / traitées / msrvtt_vocab.pkl)
--Threshold: Min Word Occurance à ajouter au vocabulaire (par défaut: 5)
python3 src/prepare/preprocess_msrvtt_videos.py
--model <base_model_type>
--dir <path_to_images_to_encode>
--continue_preprocessing <continue_preprocessing?>
--resolution <CNN_input_resolution>
--num_frames <number_of_frames_to_encode>
--frames_interval <interval_between_frames>
--embedding_size <frame_embedding_size>
--model: modèle CNN de base à utiliser pour le prétraitement (options: [«resnet18», «resnet50», «resnet152», «vgg11», «vgg11_bn», «vgg16», «vgg16_bn», «vgg19». «densenet121», «densenet201», «Inception»])
--DIR: Chemin vers les vidéos MSR-VTT pour coder en utilisant le modèle choisi (par défaut: os.environ ['home'] + '/ base de données / msr-vtt / train-video /')
--Continue_processing: codez des vidéos restantes dans le répertoire (par défaut: true)
- Resolution: Résolution d'entrée CNN (par défaut: 224)
--num_frames: nombre de trames à encoder (par défaut: 40)
--frames_interval: intervalle entre les cadres (par défaut: 1)
--edding_size: Résolution CNN ouput (par défaut: 2048)
Les fichiers codés seront placés dans DIR.
python3 src/vc_trainer.py
--models_path <path_to_store_models>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_msrvtt_vocab>
--captions_path <path_to_msrvtt_captions_file>
--videos_path <path_to_msrvtt_video_embeddings>
--lr <learning_rate>
--val_interval <epoch_interval_to_validate_models>
--save_interval <epoch_inteval_to_save_model_checkpoints>
--num_epochs <epochs_to_train_for>
--initial_checkpoint_file <starting_model_checkpoint>
--version <model_version_number>
--batch_size <batch_size>
--load_features <load_or_construct_video_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_frame_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
--models_path: chemin pour stocker le modèle final (par défaut: modèles /)
--Bream_Size: Taille du faisceau pour la validation (par défaut: 3)
--vocab_path: chemin vers le vocab
--Captions_Path: Chemin vers les légendes MSR-VTT (par défaut: données / traitées / msrvtt_captions.csv)
--videos_path: chemin vers les vidéos MSR-VTT (par défaut: os.environ ['home'] + '/ base de données / msr-vtt / train-video /')
- LR: Taux d'apprentissage à utiliser (par défaut: 0,001)
--val_interval: fréquence de l'époque de validation (par défaut: 10)
--Save_Interval: Enregistrer la fréquence de l'époque de point de contrôle (par défaut: 10)
--NUM_EPOCHS: Nombre d'époques pour s'entraîner (par défaut: 1000)
- initial_checkpoint_file: Checkpoint pour démarrer la formation (par défaut: aucun)
--Version: numéro de version du modèle (par défaut: 11)
- Batch_size: Taille du lot (par défaut: 64)
--load_Features: option pour charger ou construire des incorporations vidéo (par défaut: true)
--Load_captions: Option pour charger ou construire des légendes intégrées (par défaut: true)
--preload: option pour précharger les données à la mémoire du système avant la formation (par défaut: true)
--base_model: modèle CNN de base à utiliser pour le prétraitement (options: [«resnet18», «resnet50», «resnet152», `` vgg11 '', `` vgg10_bn '', 'vgg16', 'vgg16_bn', 'vgg19', ',' VGG19_BN ',' «densenet121», «densenet201», «Inception»])
--edding_size: Taille de l'intégration du cadre (par défaut: 2048)
--embed_size: Taille de l'entrée RNN (par défaut: 256)
--HIDDEN_SIZE: Taille de la couche cachée RNN (par défaut: 512)
--rnn_type: type RNN (par défaut: 'lstm')
python3 src/vc_validate.py
--model_path <path_to_trained_vc_model>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_msrvtt_vocab>
--captions_path <path_to_msrvtt_captions_file>
--videos_path <path_to_msrvtt_video_embeddings>
--batch_size <batch_size>
--load_features <load_or_construct_video_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_frame_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
--model_path: chemin vers la description de la vidéo formée modèle
--Bream_Size: Taille du faisceau pour la validation
--vocab_path: chemin vers le vocab
--Captions_Path: Chemin vers les légendes MSR-VTT (par défaut: données / traitées / msrvtt_captions.csv)
--videos_path: chemin vers les vidéos MSR-VTT (par défaut: os.environ ['home'] + '/ base de données / msr-vtt / train-video /')
- Batch_size: Taille du lot (par défaut: 64)
--load_Features: option pour charger ou construire des incorporations vidéo (par défaut: true)
--Load_captions: Option pour charger ou construire des légendes intégrées (par défaut: true)
--preload: option pour précharger les données à la mémoire du système avant la formation (par défaut: true)
--base_model: modèle CNN de base à utiliser pour le prétraitement (options: [«resnet18», «resnet50», «resnet152», `` vgg11 '', `` vgg10_bn '', 'vgg16', 'vgg16_bn', 'vgg19', ',' VGG19_BN ',' «densenet121», «densenet201», «Inception»])
--edding_size: Taille de l'intégration du cadre (par défaut: 2048)
--embed_size: Taille de l'entrée RNN (par défaut: 256)
--HIDDEN_SIZE: Taille de la couche cachée RNN (par défaut: 512)
--rnn_type: type RNN (par défaut: 'lstm')


